Наш первый миллиард строк в DuckDB

Введение
ИИ, наука о данных и инженерия данных развиваются полным ходом. Каждый день созданием новых инструментов, парадигм, архитектур предпринимаются попытки решить проблемы предыдущих. В этом море возможностей интересно узнать о новинках, способных делать это эффективно. Речь не только о технических нюансах, но и об области применения, преимуществах, недостатках, трудностях, возможностях, обнаруживаемых на практике.
Расскажем о новой базе данных DuckDB, предназначенной для обработки огромных объемов информации локально на компьютере. На основе логов электронных избирательных урн рассчитаем показатели времени голосования в Бразилии.
Это сложная задача и хороший ориентир для оценки производительности и удобства использования DuckDB. Решая ее, мы затронем технические, а также более «мягкие» аспекты, например опыт программирования и практичность.
DuckDB — проект с открытым исходным кодом, автор не аффилирован с DuckDB/DuckDB Labs. Используемые данные доступны по ODbL. Реализация этого проекта абсолютно бесплатна: не требуется оплаты услуг, доступа к данным, других расходов.
Задача
Задача заключается в обработке записей из логов электронных урн и получении статистических показателей о времени голосования бразильских избирателей, например средней продолжительности голосования граждан, сбора цифровых отпечатков для идентификации и т. д. Эти показатели агрегируются на нескольких уровнях детализации: страны, штата, избирательной зоны и избирательного участка.
В Бразилии система голосования на 100 % электронная, все 100+ миллионов граждан голосуют в один день, а результаты выборов подсчитываются и публикуются практически в режиме реального времени. В стране тысячи электронных избирательных урн, куда опускаются бюллетени для голосования.

Электронная урна — это специальный микрокомпьютер для голосования, она прочная, маленькая, легкая, энергетически автономная, оснащена элементами защиты. Чтобы избежать очередей в местах голосования, каждая урна рассчитана на 500 избирателей.
Система администрируется Высшим избирательным судом, на открытом портале данных которого публикуется информация о процессе голосования. Логи — это текстовые файлы с полным списком всех событий урны для голосования.
Здесь и начинаются трудности. В логах регистрируется абсолютно каждое событие, поэтому на их основе рассчитывается огромное количество показателей, это настоящий кладезь информации. Но их чрезвычайно сложно обрабатывать, ведь всех записей в стране — 450 Гб в файлах формата TSV и свыше 4 млрд строк.
Помимо объема, эта работа становится хорошим ориентиром для оценки DuckDB еще и из-за всевозможных трудностей преобразований, необходимых для достижения конечной цели задачи: от where, group by, order by до совсем сложных операций SQL, например оконных функций.
DuckDB
Такие довольно крупные объемы обрабатывают традиционными инструментами для больших данных вроде Apache Spark в кластере с многочисленными воркерами, гигабайтами оперативной памяти и дюжиной процессоров.
Но теперь стереотипам брошен вызов: с DuckDB обработать большие объемы данных машина способна в одиночку.
Не нужны сложные отраслевые решения вроде PySpark или облачные вроде BigQuery от Google. Необходимые преобразования реализуются в локальной базе данных, встроенной в процесс, со стандартным SQL.
Если вкратце, DuckDB — это внутрипроцессная система интерактивной аналитической обработки OLAP. Запускаемая в самой программе без независимого процесса и похожая на SQLite, она адаптирована к аналитическим нагрузкам и оптимизирована для обработки больших объемов данных в рамках одной машины, не обязательно очень мощной. Данные обрабатываются в традиционных форматах CSV, parquet.
Данные
Лог урны для голосования — это единый TSV-файл со стандартизированным названием XXXXXYYYYZZZZ.csv, которым обозначаются метаданные о местоположении урны: первые пять цифр — код города, следующие четыре — избирательный округ в соответствии с административно-территориальным делением, последние четыре — избирательный участок, сама урна.
