Оптимизация кода задачи на миллиард строк — ускоряем запуск в 87 раз

Задача на миллиард строк изначально была для разработчиков Java. Цель — разработать и оптимизировать синтаксический анализатор для файла с миллиардом записей.
Эта задача — отличная возможность продемонстрировать оптимизацию кода C++ инструментами повышения производительности.
Задача
Входные данные — файл measurements.txt с измерениями температуры из различных метеостанций, в нем ровно миллиард строк в таком формате:
station name;value
station name;value
Название станции — строка в UTF-8 максимальной длиной 100 байт из любых одно- или двухбайтовых символов, кроме ; или –99.9 до 99.9, у всех один знак после запятой. Общее количество уникальных станций — 10 000.
Выходные данные в stdout — это лексикографически сортируемый список станций с минимальной, средней и максимальной измеренными температурами в каждой.
{Abha=-23.0/18.0/59.2, Abidjan=-16.2/26.0/67.3, Abéché=-10.0/29.4/69.0, ...}Базовая реализация
Программа базовой реализации двухэтапная: обработка входных и форматирование выходных данных.
На первом этапе название станции и измеренное значение парсятся и сохраняются в std::unordered_map:
struct Record {
uint64_t cnt;
double sum;
float min;
float max;
};
using DB = std::unordered_map<std::string, Record>;
DB process_input(std::istream &in) {
DB db;
std::string station;
std::string value;
// Берем из входных данных станцию и измеренное значение
while (std::getline(in, station, ';') &&
std::getline(in, value, '
')) {
// Преобразуем измеренное значение в значение с плавающей запятой
float fp_value = std::stof(value);
// Выполняем поиск станции в базе данных
auto it = db.find(station);
if (it == db.end()) {
// Если ее там нет, вставляем
db.emplace(station,
Record{1, fp_value, fp_value, fp_value});
continue;
}
// В противном случае обновляем информацию
it->second.min = std::min(it->second.min, fp_value);
it->second.max = std::max(it->second.max, fp_value);
it->second.sum += fp_value;
++it->second.cnt;
}
return db;
}Для получения выходных данных уникальные названия сопоставляем, лексикографически сортируем, затем выводим минимальные, средние и максимальные значения измерений:
void format_output(std::ostream &out, const DB &db) {
std::vector<std::string> names(db.size());
// Берем все уникальные названия станций
std::ranges::copy(db | std::views::keys, names.begin());
// Лексикографическая сортировка строк UTF-8 — то же,
// что сортировка по значению элемента кодового пространства
std::ranges::sort(names);
std::string delim = "";
out << std::setiosflags(out.fixed | out.showpoint)
<< std::setprecision(1);
out << "{";
for (auto &k : names) {
// Выводим «StationName:min/avg/max»
auto &[_, record] = *db.find(k);
out << std::exchange(delim, ", ") << k << "="
<< record.min << "/" << (record.sum / record.cnt)
<< "/" << record.max;
}
out << "}
";
}Осталась функция main, в которой обе части соединяются:
int main() {
std::ifstream ifile("measurements.txt", ifile.in);
if (not ifile.is_open())
throw std::runtime_error("Failed to open the input file.");
auto db = process_input(ifile);
format_output(std::cout, db);
}Эта базовая реализация очень простая, но с двумя серьезными проблемами: она некорректная и невероятно медленная. Первую пока игнорируем, а производительность представим на трех машинах:
- Intel 9700K на Fedora 39,
- Intel 14900K в подсистеме Windows для Linux Ubuntu,
- Mac Mini M1 8-ядерный.
Мы говорим об относительном росте производительности, поэтому измерения — это просто быстрейшее выполнение на соответствующей машине:
- 9700K на Fedora 39: 132 сек.,
- 14900K на WSL для Ubuntu: 67 сек.,
- Mac Mini M1: 113 сек.
Устранение копий
Для первой замены не нужно специального инструментария. Самое важное правило для высокопроизводительного кода — избегать лишних копий. А их у нас немало.
При обработке одной строки — не забываем, что всего их миллиард — название станции и измеренное значение считываются в std::string. Этим фактически создается явная копия данных, потому что при считывании файла его содержимое уже находится в буферной памяти.
Проблема устраняется переходом на безбуферное считывание, обработкой буфера для istream вручную или применением скорее подхода уровня системы, в частности отображения файла в памяти. Пойдем по третьему пути.
Когда файл отображается в память, операционной системой для его содержимого выделяется адресное пространство, но данные считываются в память только при необходимости. Преимущество этого подхода — возможность рассмотрения всего файла как массива, недостаток — потеря контроля над тем, какие части файла в тот или иной момент доступны в памяти, в расчете на правильность принимаемых операционной системой решений.
