GraphSAGE: как масштабировать графовые нейронные сети до миллиардов соединений

Что общего между UberEats и Pinterest? Их рекомендательные системы работают с помощью GraphSAGE в огромных масштабах с миллионами и миллиардами узлов и ребер.
- Pinterest разработал собственную версию под названием PinSAGE, чтобы рекомендовать пользователям наиболее актуальные изображения (пины). Граф этого ресурса содержит 18 миллиардов соединений и 3 миллиарда узлов.
- UberEats также использует модифицированную версию GraphSAGE, чтобы предлагать блюда, рестораны и различные виды кухни. Эта платформа утверждает, что поддерживает более 600 000 ресторанов и 66 миллионов пользователей.
В этом руководстве мы используем набор данных с 20 тысячами узлов, а не миллиардами, из-за ограничений Google Colab. В процессе изучения будем придерживаться архитектуры оригинального GraphSAGE, а также затронем некоторые интересные функции из предыдущих вариантов.
Код можно запустить с помощью этого блокнота Google Colab.
1. Набор данных PubMed
PubMed является частью датасета Planetoid (лицензия MIT). Вот что нужно о нем знать.
- Он содержит 19 717 научных работ, посвященных диабету, из базы данных PubMed.
- Характеристики узлов представляют собой взвешенные по TF-IDF векторы слов с 500 измерениями — это довольно удобный способ резюмирования документов без трансформеров.
- Задача сводится к классификации по трем категориями: экспериментальный сахарный диабет, сахарный диабет 1 типа и сахарный диабет 2 типа.
Цель — достичь точности в 70%.
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='.', name="Pubmed")
data = dataset[0]
# Вывод информации о датасете
print(f'Dataset: {dataset}')
print('-------------------')
print(f'Number of graphs: {len(dataset)}')
print(f'Number of nodes: {data.x.shape[0]}')
print(f'Number of features: {dataset.num_features}')
print(f'Number of classes: {dataset.num_classes}')
# Вывод информации о графе
print(f'
Graph:')
print('------')
print(f'Training nodes: {sum(data.train_mask).item()}')
print(f'Evaluation nodes: {sum(data.val_mask).item()}')
print(f'Test nodes: {sum(data.test_mask).item()}')
print(f'Edges are directed: {data.is_directed()}')
print(f'Graph has isolated nodes: {data.has_isolated_nodes()}')
print(f'Graph has loops: {data.has_self_loops()}')
Dataset: Pubmed()
-------------------
Number of graphs: 1
Number of nodes: 19717
Number of features: 500
Number of classes: 3
Graph:
------
Training nodes: 60
Evaluation nodes: 500
Test nodes: 1000
Edges are directed: False
Graph has isolated nodes: False
Graph has loops: False
PubMed имеет невероятно низкое количество обучающих узлов в сравнении с полным графом — ему нужно всего 60 образцов, чтобы научиться классифицировать 1000 тестовых узлов.
Несмотря на сложности, GGNs смогла добиться высокого уровня точности. Вот таблица лидеров среди известных методик, согласно PapersWithCode:

Я не смог найти результатов для GraphSAGE на PubMed, используя эту специфическую настройку (60 обучающих узлов и 1000 тестовых), так что не рассчитываем на высокую точность. Но при работе с большими графами не менее актуальной может оказаться и другая метрика: время обучения.
