Мониторинг кластера Kubernetes без зависимостей

В настоящее время Kubernetes является ведущей платформой для развертывания приложений. Ее кластеры включают сотни ресурсов, таких как поды и развертывания. Kubernetes состоит из нескольких компонентов и определяемых пользователем операторов.
Многообразие сервисов, приложений и сетей, инкапсулированных в ресурсах, усложняет пользователям понимание рабочих процессов Kubernetes. Возникают самые разные вопросы:
- Что происходит внутри контейнера?
- Какой под выполняет указанные запросы?
- Почему запрос не выполняется успешно?
Из этого следует, что команда управления облачными сервисами должна постоянно наблюдать и контролировать состояние работоспособности ресурсов.
Наблюдаемость (англ. observability) включает 3 аспекта: логирование (англ. logging), трассировку (англ. tracing) и метрики (англ. metrics). Логирование проясняет операции приложения. Трассировка выявляет участки возникновения ошибок. Метрики отображают использование ресурсов кластера и общее рабочее состояние.
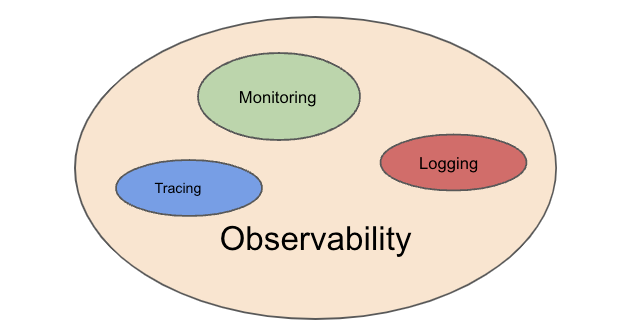
Наблюдаемость — одна из наиболее инвестируемых областей в сообществе фонда CNCF. На следующем изображении перечислены все проекты CNCF, касающиеся наблюдаемости. Большинство из них сам я раньше никогда не применял или не встречал.

Как правило, инструменты мониторинга собирают и агрегируют метрики. Но если нужно получить данные о том, как узлы, поды и контейнеры в кластере задействуют CPU и MEM, настоятельно рекомендую Murre, инструмент Go с открытым исходным кодом для мониторинга без зависимостей. С этими задачами он справляется лучше, чем все вышеперечисленные проекты.
Перед тем как приступить к изучению Murre, познакомимся с Prometheus + Grafana и командой kubectl Top. На их примерах мы рассмотрим, как функционируют инструменты мониторинга без зависимостей и в чем заключаются преимущества Murre.
Инструменты мониторинга без зависимостей
Prometheus + Grafana
Тандем Prometheus + Grafana представляет собой наиболее популярное решение для мониторинга Kubernetes. Оно помогает получать данные об использовании CPU и MEM соответствующего узла, например node_memory_Buffers_bytes:
Однако метрики Prometheus должны поочередно отображать каждый под/контейнер/узел, а разные ключи метрик для CPU и MEM не позволяют наглядно увидеть взаимосвязи между подом и контейнером.
Так, для наблюдения за MEM и CPU контейнера необходимо настроить container_memory_working_set_bytes и соответственно container_cpu_usage_seconds_total. Следует также отметить и крутость кривой обучения Prometheus, поскольку данный инструмент требует от пользователей знаний таких понятий, как ключи метрик и агрегированные функции (sum, rate и т.д.).
Prometheus и Grafana подразумевают установку и настройку. Кроме того, они слишком массивные и сложные в процессе мониторинга задействованных ресурсов.