Работая с C++, обернем низкоуровневую системную логику в объекты RAII:
// Вспомогательный «MoveOnly»
template <typename T, T empty = T{}> struct MoveOnly {
MoveOnly() : store_(empty) {}
MoveOnly(T value) : store_(value) {}
MoveOnly(MoveOnly &&other)
: store_(std::exchange(other.store_, empty)) {}
MoveOnly &operator=(MoveOnly &&other) {
store_ = std::exchange(other.store_, empty);
return *this;
}
operator T() const { return store_; }
T get() const { return store_; }
private:
T store_;
};
struct FileFD {
FileFD(const std::filesystem::path &file_path)
: fd_(open(file_path.c_str(), O_RDONLY)) {
if (fd_ == -1)
throw std::system_error(errno, std::system_category(),
"Failed to open file");
}
~FileFD() {
if (fd_ >= 0)
close(fd_);
}
int get() const { return fd_.get(); }
private:
MoveOnly<int, -1> fd_;
};
struct MappedFile {
MappedFile(const std::filesystem::path &file_path)
: fd_(file_path) {
// Определяем размер файла для отображения в память
struct stat sb;
if (fstat(fd_.get(), &sb) == 1)
throw std::system_error(errno, std::system_category(),
"Failed to read file stats");
sz_ = sb.st_size;
begin_ = static_cast<char *>(
mmap(NULL, sz_, PROT_READ, MAP_PRIVATE, fd_.get(), 0));
if (begin_ == MAP_FAILED)
throw std::system_error(errno, std::system_category(),
"Failed to map file to memory");
}
~MappedFile() {
if (begin_ != nullptr)
munmap(begin_, sz_);
}
// Содержимое всего файла в виде «std::span»
std::span<const char> data() const {
return {begin_.get(), sz_.get()};
}
private:
FileFD fd_;
MoveOnly<char *> begin_;
MoveOnly<size_t> sz_;
};
Отображаемый в память файл оборачивается в std::span, поэтому сохранение работоспособности всего этого проверяется простой заменой std::ifstream на std::ispanstream:
int main() {
MappedFile mfile("measurements.txt");
std::ispanstream ifile(mfile.data());
auto db = process_input(ifile);
format_output(std::cout, db);
}Чтобы удалить лишние копии, переключаем обработку входных данных с работы поверх istream на обращение с ними как с одной большой строкой в стиле Си:
DB process_input(std::span<const char> data) {
DB db;
auto iter = data.begin();
while (iter != data.end()) {
// Выполняем поиск конца названия станции
auto semi_col = std::ranges::find(
iter, std::unreachable_sentinel, ';');
auto station = std::string_view(iter, semi_col);
iter = semi_col + 1;
// Выполняем поиск конца измеренного значения
auto new_line = std::ranges::find(
iter, std::unreachable_sentinel, '
');
// Выполняем парсинг как значения с плавающей точкой
float fp_value;
std::from_chars(iter.base(), new_line.base(), fp_value);
iter = new_line + 1;
// Выполняем поиск станции в базе данных
auto it = db.find(station);
if (it == db.end()) {
// Если ее там нет, вставляем
db.emplace(station,
Record{1, fp_value, fp_value, fp_value});
continue;
}
// В противном случае обновляем информацию
it->second.min = std::min(it->second.min, fp_value);
it->second.max = std::max(it->second.max, fp_value);
it->second.sum += fp_value;
++it->second.cnt;
}
return db;
}Поиск станций выполняется теперь с std::string_view, поэтому для поддержки разнородных поисков меняем в хеш-карте компаратор и добавляем пользовательский хешер:
struct StringHash {
using is_transparent = void;
size_t operator()(std::string_view txt) const {
return std::hash<std::string_view>{}(txt);
}
size_t operator()(const std::string &txt) const {
return std::hash<std::string>{}(txt);
}
};
using DB = std::unordered_map<std::string, Record,
StringHash, std::equal_to<>>;Так наше решение сильно ускоряется, M1 пока пропускаем, поскольку std::from_chars для типов с плавающей запятой в clang 15 не поддерживается:
- 9700K на Fedora 39: 47,6 сек.,
- 14900K на WSL для Ubuntu: 29,4 сек.
Анализ ситуации
Продолжая оптимизировать решение, определим основные его узкие места. Воспользуемся профилировщиком Linux perf: при приемлемой точности у него очень низкие накладные расходы.
Добавим в двоичный файл немного отладочной информации:
-fno-omit-frame-pointer # указатель фрейма не опускаем
-ggdb3 # подробная отладочная информация
Записываем профиль, запуская двоичный файл в инструменте perf:
perf record --call-graph dwarf -F999 ./binary
В perf параметром callgraph с помощью отладочной информации, сохраняемой в двоичном файле, низкоуровневые функции привязываются к корректному источнику вызова. Вторым параметром в perf уменьшается частота захвата выборок. Если она слишком высокая, выборки теряются.
