Бета-распределение: интуиция, примеры, вывод

Бета-распределение — это распределение вероятностей по вероятностям. Мы можем использовать его для моделирования вероятностей: рейтинг кликов вашей рекламы, коэффициент конверсии клиентов, фактически купивших что-то на вашем сайте, насколько вероятно, что посетители поставят лайки в вашем блоге, насколько вероятно избрание Трампа на второй срок, 5-летний прогноз выживания женщин с раком груди и так далее.
Так как бета-распределение моделирует вероятность, его область определения ограничена 0 и 1.
Почему плотность вероятности бета-распределения выглядит именно так?
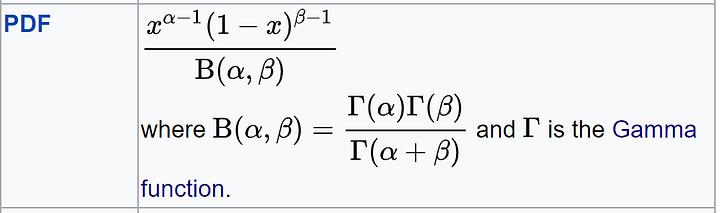
Интуитивное определение
Давайте на минутку проигнорируем коэффициент 1/B(α,β) и рассмотрим толькочислитель x^(α-1) * (1-x)^(β-1), потому что 1/B(α,β) — просто нормализирующая постоянная для того, чтобы функция интегрировалась к 1.
Тогда выражения в числителе — x в некоторой степени, умноженное на 1-x в некоторой степени — выглядят знакомо.
Мы видели это раньше?
? Да! Это биномиальное распределение
Интуиция бета-распределения вступает в игру, когда мы рассматриваем ее через призму биномиального распределения.

Разница между биномиальным и бета-распределением в том, что первое моделирует число событий (x), а второе моделирует вероятность (p) как таковую.
Другими словами, вероятность — параметр в биномиальном распределении, а в бета—случайная переменная.
Интерпретация α, β
Примем α-1 за количество успешных исходов и β-1 за количество неудач, совсем как n и n-x в биномиальном распределении.
Параметры α и β могут быть какими угодно. Если вы думаете, что вероятность успеха очень велика, скажем, 90%, задайте значение 90 для α и 10 для β. Или наоборот, 90 для β и 10 для α.
Когда α становится больше (больше успешных событий), выпуклость функции смещается вправо, в то время как увеличение β сдвигает распределение влево (больше неудач).
Кроме того, распределение будет сужаться с одновременным увеличением α и β.
Пример: вероятность вероятности
Скажем, насколько вероятно, что кто-то согласится пойти с вами на свидание, следуя бета-распределению с α = 2 и β = 8. Какова вероятность того, что коэффициент успеха будет более 50%?
P(X>0.5) = 1- функция распределения(0.5) = 0.01953
Сожалею, вероятность очень низкая ?
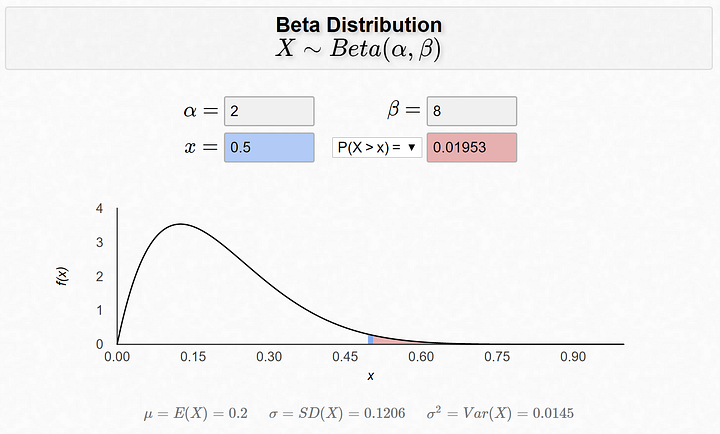
Доктор Богнар из Университета Айовы написал полезный и красивый калькулятор для бета-распределения. Поэкспериментируйте со значениями α и β и посмотрите, как меняется форма.