В Бразилии почти 500 000 урн для голосования, соответственно, и файлов почти 500 000. Размер файла зависит от количества избирателей на участке, от 1 до 500. Вот логи:
2022-10-02 09:35:17 INFO 67305985 VOTA Voter was enabled
2022-10-02 09:43:55 INFO 67305985 VOTA Vote confirmed for [Federal Deputy]
2022-10-02 09:48:39 INFO 67305985 VOTA Vote confirmed for [State Deputy]
2022-10-02 09:49:10 INFO 67305985 VOTA Vote confirmed for [Senator]
2022-10-02 09:49:47 INFO 67305985 VOTA Vote confirmed for [Governor]
2022-10-02 09:50:08 INFO 67305985 VOTA Vote confirmed for [President]
2022-10-02 09:50:09 INFO 67305985 VOTA The voter's vote was computed
# Буквальный перевод на английский
# События — голос
Чтобы преобразовать эту «сырую» информацию в статистические показатели о времени голосования — сколько времени голосует каждый избиратель, сколько голосов подсчитывается каждую минуту — на уровнях детализации страны, штата и города, создадим OLAP-куб:
| Штат | Город | Среднее время | Максимальное число голосов, |
| | | голосования в секундах | подсчитанное за пять минут |
|---------------|-------------------|----------------------------|-----------------------------|
| Null | Null | 50 | 260 |
| Сан-Паулу | Сан-Паулу | 30 | 300 |
| Сан-Паулу | Кампинас | 35 | 260 |
| Сан-Паулу | Null | 20 | 260 |
| Риу-де-Жанейру| Риу-де-Жанейру | 25 | 360 |
| Минас-Жерайс | Белу-Оризонти | 40 | 180 |
| Баия | Салвадор | 28 | 320 |
| Рио-Гранде ...| Порту-Алегри | 30 | 300 |
| ... | ... | ... | ... |
Реализация
Настройка среды
Для запуска этого проекта нужна среда Python с установленным пакетом DuckDB:
pip install duckdb
Преобразование данных
Далее кратко опишем выполнение каждого преобразования, его цели, преимущества, проблемы, результаты и выводы. Весь код — в репозитории GitHub.
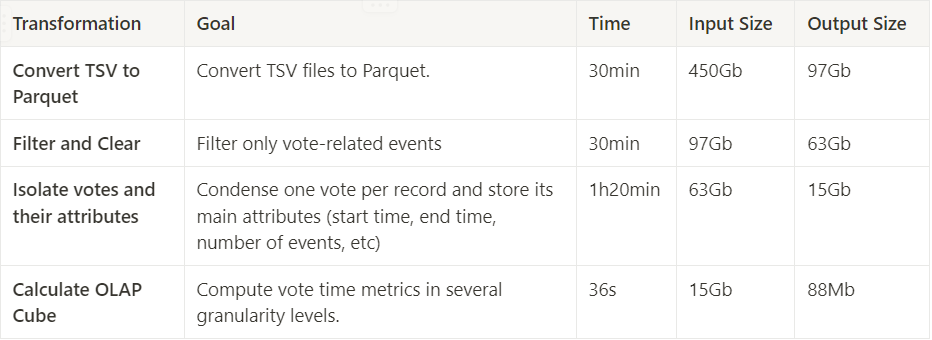
Обработка разделена на четыре этапа: преобразование TSV-файлов в Parquet; фильтрация и очистка; изолирование голосов и их атрибутов; вычисление показателей для OLAP-куба.