Просматриваем профиль так:
perf report -g 'graph,caller'
Запустив perf в текущей реализации, получим не особо информативный профиль:
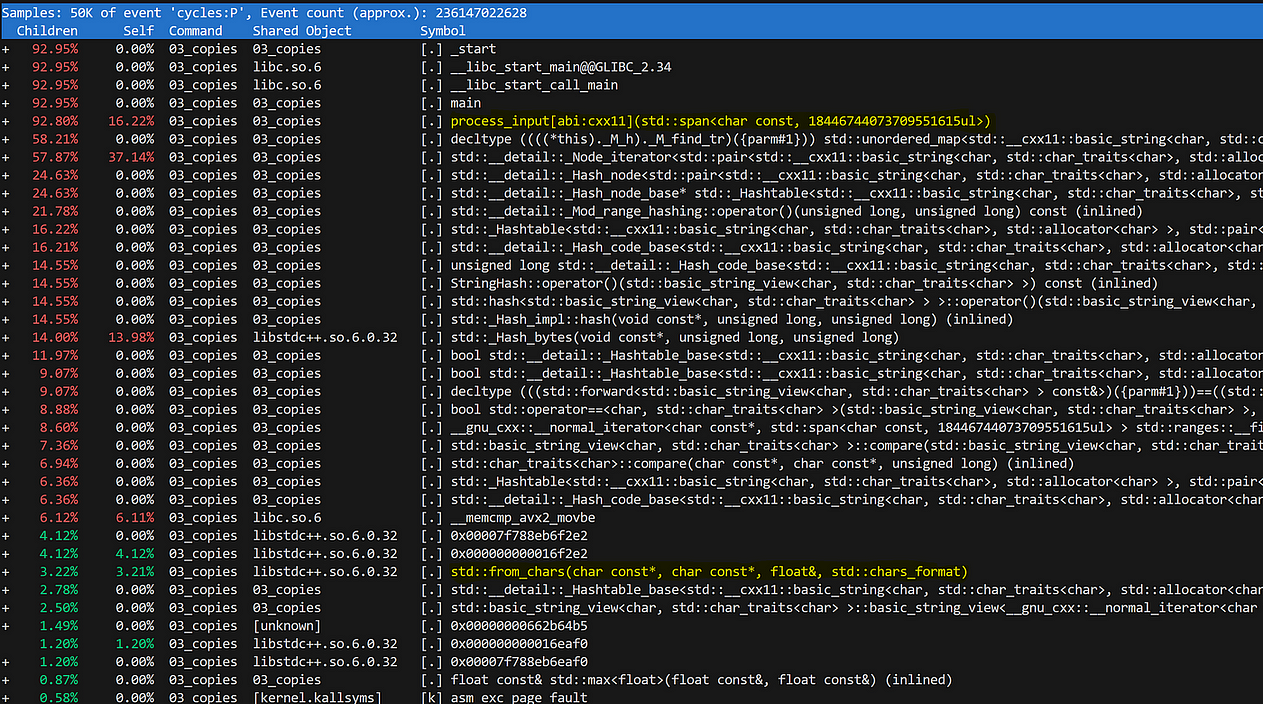
Видно, что большая часть времени выполнения расходуется в std::unordered_map. Но остальные операции теряются в низкоуровневых функциях. Например, на парсинг измеренных значений — функция std::from_chars — тратится всего 3 %, это наблюдение некорректно.
Профиль плохой, потому что всю логику поместили в один сплошной цикл. Для производительности это хорошо, но полностью теряется смысл реализуемых логических операций:
- парсинг названия станции;
- парсинг измеренного значения;
- сохранение данных в базе данных.
Оборачиваем эти логические операции в отдельные функции, и профиль резко преображается:
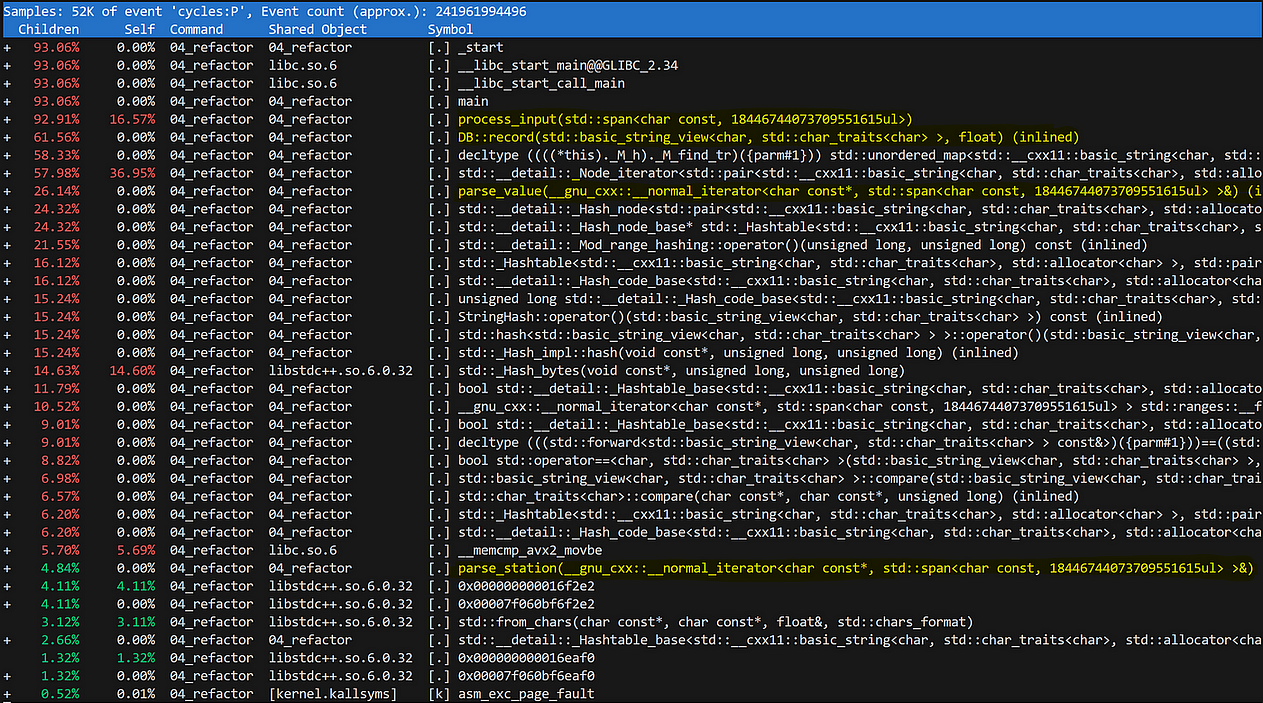
Теперь 62 % времени расходуется на вставку данных в БД, 26 % — на парсинг измеренных значений и 5 % — на парсинг названий станций.
