Запуск DBT в Azure Functions с помощью Snowflake

Практики DataOps очень быстро встают на вооружение в компаниях, работающих с данными, особенно в тех, которые переходят на Cloud Data Warehouses (облачные хранилища данных). За прошедшие годы в целях поддержки DataOps произошло слияние нескольких инструментов вроде data build tool (инструмент построения данных) или просто dbt. Придуманный и разработанный компанией Fishtown Analytics, dbt представляет собой инструмент командной строки, выполняющий преобразование данных в ELT-цикле (Extract [извлечение], Load [загрузка], Transform [преобразование]). Некоторые из своих ключевых принципов он заимствует из мира DevOps и разработки ПО. Он также имеет отличный от привычного для многих инженеров подход к построению SQL.
DBT поставляется под лицензией Apache и обычно запускается в конвейерах непрерывной интеграции и развёртывания (CI/CD) либо из dbt Cloud. Последний вариант является версией ПО на их серверах, предлагаемой Fishtown Analytics с тремя тарифными планами. Пакетная обработка рабочих нагрузок, особенно характерная для dbt аналитики, не требует ничего кроме модели выполнения CI/CD.
В последнем проекте, над которым я работал, нам потребовалось использовать dbt в сценарии псевдореального времени. В решении использовалась событийно-ориентированная архитектура со Snowflake в бэкенде и Azure Functions, отвечающими на события. Проблемой было запустить dbt в псевдореальном времени с помощью сообщений, отправляемых в Azure Storage Queue (хранилище очередей Azure) другой Function. Каждое сообщение содержало информацию о преобразованиях данных, которые должны были выполняться сразу после загрузки этих данных. Использование конвейера CI/CD здесь было однозначным, поскольку для пакетного процесса он подходит лучше всего. Итак, нам пришлось разработать Azure Trigger Function (запускающая функция Azure) для запуска dbt. В этой статье я покажу вам, как это сделать, и опишу весь процесс пошагово.
Начнём с основ DBT
Я не инженер по работе с данными, но впервые я решил опробовать работу с dbt год назад просто из чистого любопытства. В тот момент его использовали всего несколько компаний, и существовала всего пара демо-видео от Monzo Bank и Gitlab. Когда я последний раз посещал их ресурс, то видел, что Fishtown Analytics разместили на своей главной странице объявление об инвестиции серии А размером в $12,9 млн рядом с существенно увеличившимся списком компаний, использующих их продукт. Это показывает, насколько быстро подобные инструменты DataOps принимаются индустрией и становятся стандартными средствами. Но что же конкретно он делает?
DBT — это инструмент командной строки, написанный на Python, который использует SQL, а также Jinja-скрипты и макросы для выражения преобразования данных. Он поставляется со встроенными коннекторами к популярным облачным хранилищам вроде Snowflake, Redshift или Google BigQuery. Инженеры по работе с данными разрабатывают код в структурированных проектах, инициализированных командой dbt CLI, и каждый такой проект состоит из каталогов со всеми моделями, макросами, ad-hoc запросами, тестами и прочим. На первый взгляд dbt-проект похож на любой другой проект ПО,