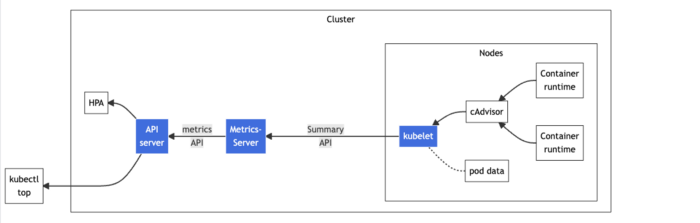
Kubectl Top
Классическая команда kubuctl top позволяет просматривать использование ресурсов узла/пода:
Эта команда требует, чтобы Metrics Server (пер. сервер метрик) был корректно настроен и работал на сервере.
Прежде всего, мы устанавливаем metrics-server, поскольку он не поставляется вместе с Kubernetes. Однако многие облачные провайдеры уже располагают им по умолчанию, поскольку он необходим для работы Horizontal Pod Autoscaler и Vertical Pod Autoscaler. Тем не менее ручная настройка кластера Kubernetes в любом случае требует установки metrics-server.
Мы можем по отдельности получать данные об использовании ресурсов с помощью kubectl top node и соответственно kubectl top pod:
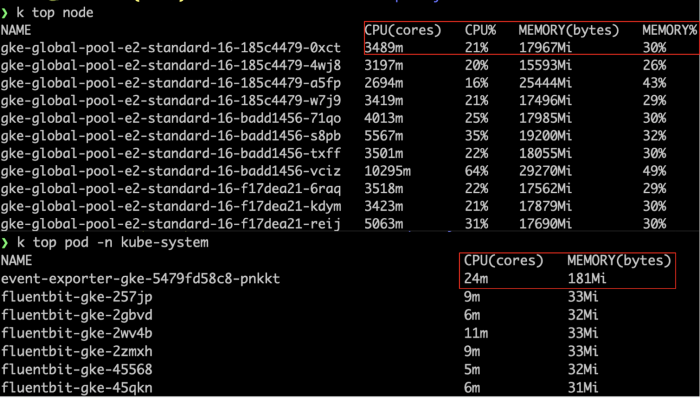
Отметим ряд недостатков. Один из них связан с тем, что успешное выполнение команды зависит от сервера метрик или же команда выбрасывает ошибку Metrics API not available (API метрик не доступен). А настройки по умолчанию, составляющие 100 милли-CPU и 200 МиБ памяти, бесперебойно работают только при наличии у кластера менее 100 и 70 подов на узел.
Другой недостаток заключается в том, что команда не показывает использование ресурсов контейнера, а каждый раз отображает только последние данные о задействованных ресурсах пода/узла и не имеет возможности постоянно обновляться.
Сбор метрик
В определенной степени и Prometheus, и kubectl top решают поставленные задачи. Но при более внимательном изучении мы увидим, что Prometheus зависит от kube-state-metrics, а kubectl top — от metrics-server, оба из которых применяют API метрик.
Отличаются же они тем, что metrics-server считывает данные на уровне кластера, а kube-state-metrics — данные для различных типов ресурсов, например развертываний и реплик.
Мониторинг без зависимостей с помощью Murre
Я активно работал с командой kubectl top, пока не познакомился с Murre, безусловно более эффективным инструментом без зависимостей с открытым исходным кодом.

Murre отображает информацию об использовании ресурсов подов и контейнеров в каждом пространстве имен и обновляет их в режиме реального времени. Он также поддерживает сортировку по CPU/MEM.
Единственное, что надлежит сделать — установить в кластер Murre, а не какие-либо зависимости. Поскольку он не зависит от APIServer, а получает информацию о подах/контейнерах в режиме реального времени через client-go, Murre форматирует и отображает полученные данные в терминале (по аналогии реализации плагинов kubectl). Процесс установки простой:
go install github.com/groundcover-com/[email protected]
Ниже представлена последовательность этапов технологического процесса Murre.