Прежде чем переходить к хеш-карте, разберемся с парсингом значений и заодно устраним постоянный баг в коде — некорректное округление.
Скрытые целые числа
Во входных данных содержатся значения от –99,9 до 99,9, всегда с одним знаком после запятой. То есть измеренные значения — это числа не с плавающей, а с фиксированной запятой.
Представлять значения с фиксированной запятой корректно целым числом, которое парсится вручную — пока что простым способом:
int16_t parse_value(std::span<const char>::iterator &iter) {
bool negative = (*iter == '-');
if (negative)
++iter;
int16_t result = 0;
while (*iter != '
') {
if (*iter != '.') {
result *= 10;
result += *iter - '0';
}
++iter;
}
if (negative)
result *= -1;
++iter;
return result;
}Это изменение распространяется и на структуру записи:
struct Record {
int64_t cnt;
int64_t sum;
int16_t min;
int16_t max;
};Вставка в базу данных остается прежней, но код слегка оптимизируется:
void record(std::string_view station, int16_t value) {
// Выполняем поиск станции в базе данных
auto it = this->find(station);
if (it == this->end()) {
// Если ее там нет, вставляем
this->emplace(station, Record{1, value, value, value});
return;
}
// Переключаем минимум и максимум на исключающие ветки
if (value < it->second.min)
it->second.min = value;
else if (value > it->second.max)
it->second.max = value;
it->second.sum += value;
++it->second.cnt;
}Изменим код форматирования выходных данных. Так как мы теперь оперируем числами с фиксированной запятой, корректно преобразовываем сохраненные целочисленные значения обратно в значения с плавающей запятой и округляем:
void format_output(std::ostream &out, const DB &db) {
std::vector<std::string> names(db.size());
// Берем все уникальные названия станций
std::ranges::copy(db | std::views::keys, names.begin());
// Лексикографическая сортировка строк UTF-8 — то же,
// что сортировка по значению элемента кодового пространства
std::ranges::sort(names, std::less<>{});
std::string delim = "";
out << std::setiosflags(out.fixed | out.showpoint)
<< std::setprecision(1);
out << "{";
for (auto &k : names) {
// Выводим «StationName:min/avg/max»
auto &[_, record] = *db.find(k);
int64_t sum = record.sum;
// Корректное округление
if (sum > 0)
sum += record.cnt / 2;
else
sum -= record.cnt / 2;
out << std::exchange(delim, ", ") << k << "="
<< record.min / 10.0 << "/"
<< (sum / record.cnt) / 10.0 << "/"
<< record.max / 10.0;
}
out << "}
";
}Этим изменением устраняется баг округления, за счет ускорения подсчета значений с плавающей запятой совершенствуется время выполнения, с M1 Mac реализация совместима:
- 9700K на Fedora 39: 35,5 сек., в 3,7 раза быстрее,
- 14900K на WSL для Ubuntu: 23,7 сек., в 2,8 раза быстрее,
- Mac Mini M1: 55,7 сек., в 2 раза быстрее.
Пользовательская хеш-карта
std::unordered_map из стандартной библиотеки славится медлительностью из-за используемой в нем структуры узлов — фактически это массив связных списков узлов. Перейти с помощью Abseil или Boost на плоский ассоциативный массив — значит нарушить исходный замысел задачи на миллиард строк, в которой внешние библиотеки запрещаются.
А главное — входные данные очень ограничены. На миллиард записей приходится не более 10 000 уникальных ключей, что чревато очень высоким коэффициентом совпадений.
Из-за этого ограничения воспользуемся хеш-картой линейного зондирования на основе 16-битного хеша, где напрямую индексируется массив статически объявляемого размера. При возникновении коллизии — это когда две разные станции отображаются на один хеш/индекс — ищется следующий доступный слот.
То есть в худшем случае — когда на один хеш/индекс отображаются все станции — получается поиск с линейной сложностью. Но это крайне маловероятно, для примера входных данных с std::hash оказывается 5 млн коллизий, то есть 0,5 %:
struct DB {
DB() : keys_{}, values_{}, filled_{} {}
void record(std::string_view station, int16_t value) {
// Находим слот для этой станции
size_t slot = lookup_slot(station);
// Если он пустой, у нас промах
if (keys_[slot].empty()) {
filled_.push_back(slot);
keys_[slot] = station;
values_[slot] = Record{1, value, value, value};
return;
}
// В противном случае — попадание
if (value < values_[slot].min)
values_[slot].min = value;
else if (value > values_[slot].max)
values_[slot].max = value;
values_[slot].sum += value;
++values_[slot].cnt;
}
size_t lookup_slot(std::string_view station) const {
// Получаем хеш названия, усеченного до 16 бит
uint16_t slot = std::hash<std::string_view>{}(station);
// Хотя слот уже занят
while (not keys_[slot].empty()) {
// Если название то же, имеется попадание
if (keys_[slot] == station)
break;
// В противном случае — коллизия
++slot;
}
// Либо первый пустой слот, либо попадание
return slot;
}
// Вспомогательный метод для форматирования выходных данных
void sort_slots() {
auto cmp = [this](size_t left, size_t right) {
return keys_[left] < keys_[right];
};
std::ranges::sort(filled_.begin(), filled_.end(), cmp);
}
// Ключи
std::array<std::string, UINT16_MAX+1> keys_;
// Значения
std::array<Record, UINT16_MAX+1> values_;
// Запись использованных индексов для выходных данных
std::vector<size_t> filled_;
};В результате этого изменения получаем существенное ускорение:
- 9700K (Fedora 39): 25,6 сек., в 5,1 раза быстрее,
- 14900K на WSL для Ubuntu: 18,4 сек., в 3,6 раза быстрее,
- Mac Mini M1: 49,4 сек., в 2,3 раза быстрее.