Проекты можно настраивать для работы с разными базами данных и схемами, а также с разными ролями и пользователями. Всё это настраивается в файле profiles.yml, который служит аналогом package.json из мира разработки в Node.js.
Распространённая модель выполнения для dbt — это запуск конвейера Azure Devops или Gitlab, который сначала устанавливает dbt, выполняет некоторые тесты и затем запускает преобразование данных. Командная строка dbt предлагает несколько вариантов вроде выполнения конкретных моделей или группировки моделей при помощи системы тегов. Это позволяет выполнять преобразования конкретных таблиц и представлений, не влияя на остальную часть базы данных. Выбор модели — это полезная функциональная возможность, которую можно применять в ряде случаев использования, например в событийно-ориентированной архитектуре.
Выбор модели и использование тегов
Прежде чем углубляться в выбор модели важно понять, что такое модель. Файлы модели в dbt-проекте являются фундаментальными компонентами, в которых инженеры производят трансформацию данных. Они содержат смесь инструкций SELECT, макросы Jinja и параметры конфигурации. Когда dbt запускает модель, таблицы и представления базы данных либо просто обновляются, либо обновляются инкрементно. Параметры конфигурации определяют тип используемой модели, схему БД, теги и другое. Теги — это полезный механизм для группировки набора моделей. Например, у вас может быть 3 файла моделей, относящихся к заказу Customer (клиента). При помощи одного tag="CUSTOMER' вы можете выполнить преобразования для всех 3-х моделей и обновить 3 разных таблицы, не прибегая к запуску отдельных скриптов или SQL-инструкций.
Ниже приведён пример файла модели, которая выбирает клиентскую информацию из необработанного источника и помещает её в целевую схему и таблицу, определённые в файле профиля.
{{
config(
materialized='incremental',
schema='RAW',
tags='CUSTOMER'
)
}}
with source as (
select * from {{ ref('raw_customers') }}
),
renamed as (
select
id as customer_id,
first_name,
last_name,
email
from source
)
select * from renamedCLI dbt по умолчанию запускает все модели, располагающиеся внутри каталога моделей. Тем не менее можно выбрать конкретную модель или их набор при помощи тегов.
Запуск dbt из командной строки:
# Синтаксис выбора модели DBT
# запускает конкретную модель
dbt --warn-error run --model customer_order
# запускает все модели с тегом customer
dbt --warn-error run --model tag:customerЗапуск DBT при помощи сообщений
Инфраструктура Microsoft Azure поддерживает бессерверные вычисления с различными типами Azure Functions, которые могут быть запущены активируемыми на платформе событиями или сообщениями, а также HTTP-запросами. Полностью автоматизированные конвейеры данных могут использовать эти возможности и реализовываться при помощи событийно-ориентированного подхода. Здесь важно определить отличия между событием и сообщением. Событие — это легковесное уведомление о состоянии или его изменении, а сообщение — это данные, произведённые службой вроде Azure Function.
В событийно-ориентированной архитектуре события активируются, когда данные попадают в облачное хранилище вроде Azure Blob Containers и благодаря подписке на события отправляются в Azure Storage Queue. Azure Function постоянно прослушивает эту очередь и, как только та возвращает событие, запускает новую рабочую нагрузку на основе полученной информации.

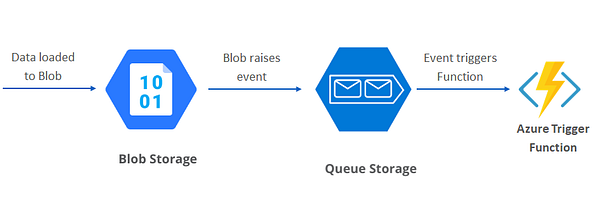
Хранилище очередей Azure — это надёжный механизм для накопления событий и сообщений с последующей отправкой их в Azure Functions. В некоторых случаях может организовываться несколько очередей, позволяющих функциям сообщаться друг с другом.
В нашем примере Azure Function, выполняющая загрузочную часть ELT-конвейера, отправляет сообщение в очередь dbt, которая затем запускает преобразование данных для конкретной модели или тега. Чтобы создать хранилище очередей нужно использовать портал Azure, как показано ниже:

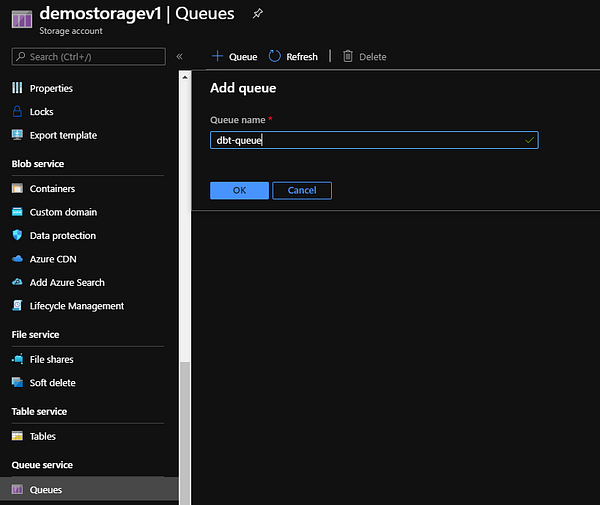
Создание Azure Trigger Function
Как только очередь создана, мы переходим к созданию запускающей функции для хранилища очередей Azure. Делаем мы это при помощи VS Code и расширения Microsoft Azure Functions.