2. GraphSAGE в теории
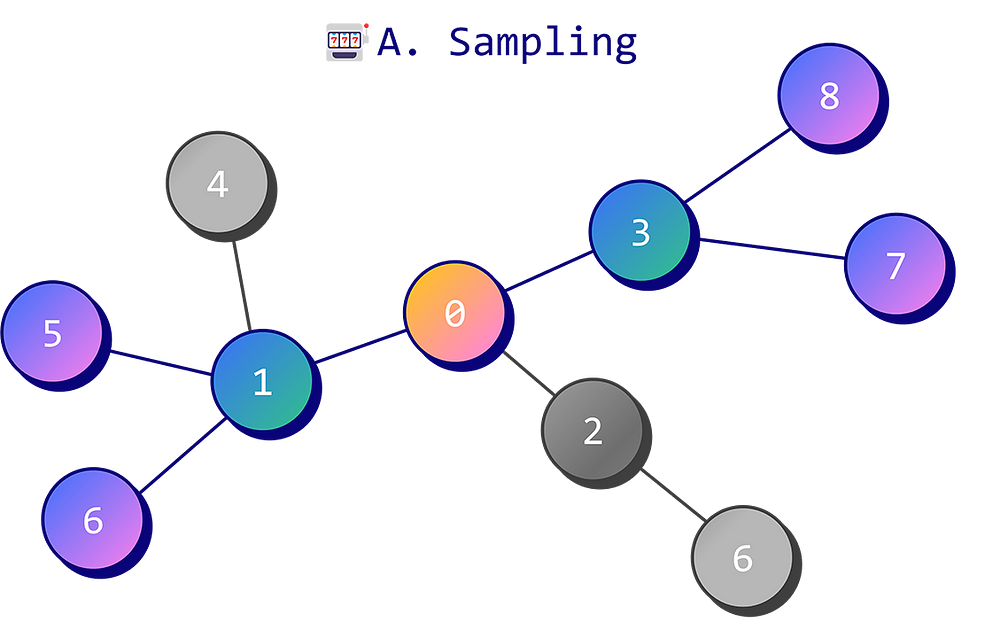
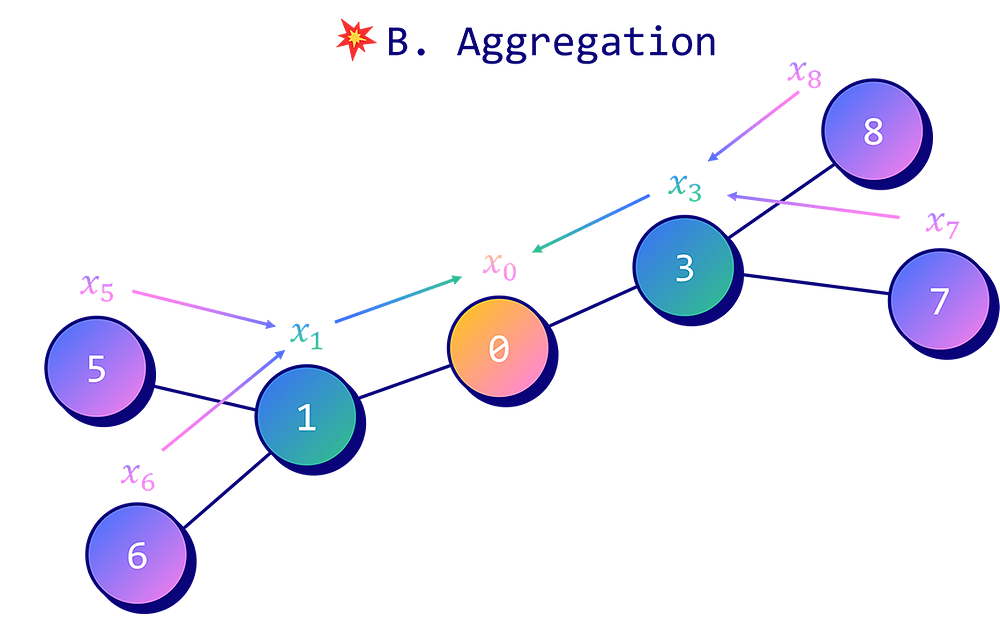
Алгоритм GraphSAGE можно разделить на два этапа.
- Выборка по соседям.
- Агрегация.
Выборка по соседям
Мини-пакетирование — распространенная техника, используемая в машинном обучении. Она разбивает набор данных на пакеты меньших размеров, что позволяет обучать модели более эффективно. Вот некоторые преимущества этой техники.
- Улучшенная точность. Мини-пакеты помогают уменьшить перебор (градиенты усреднены), а также дисперсию в показателях ошибок.
- Увеличенная скорость. Мини-пакеты обрабатываются параллельно и требуют меньше времени на обучение, чем пакеты больших размеров.
- Улучшенное масштабирование. Весь набор данных может превысить объем памяти GPU, но небольшие пакеты могут обойти это ограничение.
Техника мини-пакетирования настолько удобна, что стала стандартом для работы в обычных нейронных сетях. Однако с графическими данными все не так просто, поскольку разделение набора данных на мелкие куски приводит к разрыву важных связей между узлами.
Что же делать? За последние годы было разработано несколько стратегий по созданию мини-пакетов для графов, в том числе выборка по соседям. Также существуют и другие техники, которые можно найти в документации PyG, например кластеризация подграфов.
Техника выборки по соседям рассматривает только фиксированные числа случайных соседей. Вот как выглядит процесс.
- Определяем количество соседей (1 переход), количество соседей у этих соседей (2 перехода) и так далее.
- Выборщик просматривает список соседей узла, соседей этих соседей и так далее, после чего случайным образом выбирает заранее установленное их количество.
- Выборщик выводит подграф, содержащий целевой узел и случайно выбранные соседние узлы.
Этот процесс повторяется для каждого узла из списка или целиком для всего графа. Но создавать подграф для каждого узла неэффективно, вместо этого мы можем обработать их пакетно. В этом случае каждый подграф используется несколькими целевыми узлами.