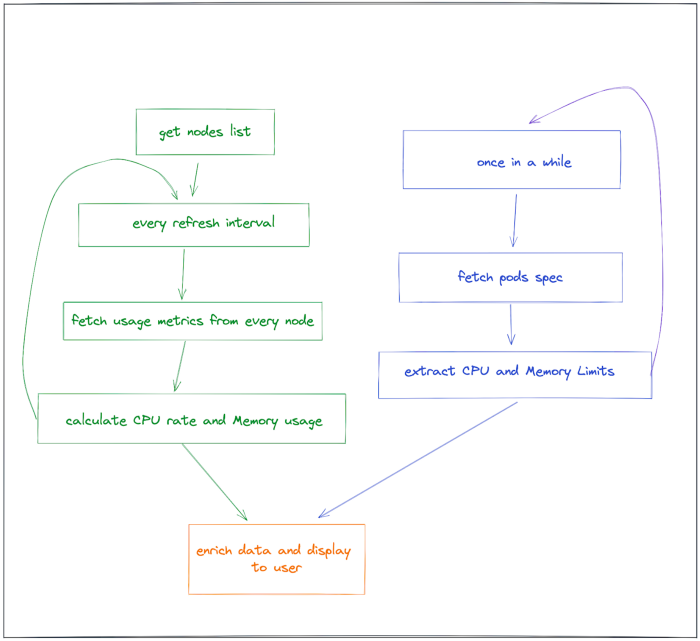
Зеленые блоки схемы сверху вниз: получение списка узлов → каждый интервал обновления → получение метрик от каждого узла → вычисление скорости CPU и использование памяти.
Синие блоки схемы сверху вниз: периодически → получение спецификации подов → извлечение ограничений CPU и памяти.
Оранжевый блок схемы: обновление и отображение данных пользователю.
Код не представляет сложности. Логика получения метрик следующая: применение функции GetContainers в fetcher.go, получение PodList и обход контейнеров:
func (f *Fetcher) GetContainers() ([]*ContainerResources, error) {
pods, err := f.clientset.CoreV1().Pods("").List(context.Background(), metav1.ListOptions{})
if err != nil {
return nil, err
}
containers := make([]*ContainerResources, 0)
for _, pod := range pods.Items {
for _, container := range pod.Spec.Containers {
requestCpu := container.Resources.Requests.Cpu()
requestMemory := container.Resources.Requests.Memory()
limitCpu := container.Resources.Limits.Cpu()
limitMemory := container.Resources.Limits.Memory()
containerResource := &ContainerResources{
PodName: pod.Name,
Name: container.Name,
Namespace: pod.Namespace,
Image: container.Image,
Request: Resources{
Cpu: 0,
Memory: 0,
},
Limit: Resources{
Cpu: 0,
Memory: 0,
},
}
if requestCpu != nil {
containerResource.Request.Cpu = float64(requestCpu.MilliValue())
}
if requestMemory != nil {
containerResource.Request.Memory = float64(requestMemory.Value())
}
if limitCpu != nil {
containerResource.Limit.Cpu = float64(limitCpu.MilliValue())
}
if limitMemory != nil {
containerResource.Limit.Memory = float64(limitMemory.Value())
}
containers = append(containers, containerResource)
}
}
return containers, nil
}Регулярные обновления выполняются с помощью функции Go timer.Ticker + select и настраиваются посредством параметра --interval:
func (m *Murre) Run() error {
// первый повтор действия
err := m.tick()
if err != nil {
return err
}
ticker := time.NewTicker(m.config.RefreshInterval)
for {
select {
case <-ticker.C:
err := m.tick()
if err != nil {
return err
}
case <-m.stopCh:
return nil
}
}
}Заключение
В статье мы рассмотрели и сравнили 2 вида мониторинга Kubernetes: с зависимостями и без. Murre — эффективный инструмент для наблюдения за использованием ресурсов подов и контейнеров без установки зависимостей в кластере. Хотя он все еще находится на начальном этапе разработки и ожидает усовершенствования, можно предвидеть дальнейшее расширение его возможностей за счет добавления дополнительных функций, таких как отображение метрик развертываний, реплик, APIServer и т.д.
Comments