Как создать на Python скринер акций и выполнить анализ настроений на основе ИИ

Поиск акций для инвестирования может оказаться долгим и утомительным. А что, если использовать ИИ и Python для создания программы, способной ускорить этот процесс? В этой статье я расскажу, как применить Python-библиотеку finvizfinance для поиска “недооцененных” акций. Затем представлю метод анализа настроений с помощью FinBERT, предварительно обученной NLP-модели, позволяющей анализировать эти “недооцененные” акции.
Первые шаги
Прежде всего импортируем необходимые библиотеки. Сайт finviz.com предлагает различные инструменты для анализа акций, в том числе бесплатный скринер акций (Screener). Импортируем объект скринера finvizfinance, который возвращает DataFrame Pandas с результатами скрининга в разделе “Overview” (“Обзор”).
from finvizfinance.screener.overview import Overview
Теперь импортируем библиотеки Pandas, csv и os, которые используются в основном для работы с csv-файлами.
import pandas as pd
import csv
import os
Скрининг потенциальных акций
Теперь, следуя подходу стоимостного инвестирования, необходимо составить список потенциально недооцененных акций, к которым стоит присмотреться. Для этого надо создать функцию, которая использует библиотеку finvizfinance для отправки запроса к онлайн-скринеру акций. Вот функция, которая будет выполнять это:
def get_undervalued_stocks():
"""
Returns a list of tickers with:
- Positive Operating Margin
- Debt-to-Equity ratio under 1
- Low P/B (under 1)
- Low P/E ratio (under 15)
- Low PEG ratio (under 1)
- Positive Insider Transactions
"""
foverview = Overview()
Как инвесторы, применяющие стоимостную стратегию, ищем акции с низким Price-to-Book (P/B) — показателем остаточной стоимости основного капитала. Он означает, что цена акций ниже стоимости активов компании, а значит, акции недооценены — при условии, что компания не испытывает финансовых трудностей. Ищем также Operating Margin — маржу операционной прибыли, которая является верным показателем того, насколько успешно управляется компания и насколько эффективно генерирует прибыль от продаж. Кроме того, необходимо, чтобы соотношение долгосрочных обязательств к собственному капиталу компании (Debt-to-Equity ratio) было меньше 1, что позволяет отнести ее к компаниям с низким уровнем риска.
Еще одним полезным показателем является Price-to-Earnings (P/E) — актуальное отношение цены к прибыли, которое должно быть ниже среднего значения. Таким образом, нам нужны как низкий P/E, так и низкий Price-to-Earnings Growth (PEG) — коэффициент роста цены к прибыли. Коэффициент P/E выражает отношение цены акций компании к ее прибыли на акцию, поэтому высокий коэффициент P/E может означать, что компания “переоценена”.
Наконец, ищем положительные инсайдерские сделки (Insider Trans), то есть сделки с участием руководителей компаний (инсайдеров), покупающих акции своих же компаний. Менеджеры и директора обладают инсайдерской информацией о компаниях, которыми руководят. Поэтому перспективы компаний, акции которых покупают инсайдеры, выглядят благоприятно.
filters_dict = {'Debt/Equity':'Under 1',
'PEG':'Low (<1)',
'Operating Margin':'Positive (>0%)',
'P/B':'Low (<1)',
'P/E':'Low (<15)',
'InsiderTransactions':'Positive (>0%)'}Помните, что эти параметры не являются всеобъемлющими: их набор должен ориентироваться на отрасль и специфику бизнеса, может быть сугубо ограниченным или сильно расширенным. Понимание бизнеса, в который вы хотите инвестировать, важно для использования стоимостного подхода к инвестированию. Словом, вам нужно определить собственную стратегию поиска акций и выбрать индивидуальные параметры. Ниже приведен список всех возможных параметров для бесплатного онлайн-скринера акций FINVIZ.com:
parameters = ['Exchange', 'Index', 'Sector', 'Industry', 'Country', 'Market Cap.',
'P/E', 'Forward P/E', 'PEG', 'P/S', 'P/B', 'Price/Cash', 'Price/Free Cash Flow',
'EPS growththis year', 'EPS growthnext year', 'EPS growthpast 5 years', 'EPS growthnext 5 years',
'Sales growthpast 5 years', 'EPS growthqtr over qtr', 'Sales growthqtr over qtr',
'Dividend Yield', 'Return on Assets', 'Return on Equity', 'Return on Investment',
'Current Ratio', 'Quick Ratio', 'LT Debt/Equity', 'Debt/Equity', 'Gross Margin',
'Operating Margin', 'Net Profit Margin', 'Payout Ratio', 'InsiderOwnership', 'InsiderTransactions',
'InstitutionalOwnership', 'InstitutionalTransactions', 'Float Short', 'Analyst Recom.',
'Option/Short', 'Earnings Date', 'Performance', 'Performance 2', 'Volatility', 'RSI (14)',
'Gap', '20-Day Simple Moving Average', '50-Day Simple Moving Average',
'200-Day Simple Moving Average', 'Change', 'Change from Open', '20-Day High/Low',
'50-Day High/Low', '52-Week High/Low', 'Pattern', 'Candlestick', 'Beta',
'Average True Range', 'Average Volume', 'Relative Volume', 'Current Volume',
'Price', 'Target Price', 'IPO Date', 'Shares Outstanding', 'Float']
Когда фильтры скринера будут настроены, можно подключиться к API скринера finviz и собрать нужные данные.