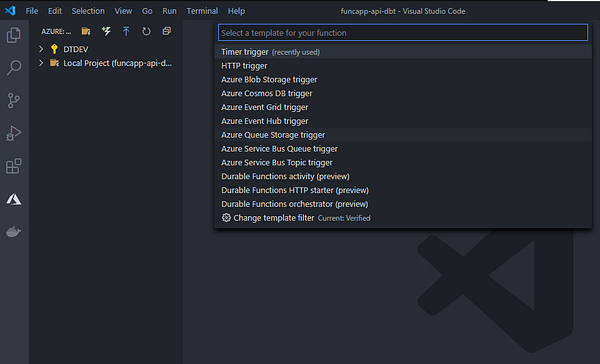
После создания Azure Function мы подключаем её к очереди, которую она будет прослушивать на предмет поступления новых сообщений. В этот момент в проекте уже должна быть функция main, обрабатывающая входящие события, и файл function.json, содержащий привязки запуска, как показано ниже:

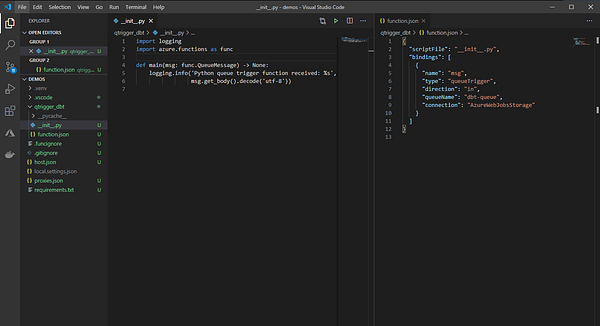
Добавление DBT-проекта в Azure Function
Как правило, команды отделяют репозитории для своих dbt-проектов. Здесь нужно добиться того, чтобы dbt-модели запускались внутри созданной нами Azure Function. Один из вариантов— добавить dbt-проект в проект Azure Function в качестве git submodule. Таким образом любые изменения, производимые командой инженеров по работе с данными в dbt-проекте, будут синхронизированы, а все модели, выполняющиеся в функции, будут обновлены. Здесь я использую проект jaffle_shop — демо репозиторий, созданный Fishtown Analytics.