Микрооптимизации
С высокоуровневыми возможностями оптимизации разобрались, переходим к микрооптимизации критически важных частей кода.
Посмотрим на текущую ситуацию:
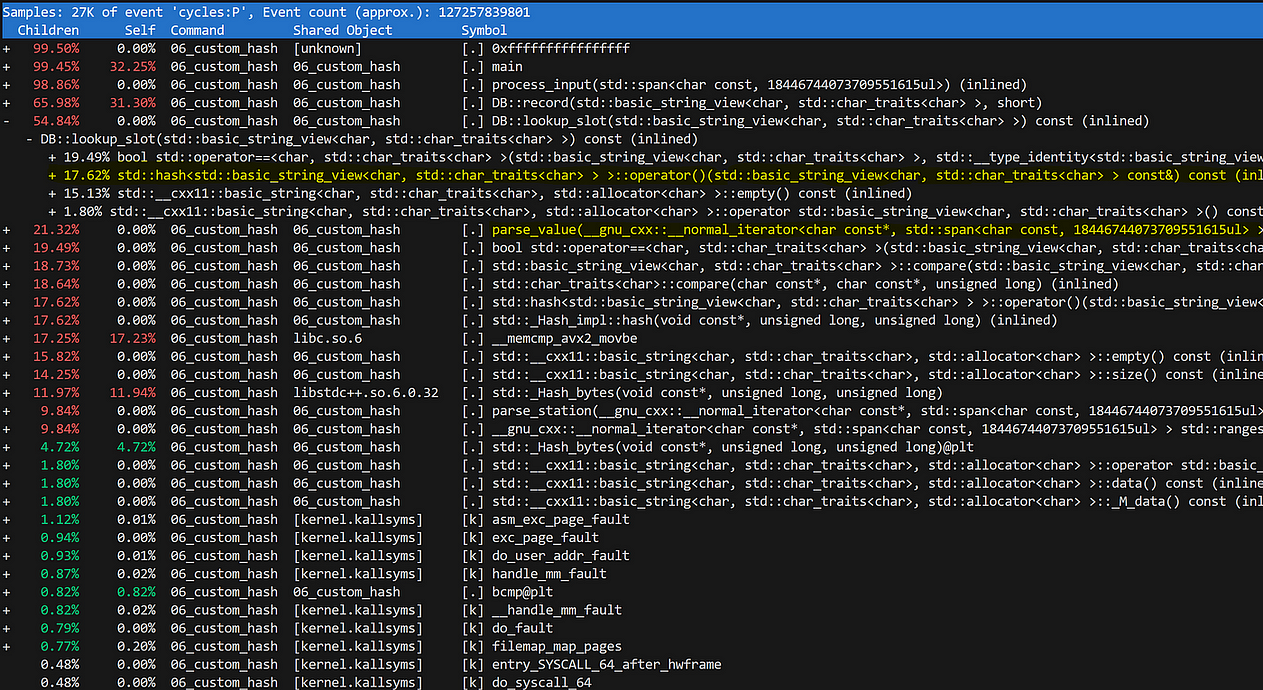
На низкоуровневые оптимизации напрашиваются хеширование — 17 % и парсинг целых чисел — 21 %.
Корректный инструмент микрооптимизаций — фреймворк тестирования, например Google Benchmark. Реализуем несколько версий целевой функции и сравним результаты.
Парсинг целых чисел
Текущая версия парсинга целых чисел намеренно написана плохо, с избыточными ветвлениями.
Корректное применение широких AVX-инструкций невозможно из-за коротких значений — всего в три символа. Остается единственный подход для устранения ветвлений — таблица поиска.
При парсинге числа возможны лишь две ситуации, знак игнорируется.
- Появление цифры: аккумулятор умножается на 10, значение цифры добавляется.
- Непоявление цифры: аккумулятор умножается на 1, добавляется 0.