foverview.set_filter(filters_dict=filters_dict)
df_overview = foverview.screener_view()
if not os.path.exists('out'): #обеспечивает готовность папки 'out'
os.makedirs('out')
df_overview.to_csv('out/Overview.csv', index=False)
tickers = df_overview['Ticker'].to_list()
return tickers
#print(get_undervalued_stocks())
Запуск приведенной выше программы (если раскомментировать последнюю строку) выводит список тикеров, который поможет сформировать список отслеживания при условии проведения последующего анализа. Чтобы избежать поспешных выводов, потратьте какое-то время на изучение компаний “вручную”, например сосредоточьтесь на информации о прибылях и убытках или балансовых отчетах.
['AMPY', 'BOOM', 'BWB', 'CAAS', 'CNX', 'HAFC', 'HTLF', 'SASR', 'SPNT', 'TCBX']
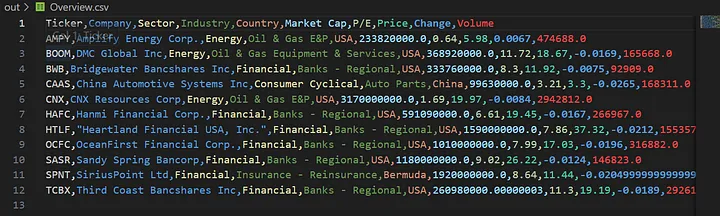
В папке “out” в csv-файле будет находиться Overview — обзор всех отслеживаемых акций.
Использование финансовой модели BERT для проведения анализа настроений
Теперь у нас есть список “недооцененных” акций, в которые можно инвестировать. Однако важно также знать, как представители масс-медиа относятся к компании и, что еще важнее, к самим акциям. Разумеется, толковый инвестор, применяющий стоимостную стратегию, не должен руководствоваться стадным чувством. Однако стоит иметь представление о перспективах акций: это поможет в оценке первопричины их стоимости, будь то пере- или недооцененность.
Таким образом, нужно написать программу, способную получить список последних новостных статей, относящихся к каждой акции, с которой работает скринер акций. Эта программа выведет заголовки статей, даты их публикации и общее настроение, переданное в статье, что позволит легко получить представление об общем настроении по отношению к акции.
Начало работы
Прежде всего импортируем необходимые зависимости.
Библиотека transformers предоставляет тысячи предварительно обученных моделей для выполнения задач на различных модальностях, таких как текст, зрение и аудио. Для анализа настроений финансовых новостных статей будем использовать предварительно обученную модель FinBERT от ProsusAI. Эта модель создана путем дальнейшего обучения BERT, языковой модели Google, в области финансов. BERT (bit error rate tester) — тестер измерения вероятности битовых ошибок.
from transformers import pipeline
Для загрузки новостей о рыночных данных из API Yahoo! Finance будем использовать Python-библиотеку yfinance.
import yfinance as yf
Теперь импортируем Goose (экстрактор HTML-контента/статей, веб-скрейпинг для Python3), а также метод get из библиотеки requests для отправки HTTP-запросов и получения данных из статей с финансовыми новостями.
from goose3 import Goose
from requests import get
Получение данных из финансовых новостных статей
Определим функцию, которая принимает на входе тикер и возвращает DataFrame Pandas, содержащий 3 столбца: Publishing date (Дата публикации), Article title (Заголовок статьи) и Article sentiment (Настроение статьи).