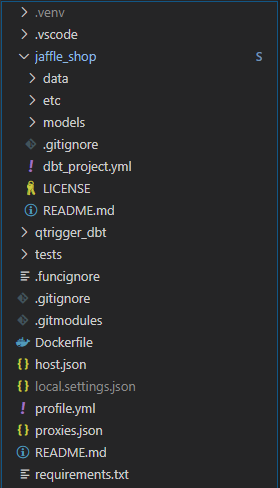
В данной ситуации для dbt нет API Python, поэтому наиболее надёжным способом его запуска будет создание обёртки subprocess Popen. Для этого нужен только простой класс Runner с методом, принимающим в качестве параметров используемые модели и теги. Ниже приведён фрагмент класса DBTRunner и метод exec_dbt, использующий профиль выполнения profiles.yml, расположенный в корне проекта. Остальную часть кода для Function вы можете найти здесь.
import os
import re
import logging
from subprocess import PIPE, Popen
class DBTRunner():
#
# Место для кода инициализации
#
def exec_dbt(self, args=None):
if args is None:
args = ["run"]
final_args = ['dbt']
final_args.append('--single-threaded')
final_args.extend(args)
final_args.extend(['--profiles-dir', "../."])
log_lines = []
with Popen(final_args, stdout=PIPE) as proc:
for line in proc.stdout:
line = line.decode('utf-8').replace('
', '').strip()
line = self.ansi_escape.sub('', line)
log_lines.append(line)
self.logger.info(line)Файлы профиля содержат информацию о подключении к БД и схему, которая будет использоваться при запуске dbt. Все эти параметры могут быть переданы в виде переменных среды и определены скрытым образом. Файл profiles.yml с параметрами целевой БД:
jaffle:
outputs:
dev:
# указание данных для подключения к snowflake
type: snowflake
threads: 1
account: "{{ env_var('DBT_ACCOUNT') }}"
user: "{{ env_var('DBT_USER') }}"
password: "{{ env_var('DBT_PASSWORD') }}"
role: "{{ env_var('DBT_ROLE') }}"
database: "{{ env_var('DBT_DB') }}"
warehouse: "{{ env_var('DBT_WAREHOUSE') }}"
schema: "{{ env_var('DBT_SCHEMA') }}"
target: devКаждая Azure Function содержит установки приложения, передаваемые в качестве переменных среды в наш код и в итоге заменяющие переменные, приведённые выше. Теперь функция запуска готова к обработке входящих сообщений и запуску dbt-моделей.
Настройка развёртывания Azure Function
При запуске dbt генерирует протоколируемую информацию и компилирует код в целевой SQL, который будет выполняться в Snowflake или любой другой выбранной базе данных. В связи с этим при запуске в среде контейнера вроде Azure Function возникают сложности из-за проблем с разрешением, в связи с чем выполнение моделей блокируется, а в журнале логируются ошибки.
DBT-проекты содержат файл dbt_project.yml, в котором находятся определения для всех необходимых путей. Перед настройкой развёртывания важно настроить эти пути, используя каталоги temp на нашем хост-сервере Linux. Упомянутый файл должен выглядеть аналогично YAML, приведённому ниже, а все пути должны указывать на каталог temp в Linux.
DBT-проект с временными каталогами:
# Имена проектов должны содержать только буквы в нижнем регистре и
# подчёркивания.
# Грамотное имя пакета должно отражать имя вашей организации или
# предполагаемое использование моделей.
name: 'jaffle_shop'
version: '0.0.1'
# Эта установка настраивает "profile", который dbt использует для этого проекта.
profile: 'jaffle'
# Эти настройки определяют, где dbt должен искать разные типы
# файлов.
# Например, конфигурация `source-paths` утверждает, что модели в
# этом проекте можно найти в директории "models/". Скорее всего, этот #параметр вам менять не придётся.
source-paths: ["models"]
analysis-paths: ["analysis"]
test-paths: ["tests"]
data-paths: ["data"]
macro-paths: ["macros"]
log-path: '/tmp/dbt_log/'
target-path: "/tmp/dbt_target/" # директории, которые будут хранить # скомпилированные SQL-файлы.
modules-path: "/tmp/dbt_modules/"
clean-targets: # директории, удаляемые командой `dbt clean`.
- "/tmp/dbt_target/"
- "/tmp/dbt_modules/"
- "/tmp/dbt_log/"
models:
materialized: view
jaffle_shop:
pre-hook: " alter session set TIMEZONE = 'GMT'"Теперь все компоненты на своих местах, и мы готовы к созданию конвейера сборки Azure DevOps. Конвейер произведёт установку dbt и других библиотек, как определено в файле requirements.txt, создаст образ Docker и передаст его в наш реестр посредством подключения Azure DevOps svc-demo-docker-reg.
Конвейер сборки Azure DevOps для Azure-функции, запускающей dbt:
# Python-конвейер сборки, тестирования и публикации
#
#
# Добавьте шаги для сборки, выполнения тестов, развёртывания и
# прочего:
# https://aka.ms/yaml
# Переменные уровня конвейера
variables:
workingDirectory: '$(System.DefaultWorkingDirectory)'
trigger:
- master
jobs:
- job: Build
pool:
vmImage: 'ubuntu-latest'
steps:
- task: [email protected]
displayName: "Use Python version 3.7"
inputs:
versionSpec: '3.7'
architecture: 'x64'
- checkout: self # self представляет репозиторий, где обнаруживается изначальный YAML-файл конвейеров Azure
displayName: 'Checkout'
submodules: true
- bash: pip install -r $(workingDirectory)/requirements.txt
displayName: 'Install Requirements'
workingDirectory: $(workingDirectory)
- task: [email protected]
displayName: Build and push the new image
inputs:
command: buildAndPush
repository: 'funcapp-dbt-trigger'
dockerfile: 'Dockerfile'
containerRegistry: 'svc-demo-docker-reg'
tags: |
$(Build.BuildId)Заключительный шаг
Прежде чем развёртывать Azure Function, нам нужно создать приложение Function, которое послужит хостом для нескольких Azure Function и будет расположено внутри определённой группы ресурсов и географической области. Мы просто выбираем подписку, группу ресурсов, имя и область, а также указываем тип развёртывания как Docker Container. Docker Container мы выбрали, поскольку на наш взгляд это наиболее надёжный метод установки и запуска dbt в Function.

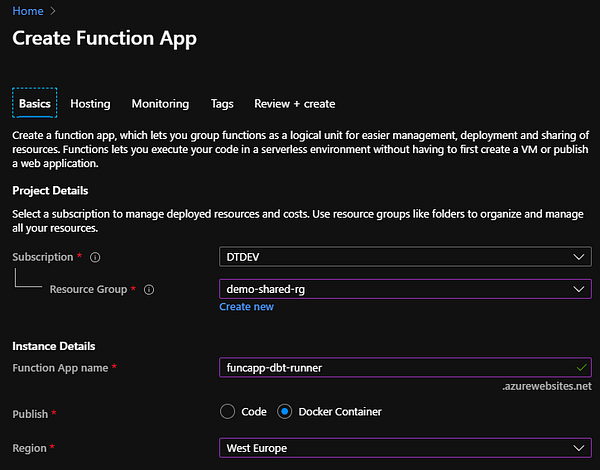
Как только приложение Function подготовлено, мы настраиваем конвейер выпуска Azure DevOps на развёртывание созданного прежде образа Docker. Ниже вы можете видеть обзор конвейера выпуска и выполнения основной работы с подключенной задачей развёртывания службы приложений (App Service Deploy Task).