Кодируем это как двумерный, генерируемый во время компиляции массив с информацией для всех 256 значений типа char:
consteval auto int_parse_table() {
std::array<std::array<int16_t, 2>, 256> data;
for (size_t c = 0; c < 256; ++c) {
if (c >= '0' && c <= '9') {
data[c][0] = c - '0';
data[c][1] = 10;
} else {
data[c][0] = 0;
data[c][1] = 1;
}
}
return data;
}
static constexpr auto params = int_parse_table();
int16_t parse_int_table(const char *&iter) {
char sign = *iter;
int16_t result = 0;
while (*iter != '
') {
result *= params[*iter][1];
result += params[*iter][0];
++iter;
}
++iter;
if (sign == '-')
return result * -1;
return result;
}Подключим эти две версии к микротестированию Google Benchmark и получим очень важный результат:
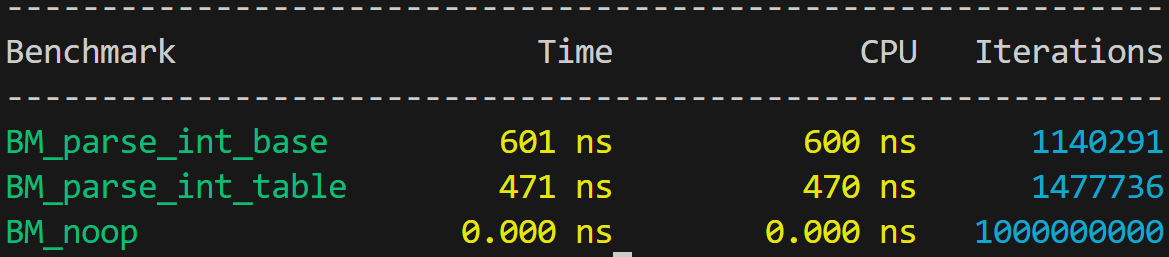
Но сходу сделать это не получится, ведь реализация — это сплошной цикл по максимум пяти символам, поэтому она невероятно чувствительна к компоновке. Выровняем функции флагом LLVM:
-mllvm -align-all-functions=5
Но и так результаты сильно колеблются, до 40 %:
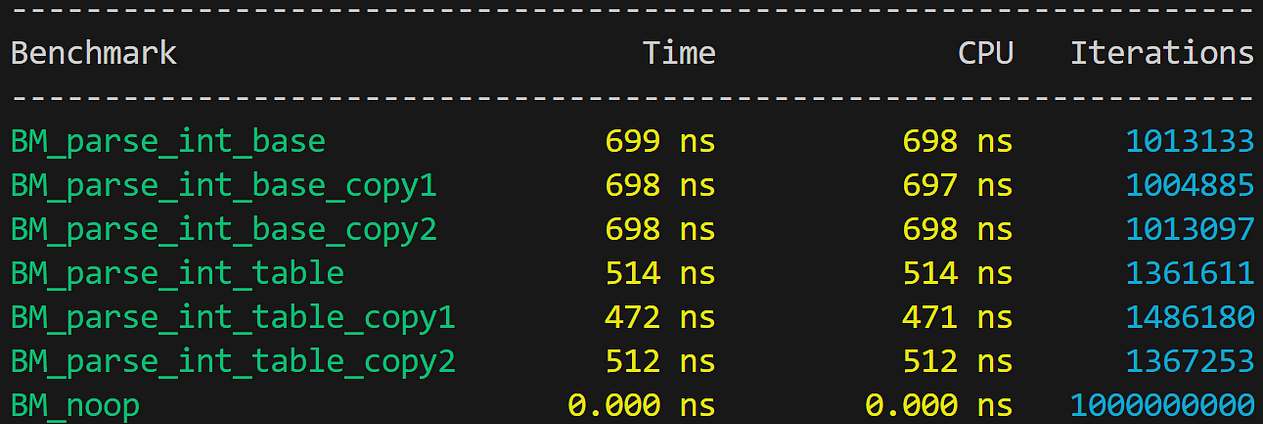
Хеширование
Что касается хеширования, имеется две возможности оптимизации.
Сейчас сначала парсится название станции, затем внутри lookup_slot вычисляется хеш. То есть данные проходятся дважды.
А еще вычисляется 64-битный хеш, хотя нужен только 16-битный.
Чтобы смягчить последствия проблем при парсинге целых чисел, проводим его в один этап, создавая string_view названия станции, 16-битный хеш и измеренное значение с фиксированной запятой:
struct Measurement {
std::string_view name;
uint16_t hash;
int16_t value;
};
Measurement parse_v1(std::span<const char>::iterator &iter) {
Measurement result;
auto end = std::ranges::find(iter, std::unreachable_sentinel, ';');
result.name = {iter.base(), end.base()};
result.hash = std::hash<std::string_view>{}(result.name);
iter = end + 1;
result.value = parse_int_table(iter);
return result;
}Пользовательский 16-битный хеш вычисляем простой формулой с беззнаковым переполнением вместо модуля:
struct Measurement {
std::string_view name;
uint16_t hash;
int16_t value;
};
Measurement parse_v2(std::span<const char>::iterator &iter) {
Measurement result;
const char *begin = iter.base();
result.hash = 0;
while (*iter != ';') {
result.hash = result.hash * 7 + *iter;
++iter;
}
result.name = {begin, iter.base()};
++iter;
result.value = parse_int_table(iter);
return result;
}Фиксируем неплохое ускорение с приемлемой стабильностью:
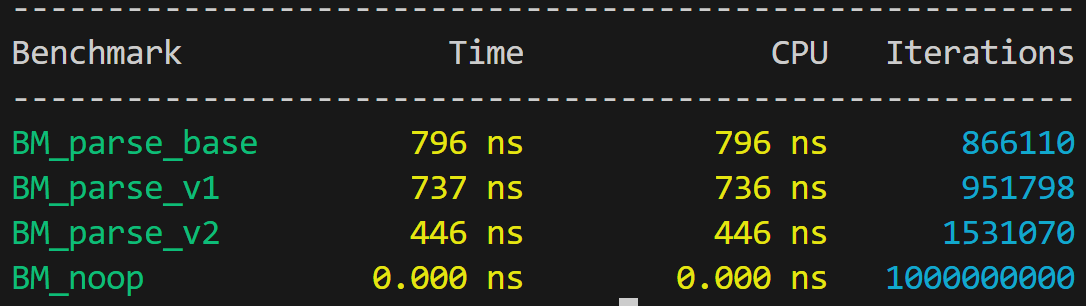
Включив его в наше решение, получаем общее ускорение:
- 9700K на Fedora 39: 19,2 сек., в 6,87 раза быстрее,
- 14900K на WSL для Ubuntu: 14,1 сек., в 4,75 раза быстрее с шумом,
- Mac Mini M1: 46,2 сек., в 2,44 раза быстрее.