Выборка по соседям имеет еще одно преимущество. Некоторые узлы очень популярны и действуют как хабы, например знаменитости в социальных сетях. С вычислительной точки зрения получение скрытых векторов этих узлов может быть очень затратным, поскольку требует расчета скрытых векторов тысяч или даже миллионов соседей. GraphSAGE исправляет эту ситуацию путем игнорирования большинства узлов.
В PyG выборка по соседям реализуется через объект NeighborLoader. Допустим, нам необходимо 5 соседей и 10 соседей этой пятерки (num_neighbors). Как обсуждалось ранее, мы можем определить batch_size для ускорения процесса путем создания подграфов для нескольких целевых узлов.
from torch_geometric.loader import NeighborLoader
from torch_geometric.utils import to_networkx
# Создание пакетов с помощью выборки по соседям
train_loader = NeighborLoader(
data,
num_neighbors=[5, 10],
batch_size=16,
input_nodes=data.train_mask,
)
# Вывод каждого подграфа
for i, subgraph in enumerate(train_loader):
print(f'Subgraph {i}: {subgraph}')
# Построение каждого подграфа
fig = plt.figure(figsize=(16,16))
for idx, (subdata, pos) in enumerate(zip(train_loader, ['221', '222', '223', '224'])):
G = to_networkx(subdata, to_undirected=True)
ax = fig.add_subplot(pos)
ax.set_title(f'Subgraph {idx}')
plt.axis('off')
nx.draw_networkx(G,
pos=nx.spring_layout(G, seed=0),
with_labels=True,
node_size=200,
node_color=subdata.y,
cmap="cool",
font_size=10
)
plt.show()
Subgraph 0: Data(x=[389, 500], edge_index=[2, 448], batch_size=16)
Subgraph 1: Data(x=[264, 500], edge_index=[2, 314], batch_size=16)
Subgraph 2: Data(x=[283, 500], edge_index=[2, 330], batch_size=16)
Subgraph 3: Data(x=[189, 500], edge_index=[2, 229], batch_size=12)

Мы создали 4 подграфа различного размера, что обеспечивает их параллельную обработку и соответствие вычислительным ресурсам GPU.
Количество соседей — важный показатель, так как отсечение графа удаляет большое количество информации, которое мы можем увидеть, просто посмотрев на степень узлов (количество соседей):
from torch_geometric.utils import degree
from collections import Counter
def plot_degree(data):
# Получение списка степеней для каждого узла
degrees = degree(data.edge_index[0]).numpy()
# Подсчет количества узлов для каждой степени
numbers = Counter(degrees)
# Построение столбчатой диаграммы
fig, ax = plt.subplots(figsize=(18, 6))
ax.set_xlabel('Node degree')
ax.set_ylabel('Number of nodes')
plt.bar(numbers.keys(),
numbers.values(),
color='#0A047A')
# Построение графика степеней узлов исходного графа
plot_degree(data)
# Построение графика степеней узлов конечного подграфа
plot_degree(subdata)

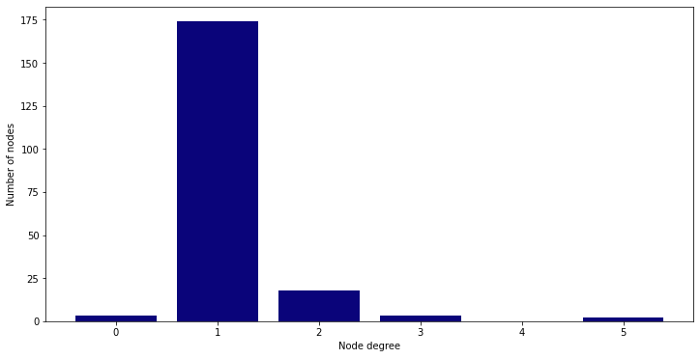
В этом примере максимальная степень узла подграфов — 5, что намного ниже начального максимального значения. Очень важно помнить про этот компромисс при работе с GraphSAGE.
PinSAGE использует другой способ выборки — метод случайного блуждания, у которого есть 2 главные функции.
- Выбрать определенное количество соседей (как и GraphSAGE).
- Получить их относительную значимость (важные узлы встречаются чаще, чем остальные).
Эта стратегия немного напоминает механизм быстрого внимания. Она присваивает узлам веса и повышает релевантность наиболее популярных из них.
Агрегация
Процесс агрегации определяет, как сочетать векторы признаков для получения вложений узла. В оригинальной документации представлены три способа агрегирования признаков:
- агрегатор средних значений;
- LSTM-агрегатор;
- агрегатор подвыборки.
