4 способа добавления колонок в датафреймы Pandas

Pandas — это библиотека для анализа и обработки данных, написанная на языке Python. Она предоставляет множество функций и способов для управления табличными данными. Основная структура данных Pandas — это датафрейм, который хранит информацию в табличной форме с помеченными строками и столбцами.
В контексте данных строки представляют собой утверждения, или точки данных. Столбцы отражают свойства, или атрибуты утверждений. Рассмотрим эту структуру на простом примере. Допустим, каждая строка — это дом. В таком случае, столбцы заключают в себе сведения об этом доме (его возрасте, количестве комнат, стоимости и т.д.).
Добавление или удаление столбцов — обычная операция при анализе данных. Ниже мы разберем 4 различных способа добавления новых столбцов в датафрейм Pandas.
Сначала создадим простой фрейм данных для использования в примерах:
import numpy as np
import pandas as pd
df = pd.DataFrame({"A": [1, 2, 3, 4],
"B": [5, 6, 7, 8]})
df
Способ 1-й
Пожалуй, это самый распространенный путь создания нового столбца в Pandas:
df["C"] = [10, 20, 30, 40]
df
Мы указываем имя столбца подобно тому, как выбираем столбец во фрейме данных. Затем этому столбцу присваиваются значения. Новый столбец добавляется последним (т. е. становится столбцом с самым высоким индексом).
Можно добавить сразу несколько столбцов. Их наименования перечисляются списком, а значения должны быть двумерными для совместимости с количеством строк и столбцов. Например, следующий код добавляет три столбца, заполненные случайными целыми числами от 0 до 10:
df[["1of3", "2of3", "3of3"]] = np.random.randint(10, size=(4,3))
df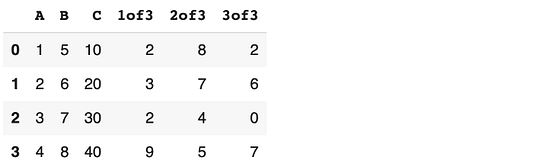
Давайте удалим эти три столбца, прежде чем перейти к следующему методу.
df.drop(["1of3", "2of3", "3of3"], axis=1, inplace=True)
Способ 2-й
В первом способе мы добавляли новый столбец в конец. Pandas также позволяет добавлять столбцы по определенному индексу. Для настройки расположения нового столба воспользуемся функцией вставки (insert function). Давайте добавим один столбец рядом с А:
df.insert(1, "D", 5)
df
Для использования функции вставки необходимо 3 параметра: индекс, имя столбца и значение. Индексы столбцов начинаются с 0, поэтому мы устанавливаем параметр индекса 1, чтобы добавить новый столбец рядом со столбцом A. Мы можем указать постоянное значение, которое будет выставлено во всех строках.
Способ 3-й
Функция loc позволяет выбирать строки и столбцы, используя их метки. Таким же образом можно создать новый столбец:
df.loc[:, "E"] = list("abcd")
df
Для выбора строк и столбцов мы указываем нужные метки. Если хотим выбрать все строки, ставим двоеточие. В части таблицы, где нужно проставить столбец, указываем метки столбцов, которые нам необходимо выбрать. Поскольку в датафрейме нет столбца E, Pandas создаст новый столбец.
Способ 4-й
Добавить столбцы можно также с помощью функции assign:
df = df.assign(F = df.C * 10)
df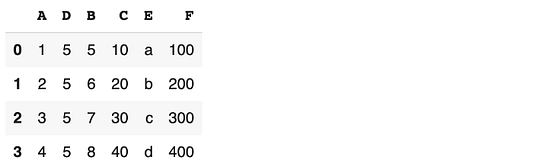
В функции assign необходимо прописать имя столбца и значения. Обратите внимание: мы получаем значения, используя другой столбец во фрейме данных. Предыдущие способы также допускают такую операцию.
Надо понимать, что между функциями assign и insert есть существенное различие.
Функция вставки (insert) работает на месте. Это означает, что изменение (добавление нового столбца) сохраняется во фрейме данных.
С функцией назначения ситуация немного иная. Он возвращает измененный фрейм данных, но не изменяет исходный. Чтобы использовать измененную версию (с новым столбцом), нам нужно явно назначить ее.
Заключение
Мы рассмотрели 4 различных способа добавления новых столбцов в фрейм данных Pandas. Это обычная операция при анализе и обработке данных.
Мне нравится пользоваться библиотекой Pandas, поскольку она предоставляет, как правило, несколько способов для выполнения одной задачи. По-моему, это говорит о гибкости и универсальности Pandas.
Comments