Применение потоков
Снова просматриваем профиль и обнаруживаем, что достигли предела возможного:
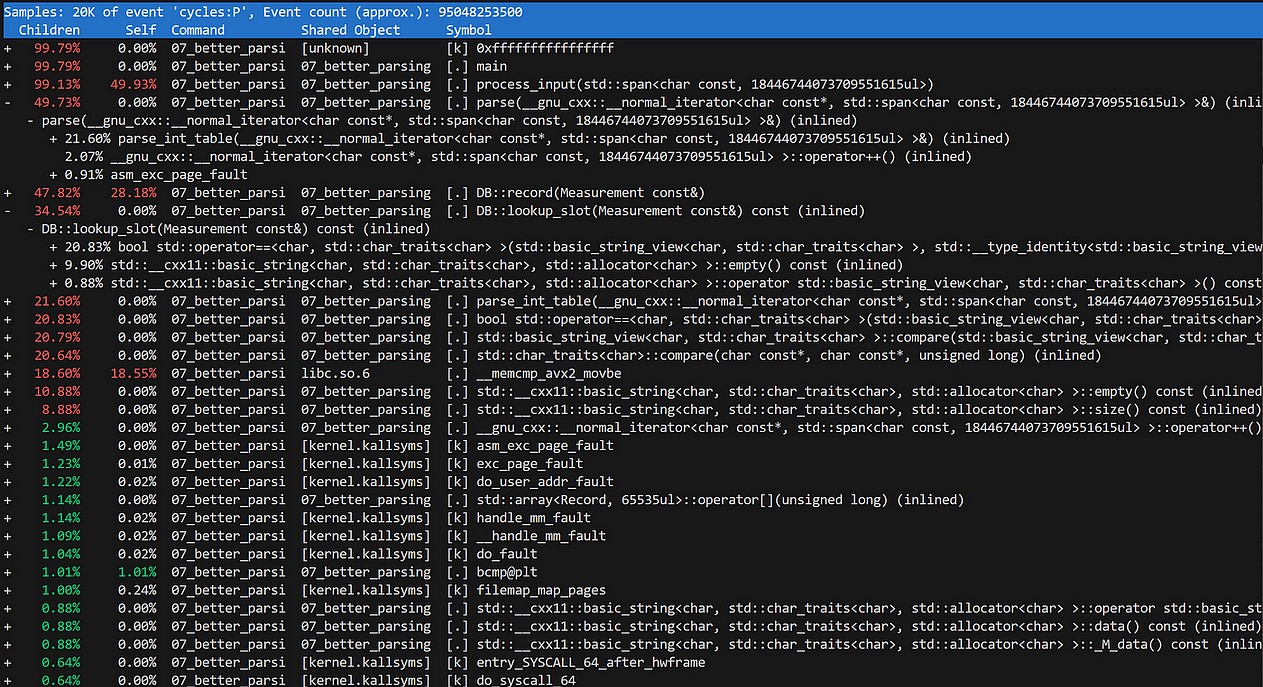
За исключением только что оптимизированного парсинга, поиска слотов и вставки данных, времени выполнения остается очень мало. Поэтому следующий этап — распараллеливание кода.
Проще всего разбить входные данные на примерно одинаковые куски, обработать каждый в отдельном потоке, затем объединить результат.