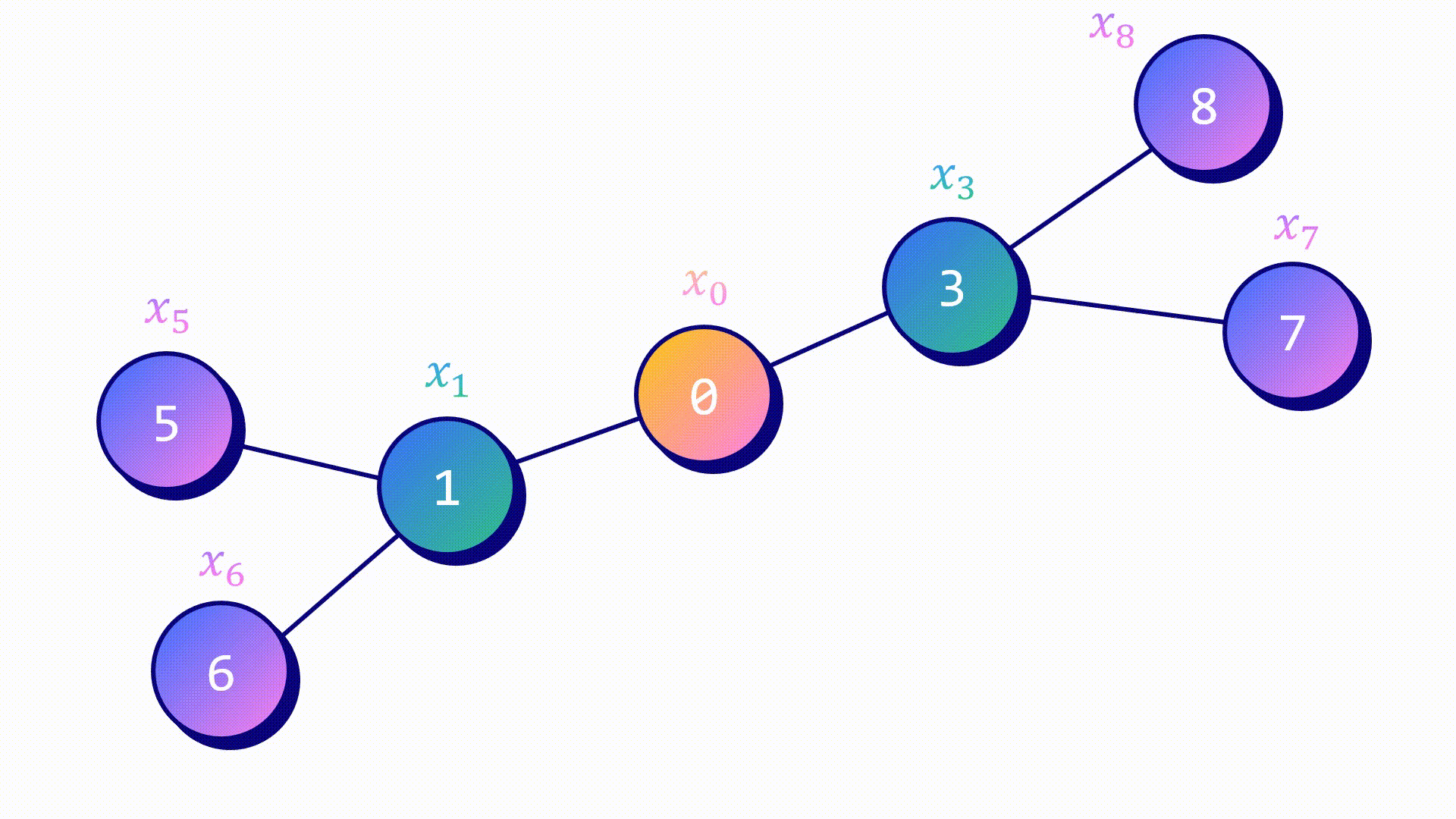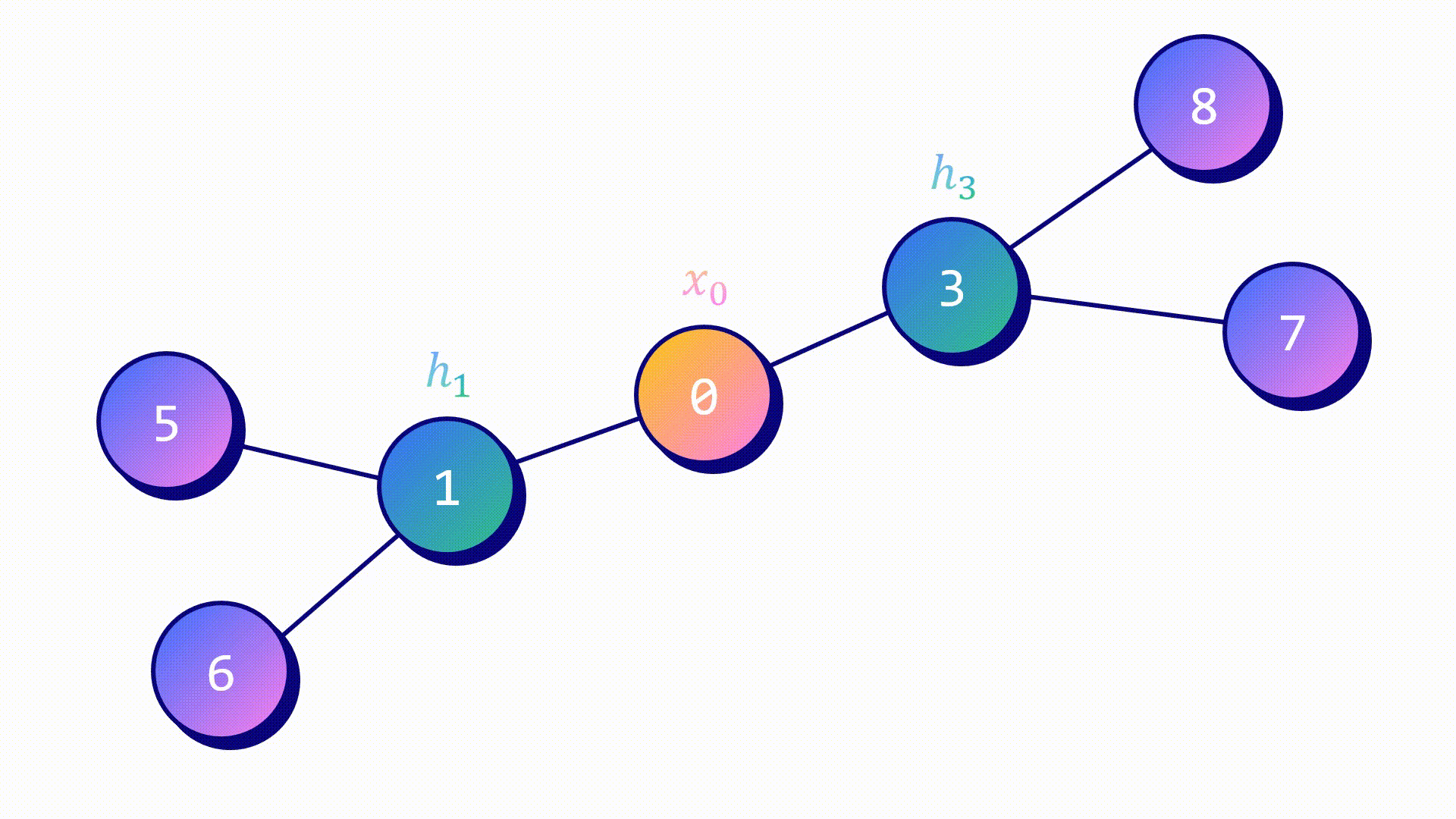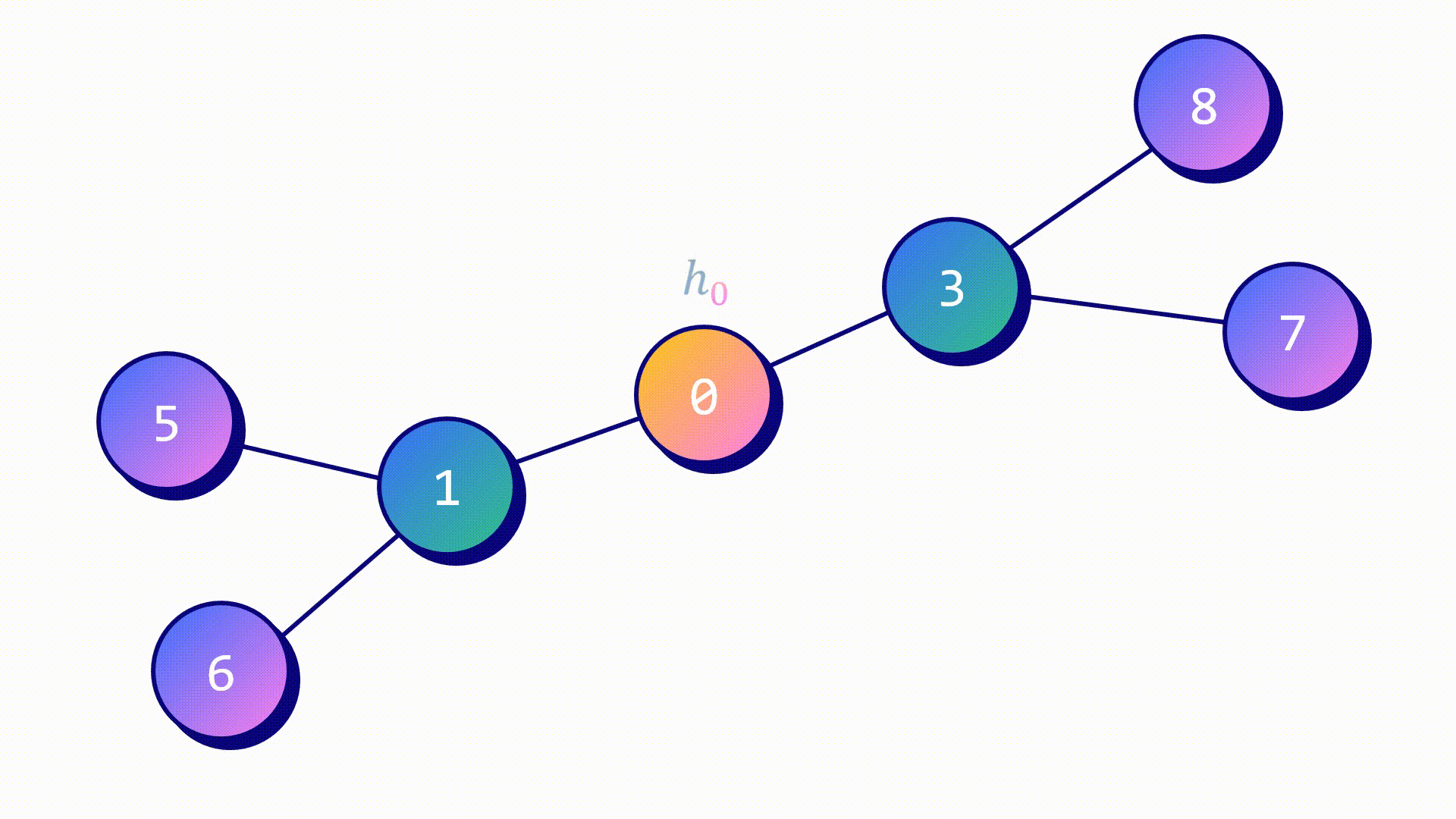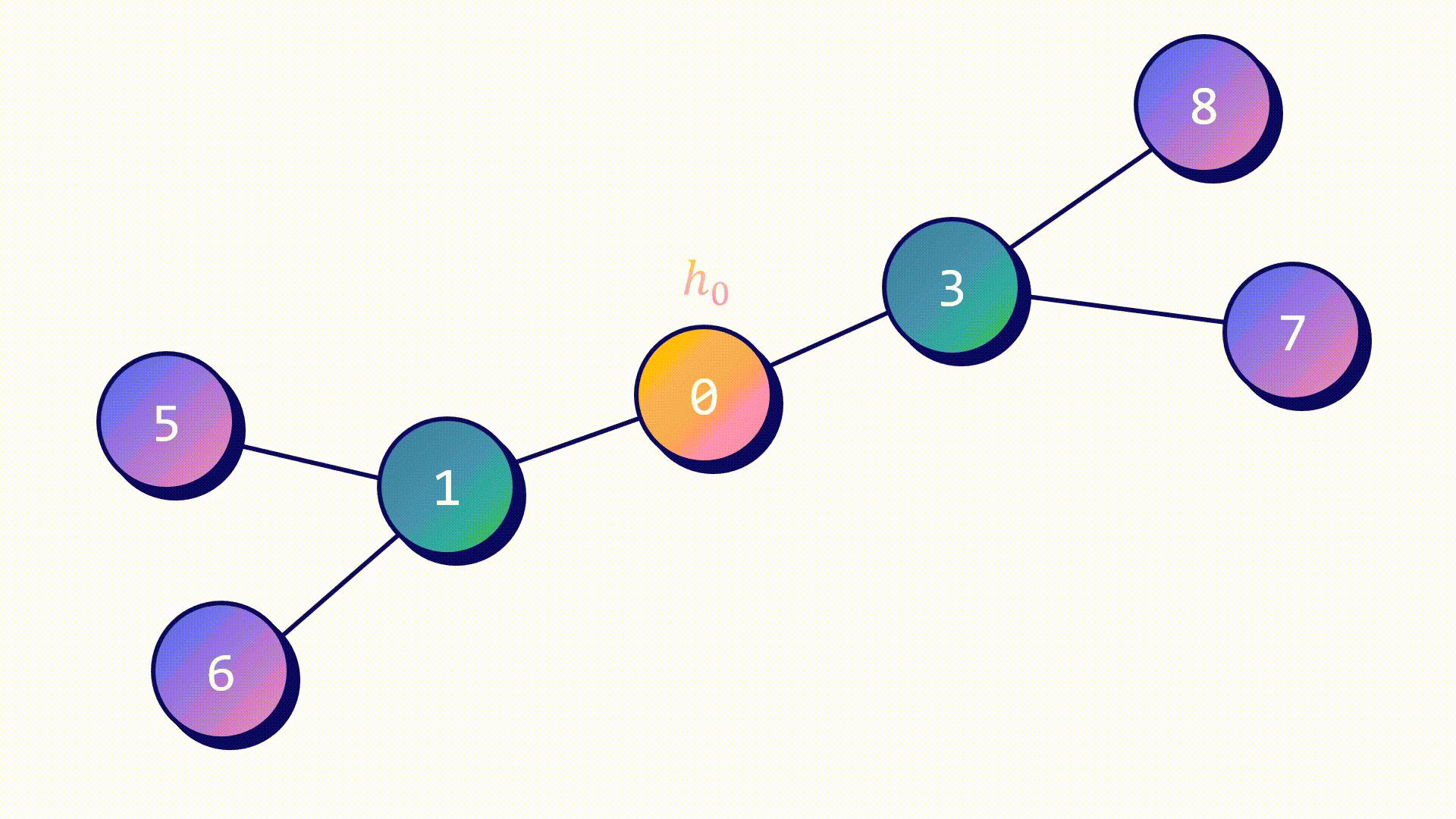
Агрегатор средних значений — самый простой из них. Метод работы похож на подход GCN.
- Скрытые признаки целевого узла hᵥ и его соседей hᵤ объединены.
- Итоговый вектор усреднен.
- Применена линейная трансформация с матрицей весов W.
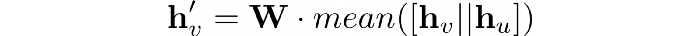
Затем результат можно передать в нелинейную функцию активации σ (например, tanh и ReLU). Эту технику мы будем использовать в PyG и именно ее выбрала компания UberEats.
Выбор LSTM-агрегатора может показаться странной идеей, так как его архитектура последовательна — он задает порядок для неорганизованных узлов. Поэтому авторы случайным образом перемешивают их, чтобы заставить LSTM учитывать только скрытые признаки. Эта техника показывает наилучшие результаты в сравнительных тестах.