Зачем мы используем бета-распределение?
Чтобы распределение вероятностей моделировало вероятность, любое произвольное распределение по (0, 1) сработает. И создать его было бы легко: просто возьмите любую функцию, которая не вздувается между 0 и 1 и остается положительной, затем проинтегрируйте ее от 0 до 1 и разделите функцию на результат. Вы только что получили функцию, которую можно использовать для моделирования вероятности. Так почему же мы настаиваем на использовании бета-распределения по произвольному распределению вероятностей?
Что такого особенного в бета-распределении?
Бета-распределение — это сопряженное априорное распределение для распределений Бернулли, биномиального, отрицательного биномиального и геометрического (похоже, это распределения, включающие в себя успех и неудачу) в байесовском выводе.
Использовать сопряженное априорное распределение для вычисления априорной вероятности очень удобно, так как вы сможете избежать трудоемких численных расчетов, связанных с байесовским выводом.
Если вы не знаете, что такое сопряженное априорное распределение или баейсовский вывод, прочитайте сперва эти две статьи:
Сопряженное априорное распределение
Байесовский вывод — интуиция и примеры
В нашем примере про свидание бета-распределение является сопряженным до биномиальной вероятности. Если мы решим использовать бета-распределение в качестве сопряженного априорного в процессе моделирования, то мы уже будем знать, что априорное распределение также будет бета-распределением. Следовательно, после проведения большего количества экспериментов (попросив еще больше людей сходить с вами на свидание), вы сможете вычислить апостериорную вероятность просто добавив число согласий и отказов к существующим параметрам α, β соответственно, вместо того, чтобы умножать вероятность на априорное распределение.
Бета-распределение очень гибкое
Плотность вероятности бета-распределения может быть U-образной формы с асимптотическими концами, колоколообразным, строго возрастающим или убывающим или даже просто линией. Вы изменяете значения α или β — форма распределения тоже меняется.
a. Колокообразное
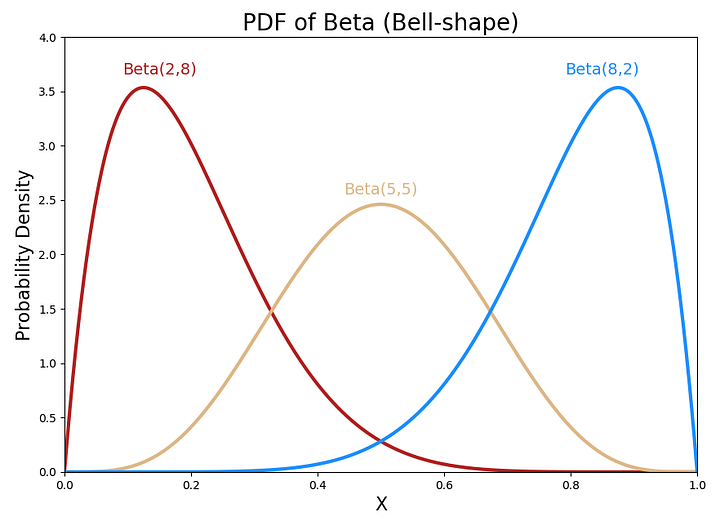
Обратите внимание, что график плотности вероятности с α = 8 и β = 2 голубой, не красный. Ось x — это вероятность успешного исхода.