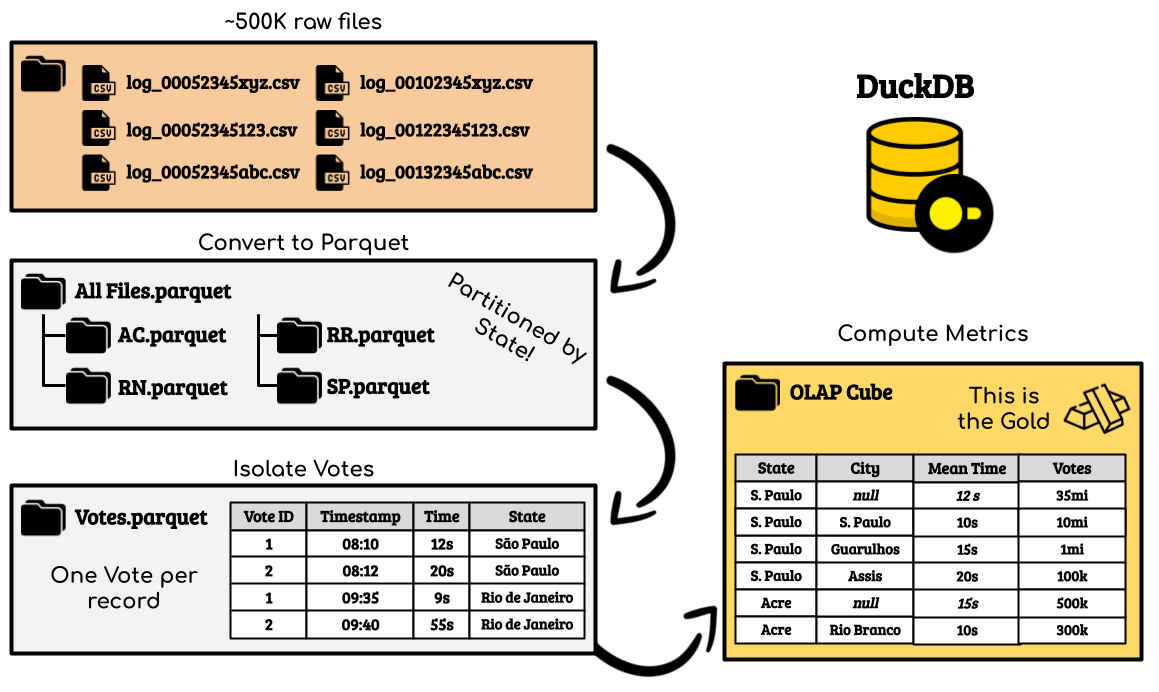
Преобразование TSV-файлов в Parquet
Этот важнейший этап для работы с большими объемами данных выполняется в DuckDB просто.
Сначала создаем сеанс DuckDB:
cursor = duckdb.connect("")В этом примере, чтобы не создавать в DuckDB собственный файл и взаимодействовать только с системными файлами, коннектор базы данных инициализируется пустой строкой. Напоминаем, DuckDB — база данных, имеющая функциональность для создания таблиц, представлений и т. д. Нас же он интересует исключительно как механизм преобразований.
Теперь определяем такой запрос:
query = f"""
COPY (
SELECT
*
FROM read_csv('/data/logs/2_{state}/*.csv', filename=True)
) TO '{state}.parquet' (FORMAT 'parquet');
"""
cursor.execute(query)
Внутреннее выражение — это стандартный запрос SELECT * FROM table, единственное отличие — DuckDB обращается не к таблице, а напрямую к файлам.
Результат этого запроса импортируется во фрейм данных Pandas для дальнейшего выражения:
my_df = cursor.execute(query).df()
Так обеспечивается плавная интеграция между DuckDB и Pandas.
Внешнее выражение — это простое COPY … TO … , которым результат внутреннего запроса записывается в виде файла.
В этом первом преобразовании обнаруживается одно из преимуществ DuckDB — возможность взаимодействовать с файлами с помощью старого доброго SQL и без необходимости настраивать что-либо еще. Приведенный выше запрос ничем не отличается от повседневных операций, выполняемых в стандартных СУБД вроде PostgreSQL и MySQL, с той лишь разницей, что мы взаимодействуем не с таблицами, а с файлами.
Изначально было 450 Гб TSV-файлов, а через ~30 минут оказалось 97 Гб Parquet.
Фильтрация и очистка
В логах хранятся все события урны для голосования. Цель этого этапа — фильтрация только связанных с голосованием событий, таких как The voter voted for PRESIDENT («Избиратель проголосовал за Президента»), The Voter had fingerprints collected («Собраны цифровые отпечатки избирателя») и The vote was computed («Голос учтен»), которые произошли в дни голосования. Это важно, ведь в логах хранятся также разделы тренировки и другие реализованные административные процедуры.