Агрегатор подвыборки подает скрытый вектор каждого соседа в нейронную сеть с прямым распространением. К результату применяется операция подвыборки максимумов.
3. GraphSAGE в PyTorch Geometric
Мы легко можем встроить архитектуру GraphSAGE в PyTorch Geometric с помощью слоя SAGEConv. Это внедрение не совсем такое, как в документации, поскольку использует 2 матрицы вместо одной:
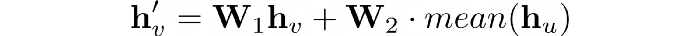
Создадим сеть с двумя слоями SAGEConv.
- Первый будет использовать ReLU в качестве функции активации и отсеивающего слоя.
- Второй будет напрямую выводить вложения узла.
Поскольку мы имеем дело с задачей классификации по множеству категорий, то будем использовать в качестве функции потерь кросс-энтропию.
Чтобы показать преимущества GraphSAGE, сравним его с GCN и GAT без применения выборки:
class GraphSAGE(torch.nn.Module):
"""GraphSAGE"""
def __init__(self, dim_in, dim_h, dim_out):
super().__init__()
self.sage1 = SAGEConv(dim_in, dim_h)
self.sage2 = SAGEConv(dim_h, dim_out)
self.optimizer = torch.optim.Adam(self.parameters(),
lr=0.01,
weight_decay=5e-4)
def forward(self, x, edge_index):
h = self.sage1(x, edge_index)
h = torch.relu(h)
h = F.dropout(h, p=0.5, training=self.training)
h = self.sage2(h, edge_index)
return h, F.log_softmax(h, dim=1)
def fit(self, data, epochs):
criterion = torch.nn.CrossEntropyLoss()
optimizer = self.optimizer
self.train()
for epoch in range(epochs+1):
acc = 0
val_loss = 0
val_acc = 0
# Обучение на пакетах
for batch in train_loader:
optimizer.zero_grad()
_, out = self(batch.x, batch.edge_index)
loss = criterion(out[batch.train_mask], batch.y[batch.train_mask])
acc += accuracy(out[batch.train_mask].argmax(dim=1),
batch.y[batch.train_mask])
loss.backward()
optimizer.step()
# Подтверждение соответствия
val_loss += criterion(out[batch.val_mask], batch.y[batch.val_mask])
val_acc += accuracy(out[batch.val_mask].argmax(dim=1),
batch.y[batch.val_mask])
# Вывод метрик каждые 10 эпох
if(epoch % 10 == 0):
print(f'Epoch {epoch:>3} | Train Loss: {loss/len(train_loader):.3f} '
f'| Train Acc: {acc/len(train_loader)*100:>6.2f}% | Val Loss: '
f'{val_loss/len(train_loader):.2f} | Val Acc: '
f'{val_acc/len(train_loader)*100:.2f}%')
В GraphSAGE мы просматриваем пакеты (4 подграфа), созданные процессом выборки по соседям. Из-за этого способ расчета точности и потерь при валидации также отличается.