Плотность вероятности бета-распределения приблизительно нормальная, если α +β достаточно велико, а α и β приблизительно одинаковы.
b. Прямые
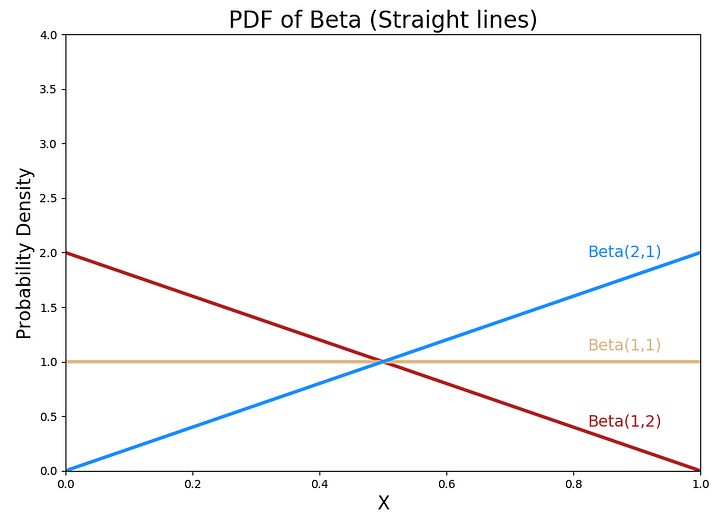
Бета-распределение плотности вероятности может быть и прямой линией!
c. U-образная форма
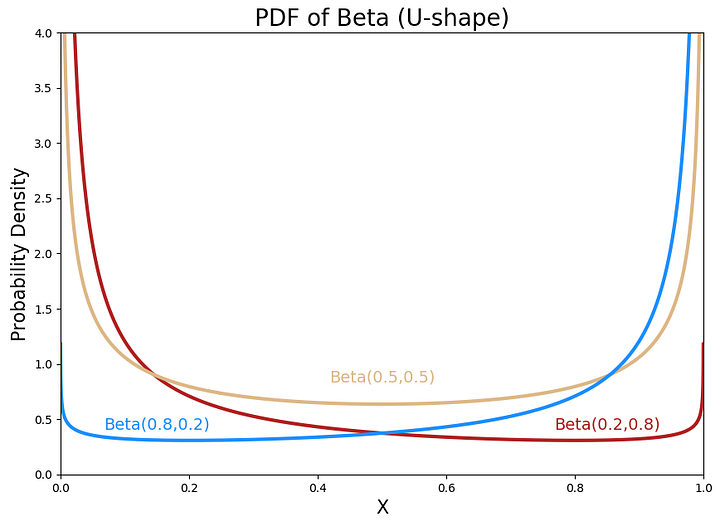
Когда α <1, β<1, плотность вероятности бета-распределения принимает U-образную форму.
Интуиция за формами
Почему бета-распределение (2,2) будет колокообразным?
Если α-1 — количество успешных исходов и β-1 — количество неудач, Бета(2,2) означает 1 успех и 1 неудачу. Имеет смысл предполагать, что вероятность успеха наиболее высока в 0.5.
Кроме того, Бета(1,1) будет означать, что у вас 0 в голове функции и 0 в хвосте. Тогда предположение о вероятности будет одинаковым на протяжении [0,1]; горизонтальная прямая подтверждает это.