Простой запрос, но с многочисленными манипуляциями над текстом и датами:
VOTES_DESCRIPTIONS = [
# Голоса
"event_description = 'Aguardando digitação do título'",
# Ожидание ввода регистрационного идентификатора избирателя
"event_description = 'Título digitado pelo mesário'",
# Регистрационный идентификатор избирателя введён членом УИК
"event_description = 'Eleitor foi habilitado'",
# Избиратель допущен до голосования
"event_description ILIKE 'Voto confirmado par%'",
# Подтвержден голос за ... [Президента, сенатора, депутата, ...]
"event_description = 'O voto do eleitor foi computado'",
# Голос избирателя учтен
]
ACCEPTED_DATES = [
'2022-10-02', '2022-10-30', # Конституционная дата избирательного фильтра
'2022-10-03', '2022-10-31',
]
query = F"""
SELECT
*
FROM (
SELECT
event_timestamp,
event_timestamp::date AS event_date,
event_type,
some_id,
event_system,
event_description,
event_id,
REPLACE(SPLIT_PART(filename, '/', 5), '_new.csv', '') AS filename,
-- Metadata from filename
SUBSTRING( SPLIT_PART(SPLIT_PART(filename, '/', 5), '-', 2), 1, 5 ) AS city_code,
SUBSTRING( SPLIT_PART(SPLIT_PART(filename, '/', 5), '-', 2), 6, 4 ) AS zone_code,
SUBSTRING( SPLIT_PART(SPLIT_PART(filename, '/', 5), '-', 2), 10, 4 ) AS section_code,
REPLACE(SPLIT_PART(filename, '/', 4), '2_', '') AS uf
FROM
{DATASET}
WHERE 1=1
AND ( {' OR '.join(VOTES_DESCRIPTIONS)} )
) _
WHERE 1=1
AND event_date IN ({', '.join([F"'{date}'" for date in ACCEPTED_DATES])})
"""
В этом запросе обнаруживается еще одно преимущество DuckDB — возможность чтения и записи секционированных данных. Секционирование таблиц очень актуально в контексте больших данных, тем более в одномашинной парадигме с учетом использования одного и того же диска для ввода и вывода, то есть двойной нагрузки для него. Поэтому любая оптимизация приветствуется.
Изначально было 97 Гб, а через ~30 минут осталось 63 Гб Parquet.
Изолирование голосов и их атрибутов
Под каждый голос выделено несколько строк. Чтобы упростить расчеты, всю информацию необходимо сжать в уникальную запись. Запрос усложняется, и DuckDB не в состоянии обработать сразу все данные.
Проблема решается циклом, где данные обрабатываются постепенно, частями:
for state in states:
for date in ACCEPTED_DATES:
for zone_group in ZONE_GROUPS:
query = F"""
COPY
{
complex_query_goes_here
.replace('<uf>', state)
.replace('<event_date>', date)
.replace('<zone_id_min>', str(zone_group[0]))
.replace('<zone_id_max>', str(zone_group[1]))
}
TO 'VOTES.parquet'
(FORMAT 'parquet', PARTITION_BY (event_date, uf, zone_group), OVERWRITE_OR_IGNORE 1);
"""
Детали реализации не важны. Так постепенно создается итоговая таблица, код при этом меняется не сильно. Каждая обработанная «часть» — это раздел. Если задать параметру OVERWRITE_OR_IGNORE значение 1, в DuckDB любые данные для этого раздела автоматически перезаписываются или, при их наличии, игнорируются.
Изначально было 63 Гб, а через ~1 час 20 минут оказалось 15 Гб Parquet.
Вычисление показателей и построение OLAP-куба
Это простой этап. Теперь каждый голос представлен записью, остается вычислить показатели:
query_metrics = F"""
SELECT
turno, state,
zone_code,
section_code,
COUNT(*) AS total_votes,
COUNT( DISTINCT state || zone_code || section_code ) AS total_sections,
SUM( vote_time ) AS voting_time_sum,
AVG( vote_time ) AS average_voting_time,
MAX( nr_of_votes ) AS total_ballot_items_voted,
SUM( nr_of_keys_pressed ) AS total_keys_pressed
FROM
source
GROUP BY ROLLUP(turno, state, zone_code, section_code)
"""
На многочисленных уровнях детализации показатели идеально вычисляются с помощью GROUP BY и ROLLUP.