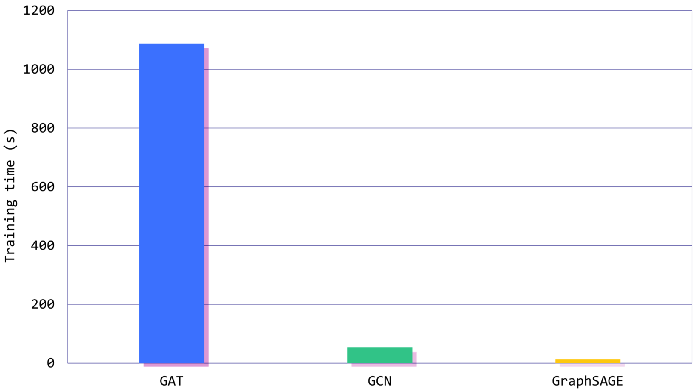
Вот результаты (с точки зрения точности и времени обучения) для GCN, GAT и GraphSAGE:
GCN test accuracy: 78.40% (52.6 s)
GAT test accuracy: 77.10% (18min 7s)
GraphSAGE test accuracy: 77.20% (12.4 s)
По показателям точности эти три модели имеют схожие результаты. Мы рассчитывали, что GAT покажет себя лучше, так как его механизм агрегации более детальный, но дело не всегда в этом.
Реальная разница заключается во времени обучения: в данном случае GraphSAGE в 88 раз быстрее GAT и в 4 раза быстрее, чем GCN.
Это и есть настоящая сила GraphSage. Мы теряем много информации, отсекая граф с помощью выборки по соседям. Последние вложения узла могут быть не такими хорошими, как при работе с GCN и GAT. Однако GraphSage создан для улучшения масштабируемости. В свою очередь, он может привести к построению графов больших размеров для лучшей точности.
Данная работа была выполнена с помощью контролируемого обучения (классификации узлов), но GraphSAGE можно обучать и без учителя.
В этом случае нельзя использовать потери кросс-энтропии. Мы должны разработать функцию потерь, которая бы заставляла узлы, находящиеся рядом в исходном графе, оставаться близко друг к другу в пространстве вложения. И наоборот, эта же функция должна гарантировать, что отдаленные узлы графа имеют такие же расстояния и в пространстве вложения. Это потери описываются в документации по работе с GraphSage.
Модификации GraphSage, такие как PinSAGE и та, что использует UberEats, направлены на систему рекомендаций.
Их задача состоит в том, чтобы ранжировать наиболее подходящие каждому пользователю элементы (пины, рестораны) несмотря на существенные отличия между ними. Нужно найти не только ближайшие вложения, но и максимально точно распределить их степень значимости. Вот почему эти системы также обучают без учителя, но с другой функцией потерь, которая измеряет относительное расстояние между точками входных данных.
Заключение
GraphSage — невероятно быстрая архитектура для обработки больших графов. Он может быть не так точен, как GCN и GAT, но его использование является важным при работе с большими объемами данных. Высокая скорость работы GraphSage достигается благодаря продуманной комбинации, состоящей из выборки по соседям для проряжения графа и быстрой агрегации. В данном примере использовался агрегатор средних значений.
В этой статье мы выполнили следующее.
- Изучили новый набор данных с помощью PubMed.
- Разобрали принцип работы метода выборки по соседям, который учитывает заранее определенное количество соседей в каждом переходе.
- Рассмотрели три агрегатора, представленных в документации по GraphSage, и сфокусировались на агрегаторе средних значений.
- Протестировали три модели (GraphSAGE, GAT и GCN) на точность и время обучения.
Comments