Код для создания графиков, показанных выше:
import numpy as np
from scipy.stats import beta
import matplotlib.pyplot as plt
plt.rcParams['figure.figsize'] = [10, 7]
# Колокообразный
x = np.linspace(0, 1, 10000)
y1 = beta.pdf(x, 2, 8)
y2 = beta.pdf(x, 5, 5)
y3 = beta.pdf(x, 8, 2)
plt.title("PDF of Beta (Bell-shape)", fontsize=20)
plt.xlabel("X", fontsize=16)
plt.ylabel("Probability Density", fontsize=16)
plt.plot(x, y1, linewidth=3, color='firebrick')
plt.annotate("Beta(2,8)", xy=(0.15, 3.7), size = 14, ha='center', va='center', color='firebrick')
plt.plot(x, y2, linewidth=3, color='burlywood')
plt.annotate("Beta(5,5)", xy=(0.5, 2.6), size = 14, ha='center', va='center', color='burlywood')
plt.plot(x, y3, linewidth=3, color='dodgerblue')
plt.annotate("Beta(8,2)", xy=(0.85, 3.7), size = 14, ha='center', va='center', color='dodgerblue')
plt.ylim([0, 4])
plt.xlim([0, 1])
plt.show()
# Прямые
x = np.linspace(0, 1, 10000)
y1 = beta.pdf(x, 1, 2)
y2 = beta.pdf(x, 1, 1)
y3 = beta.pdf(x, 2, 1)
plt.title("PDF of Beta (Straight lines)", fontsize=20)
plt.xlabel("X", fontsize=16)
plt.ylabel("Probability Density", fontsize=16)
plt.plot(x, y1, linewidth=3, color='firebrick')
plt.annotate("Beta(1,2)", xy=(0.88, 0.45), size = 14, ha='center', va='center', color='firebrick')
plt.plot(x, y2, linewidth=3, color='burlywood')
plt.annotate("Beta(1,1)", xy=(0.88, 1.15), size = 14, ha='center', va='center', color='burlywood')
plt.plot(x, y3, linewidth=3, color='dodgerblue')
plt.annotate("Beta(2,1)", xy=(0.88, 2.0), size = 14, ha='center', va='center', color='dodgerblue')
plt.ylim([0, 4])
plt.xlim([0, 1])
plt.show()
# U-образные
x = np.linspace(0, 1, 10000)
y1 = beta.pdf(x, 0.2, 0.8)
y2 = beta.pdf(x, 0.5, 0.5)
y3 = beta.pdf(x, 0.8, 0.2)
plt.title("PDF of Beta (U-shape)", fontsize=20)
plt.xlabel("X", fontsize=16)
plt.ylabel("Probability Density", fontsize=16)
plt.plot(x, y1, linewidth=3, color='firebrick')
plt.annotate("Beta(0.2,0.8)", xy=(0.85, 0.45), size = 14, ha='center', va='center', color='firebrick')
plt.plot(x, y2, linewidth=3, color='burlywood')
plt.annotate("Beta(0.5,0.5)", xy=(0.5, 0.88), size = 14, ha='center', va='center', color='burlywood')
plt.plot(x, y3, linewidth=3, color='dodgerblue')
plt.annotate("Beta(0.8,0.2)", xy=(0.15, 0.45), size = 14, ha='center', va='center', color='dodgerblue')
plt.ylim([0, 4])
plt.xlim([0, 1])
plt.show()Классический вывод: порядковая статистика
Когда я изучала бета-распределение в университете, я выводила его из порядковой статистики. Хоть порядковая статистика и не самое распространенное применение бета-распределения, но она помогла мне глубже и лучше его понять.
Пусть X_1, X_2, . . . , X_n — независимые и одинаково распределенные случайные переменные с плотностью вероятности f и распределением вероятности F.
Мы расположим их по возрастанию так, чтобы X_k был k-ым наименьшим X, называемым k-ой порядковой статистикой.
a. Какова плотность максимального X?
(Не знакомы с термином “плотность”? Читайте “Плотность вероятности не есть сама вероятность”)

b. Какова плотность k-ой порядковой статистики?
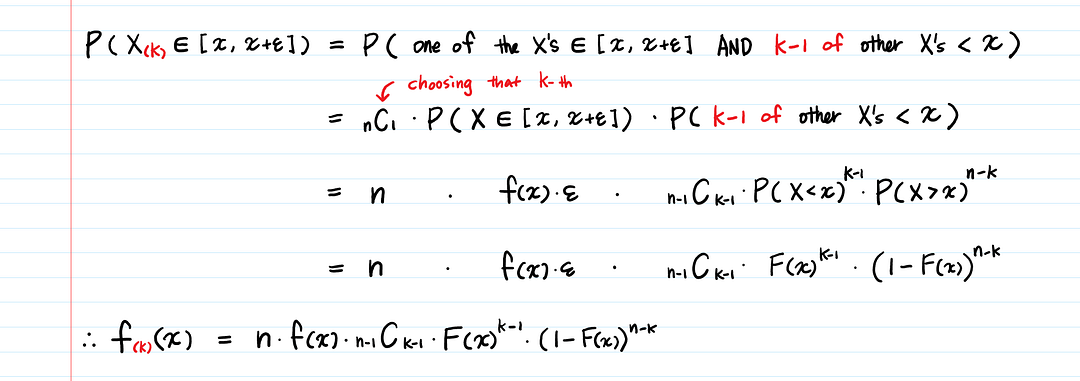
c. Как вывести бета-распределение, используя k-ую порядковую статистику?