Модуль Ticker позволит получить список последних финансовых новостей по заданному тикеру. Затем инстанцируем экстрактор статей Goose и конвейер для предварительно обученной NLP-модели.
def get_ticker_news_sentiment(ticker):
"""
Returns a Pandas dataframe of the given ticker's most recent news article headlines,
with the overal sentiment of each article.
Args:
ticker (string)
Returns:
pd.DataFrame: {'Date', 'Article title', Article sentiment'}
"""
ticker_news = yf.Ticker(ticker)
news_list = ticker_news.get_news()
extractor = Goose()
pipe = pipeline("text-classification", model="ProsusAI/finbert")
Вызов метода get_news() возвращает список словарей. Каждый из них содержит информацию о новостной статье, включая ссылку на нее и ее заголовок. Для каждого словаря (статьи) в списке отправим запрос на ссылку на статью, а затем извлечем ее текст и дату с помощью экстрактора Goose.
Если текст статьи содержит более 512 слов, то длина последовательности индексов токенов превысит максимальную длину последовательности, установленную для модели FinBERT. Прогон такой последовательности через модель приведет к ошибкам индексирования. Хотя существует метод проведения анализа настроений для длинных текстов с более чем 512 токенами, в рамках данной статьи он рассматриваться не будет.
При прохождении текста через конвейер модель выдает многопеременную логистическую функцию (softmax) для трех меток: положительной (positive), отрицательной (negative) или нейтральной (neutral). Возвращается метка с наибольшей вероятностью. Она передает общее доминирующее настроение данного текста.
Наконец, эта функция преобразует список ‘data’ в DataFrame Pandas и возвращает его:
data = []
for dic in news_list:
title = dic['title']
response = get(dic['link'])
article = extractor.extract(raw_html=response.content)
text = article.cleaned_text
date = article.publish_date
if len(text) > 512:
data.append({'Date':f'{date}',
'Article title':f'{title}',
'Article sentiment':'NaN too long'})
else:
results = pipe(text)
#вывод (результаты)
data.append({'Date':f'{date}',
'Article title':f'{title}',
'Article sentiment':results[0]['label']})
df = pd.DataFrame(data)
return df
Применим эту новую функцию к тикерам, полученным ранее. Для начала понадобится небольшая вспомогательная функция, которая преобразует новостные настроения тикера Pandas DataFrame в csv-файл, хранящийся в каталоге “out”.
def generate_csv(ticker):
get_ticker_news_sentiment(ticker).to_csv(f'out/{ticker}.csv', index=False)
Теперь вызовем эту функцию для каждого тикера, полученного ранее:
undervalued = get_undervalued_stocks()
for ticker in undervalued:
generate_csv(ticker)
Это создаст или обновит каталог “out” с файлом Overview, содержащим общие данные по всем “недооцененным” акциям, и csv-файлом для каждого тикера с кратким обзором последних настроений в отношении акций.
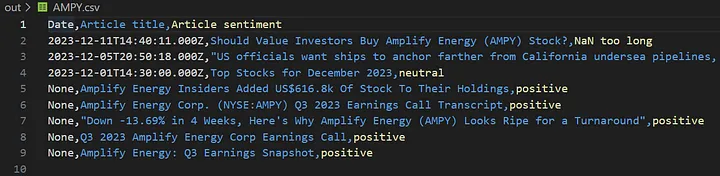
Согласитесь, прочитав только заголовки финансовых статей об инсайдерских сделках Amplify Energy (AMPY), нетрудно предположить, что и другие также будут считать “недооцененными” акции этой компании.
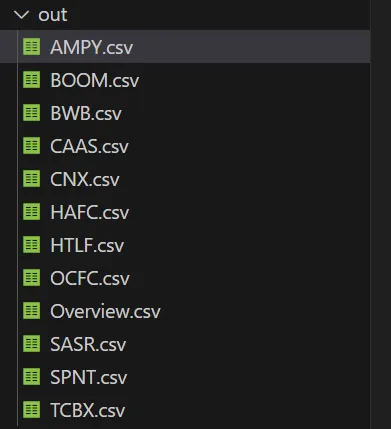
Итак, мы выполнили все задачи. Запустив программу, получили список “недооцененных” акций с их обзором и список статей с последними финансовыми новостями с их общим настроением.
Comments