Здесь DuckDB здорово отличилась: за 36 секунд файл с 15 Гб сократился до 88 Мб.
Сгруппировать более 200 000 000 строк на четырех уровнях детализации с кратностью самого высокого 2, самого низкого ~200 000 меньше чем за минуту — это невероятно высокая производительность.
Результаты
Результаты отражены в этой таблице:
Общее время выполнения конвейера ~2,5 часа, характеристики машины: WSL, то есть подсистема Windows для Linux, ~16 Гб оперативной памяти DDR4, процессор Intel Core i7 12-го поколения и твердотельный накопитель NVMe SSD емкостью 1 Тб.
В процессе выполнения обнаружено узкое место — расход памяти, в DuckDB на диске в каталоге .temp/ постоянно создавались временные файлы. Много проблем было и с запросами посредством оконных функций: они выполнялись дольше, чем ожидалось, и программа случайным образом несколько раз аварийно завершалась.
Тем не менее достигнута удовлетворительная производительность: 1/2 Тб данных обработано сложными запросами на одной-единственной машине, мощь которой не сравнится с кластерами компьютеров.
Заключение
Иногда обработка данных похожа на обогащение урана: из огромной массы исходного материала с помощью сложного, времязатратного и дорогостоящего процесса извлекается небольшое количество очищенной информации.
В статьях мы изучаем способы обработки данных, инструменты, приемы, архитектуры данных… всегда в поисках оптимального решения задач. Эти знания важны, ведь таким образом для работы подбирается правильный инструмент. Наша цель как раз и заключалась в том, чтобы рассказать об особенностях работы DuckDB, решаемых задачах и приобретенном с ее помощью опыте.
И в целом это был хороший опыт.
Работать с этой базой данных очень просто, практически ничего не пришлось настраивать, только импортировать данные и обрабатывать их старыми добрыми операторами SQL. У этого инструмента почти нулевой входной барьер для тех, кто уже знает SQL и немного Python.
Это была большая победа DuckDB, с которой машина способна в одиночку обработать 450 Гб данных при низких затратах на адаптацию как для среды, так и для программиста.
Если говорить о скорости обработки, то с учетом сложности проекта, объема в 450 Гб и неоптимизированных параметров базы данных 2,5 часа — хороший результат. Не имея в компьютере этого инструмента, выполнить поставленную задачу нереально.
Ниша DuckDB — где-то между Pandas и Spark. При работе с маленькими объемами данных удобнее Pandas, особенно для опытных программистов, из-за наличия в пакете многочисленных встроенных преобразований, трудно реализуемых в SQL. И он плавно интегрируется со многими другими пакетами Python, в том числе DuckDB. При работе с огромными объемами данных оптимальнее Spark — из-за параллелизма, кластеров и тому подобного. DuckDB же придется кстати в средних и не очень крупных проектах, где применение Pandas невозможно, а Spark — излишне.
С DuckDB машина в одиночку способна достичь большего, расширяются возможности локальной разработки проектов, ускоряются анализ и обработка больших объемов данных. Рекомендуем вам добавить этот мощный инструмент в свой инструментарий.
Получив представление о DuckDB, продолжайте изучение по материалам ниже, весь код — в репозитории на GitHub.
Полезные ссылки
[1] Результаты 2022 — файлы, переданные для обобщения — открытый портал данных TSE.
[2] Databricks, 29 июня 2023 г. Основной доклад по данным и ИИ, четверг, часть 5 — DuckDB.
[3] Официальная документация DuckDB.
[4] Gunnarmorling. GitHub — gunnarmorling/1brc: Проблема на миллиард строк — увлекательное 1️⃣🐝🏎️исследование о том, как быстро 1 млрд строк текстового файла агрегируется на Java.
Comments