Что произойдет, если мы установим X_1, X_2, . . . , X_n как независимые и одинаково распределенные случайные переменные в равномерном распределении(0,1)?
Почему равномерное распределение(0,1)? Потому что область определения бета-распределения — [0,1].

Привет, а вот и бета!
Бета-функция как нормализующая постоянная
Ранее я предложила:
Давайте проигнорируем коэффициент 1/B(α,β) … потому что 1/B(α,β) — просто нормализирующая постоянная для того, чтобы функция интегрировалась к 1.
Каким должно быть значение B(α,β), чтобы плотность вероятности бета-распределения интегрировалась к 1?
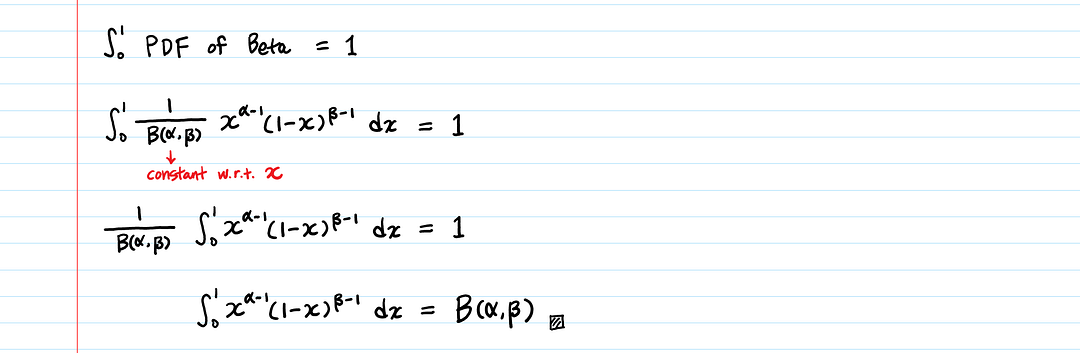
B(α,β) — это область под графиком плотности вероятности бета-распределения от 0 до 1.
Упрощение бета-функции с гамма-функцией!
Этот раздел для таких же фанатов доказательств, как я.
Бета-функция — это отношение произведения гамма-функции каждого параметра к гамма-функции суммы параметров.
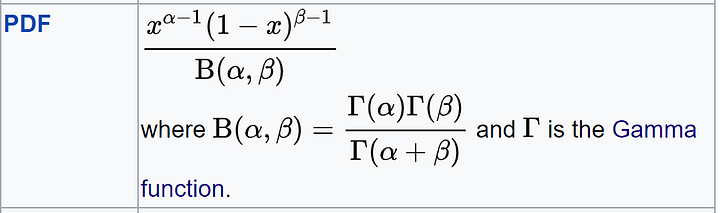
Как доказать, что B(α,β) = Γ(α) * Γ(β) / Γ(α+β)?
Давайте возьмем специальный случай, где α и β — числа, и начнем с того, что вывели выше.