Доступ к кускам кода получаем, расширяя тип MappedFile:
struct MappedFile {
/* ... */
// Разбиваем входные данные на куски
std::vector<std::span<const char>> chunked(size_t chunks) const {
std::vector<std::span<const char>> result;
size_t chunk_sz = sz_ / chunks;
const char *chunk_begin = begin_;
for (size_t i = 0; i < chunks - 1; ++i) {
auto end = chunk_begin + chunk_sz;
// концовку куска соотносим с символом «
»
while (end != begin_ + sz_ && *end != '
')
++end;
++end;
result.push_back({chunk_begin, end});
chunk_begin = end;
}
// Последний кусок задаем вручную
result.push_back({chunk_begin, begin_ + sz_});
return result;
}
private:
MoveOnly<char *> begin_;
MoveOnly<size_t> sz_;
};Затем просто запускаем имеющийся код кусками, каждый в собственном потоке:
std::unordered_map<std::string, Record>
process_parallel(std::vector<std::span<const char>> chunks) {
// Каждый кусок обрабатываем в отдельном потоке
std::vector<std::jthread> runners(chunks.size());
std::vector<DB> dbs(chunks.size());
for (size_t i = 0; i < chunks.size(); ++i) {
runners[i] = std::jthread(
[&, idx = i]() { dbs[idx] = process_input(chunks[idx]); });
}
runners.clear(); // объединяем потоки
// Объединяем частичные базы данных
std::unordered_map<std::string, Record> merged;
for (auto &db_chunk : dbs) {
for (auto idx : db_chunk.filled_) {
auto it = merged.find(db_chunk.keys_[idx]);
if (it == merged.end()) {
merged.insert_or_assign(db_chunk.keys_[idx],
db_chunk.values_[idx]);
} else {
it->second.cnt += db_chunk.values_[idx].cnt;
it->second.sum += db_chunk.values_[idx].sum;
it->second.max = std::max(it->second.max,
db_chunk.values_[idx].max);
it->second.min = std::min(it->second.min,
db_chunk.values_[idx].min);
}
}
}
return merged;
}
Получаем неплохое масштабирование:
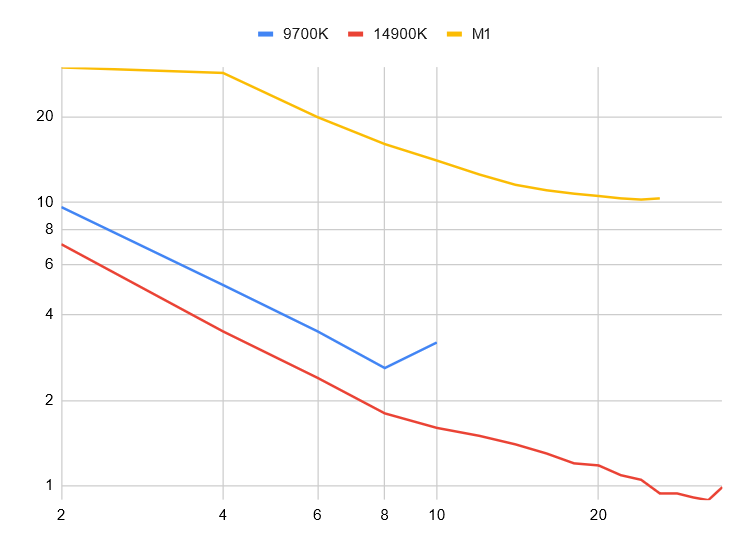
Вот оптимальные результаты — быстрейшие выполнения для относительного сравнения, а не строгого тестирования:
- 9700K на Fedora 39: 2,6 сек., в 50 раз быстрее, на восьми потоках,
- 14900K на WSL для Ubuntu: 0,89 сек., в 75 раз быстрее, на 32 потоках,
- Mac Mini M1: 10,2 сек., в 11 раз быстрее, на 24 потоках.
Работа с асимметричными скоростями обработки
9700K масштабируется очень чисто: у этого процессора восемь одинаковых ядер, которыми не поддерживается гиперпоточность. У 14900K архитектура намного сложнее ввиду наличия высокопроизводительных и энергоэффективных ядер.
Если просто разбить входные данные на одинаковые куски, из-за энергоэффективных ядер общее время выполнения замедлится. Поэтому вместо разбиения входных данных на куски — по одному на каждый поток — сделаем так, чтобы куски запрашивались потоками по мере необходимости:
// Каждый кусок обрабатываем в отдельном потоке
std::vector<std::jthread> runners(chunks);
std::vector<DB> dbs(chunks);
for (size_t i = 0; i < chunks; ++i) {
runners[i] = std::jthread([&, idx = i]() {
auto chunk = file.next_chunk();
while (not chunk.empty()) {
process_input(dbs[idx], chunk);
chunk = file.next_chunk();
}
});
}
runners.clear(); // объединяем потоки
Вот соответствующий метод next_chunk в MappedFile:
std::span<const char> next_chunk() {
std::lock_guard lock{mux_};
if (chunk_begin_ == begin_ + sz_)
return {};
size_t chunk_sz = 64 * 1024 * 1024; // 64 Мб
const char *end = nullptr;
// предотвращаем считывание по окончании файла
if (chunk_begin_ + chunk_sz > begin_ + sz_) {
end = begin_ + sz_;
} else {
end = chunk_begin_ + chunk_sz;
while (end != begin_ + sz_ && *end != '
')
++end;
++end;
}
std::span<const char> result{chunk_begin_, end};
chunk_begin_ = end;
return result;
}Таким образом выжимаем из 14900K всю производительность до последней капли:
- 14900K на WSL для Ubuntu: 0,77 сек., в 87 раз быстрее, на 32 потоках.
Заключение
Мы увеличили производительность исходной реализации в 87 раз, но стоило ли оно того?
Это как посмотреть. Статья долго писалась, и оттого на куски разбило меня самого. Выравнивание в микротестированиях было огромной проблемой.
В производственном коде я наверняка ограничился бы базовыми оптимизациями и потоками. Микрооптимизации полезны, но времязатратны и на современных архитектурах очень нестабильны.
Полный исходный код доступен в репозитории на GitHub.
Comments
https://www.jivatattva.in/collections/yellow-mustrad-oil