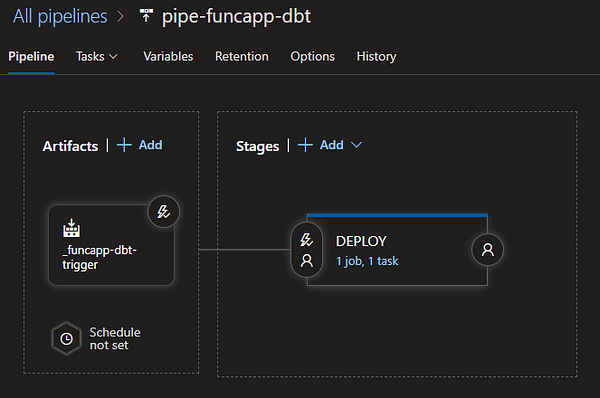

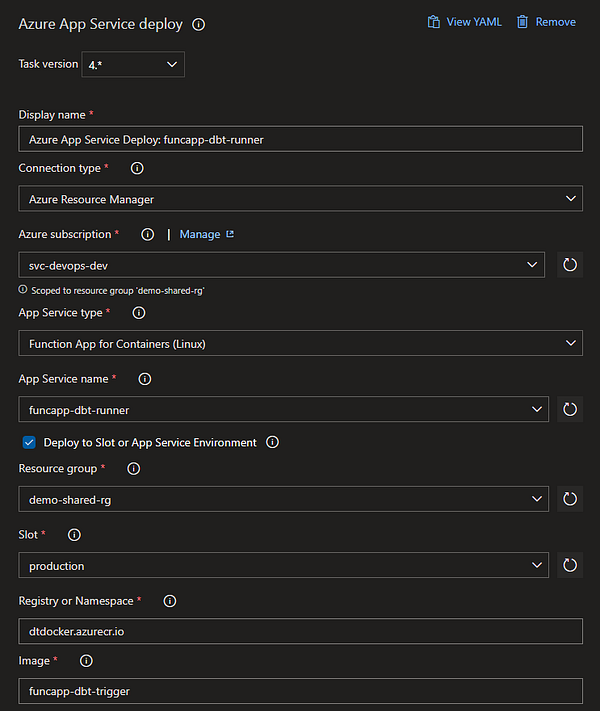
Теперь, когда наша Azure Function развёрнута и запущена, настало время выполнения тестов. Проект jaffle_shop содержит некоторые пустые данные и модели, представляющие клиентов и заказы в вымышленном онлайн-магазине. Предположим, что другая Azure Function выполнила загрузку всех данных и теперь отправляет сообщение для обновления заказов клиентов с определёнными преобразованиями. Мы симулируем этот процесс, добавив сообщение в dbt-queue.

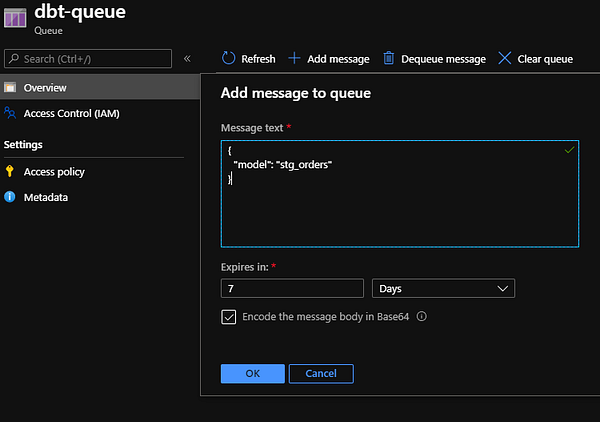
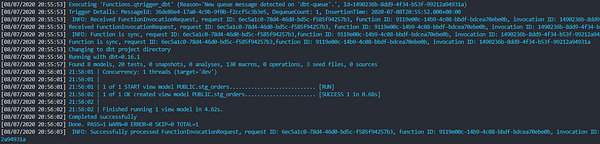
Как только сообщение добавлено, наша Function запускается и dbt начинает выполнение. Он выбирает модель stg_orders и успешно запускает все преобразования. Надо признать, что это очень простой пример, но настройка работает и для больших проектов, т.е. может быть с лёгкостью расширена.

Заключение
DBT — это мощный инструмент, который без проблем преобразует данные нужным для вашей команды образом. Освоение же этого инструмента потребует времени и терпения, особенно для команд, не привыкших к практикам DataOps. Присоединение dbt к Azure Function и выполнение моделей на основе поступающих событий — это очень производительный механизм, который можно использовать во множестве интересных сценариев.
Comments