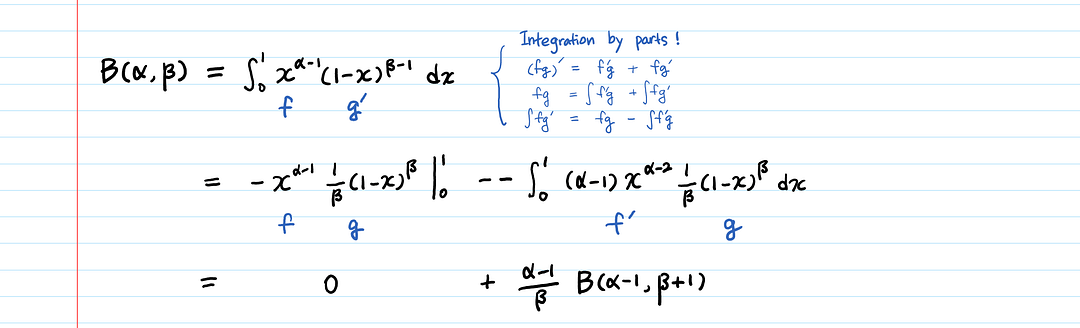
Мы получили рекурсивное взаимодействие B(α,β) = (α-1) * B(α-1,β+1) / β.
Как нам воспользоваться этим взаимодействием?
Мы можем попытаться добраться до базового варианта B(1, *).
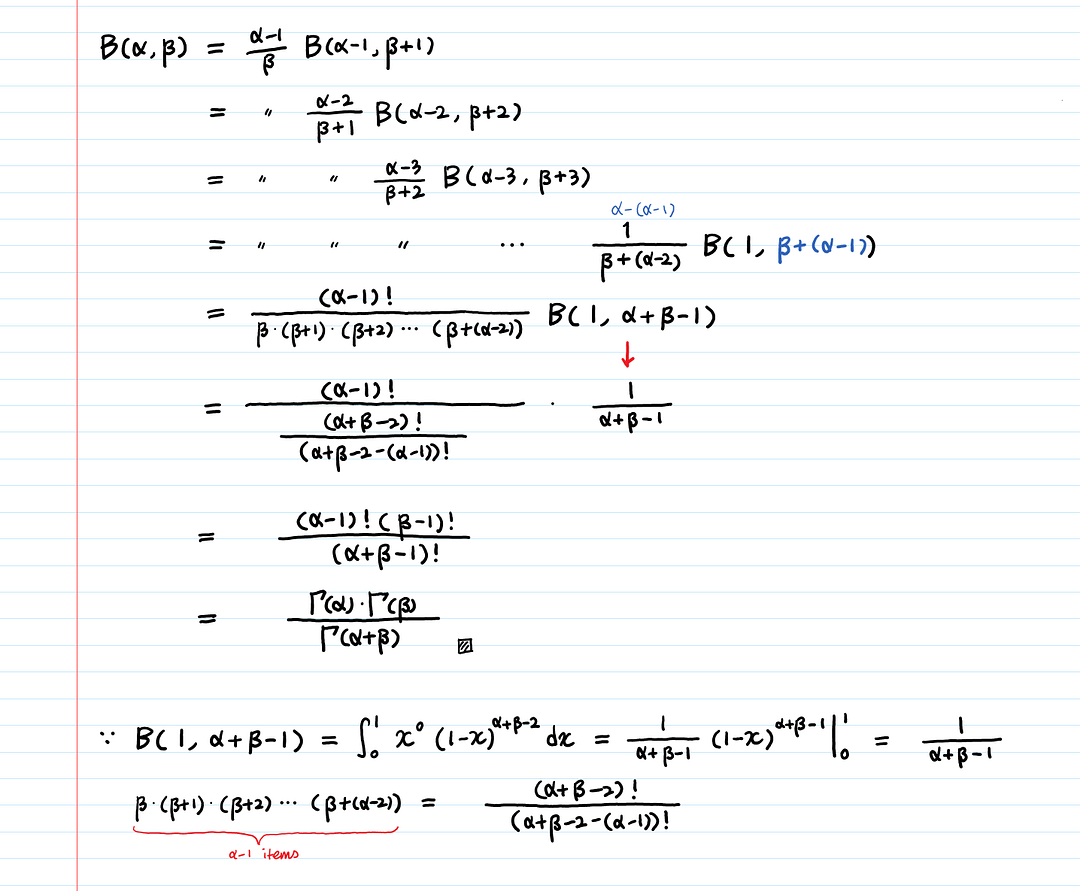
Красиво доказано!
Comments