Как Meta оптимизировала согласованность кэша до 99,99999999

Введение
Кэширование — мощная техника, используемая в различных аспектах компьютерных систем, начиная с аппаратного обеспечения, такого как кэш-память, и заканчивая операционными системами, веб-браузерами и особенно бэкенд-разработкой. Для компаний типа Meta кэширование очень важно, поскольку помогает сократить задержки, масштабировать большие рабочие нагрузки и экономить деньги. Однако использование в сценариях компании большого объема кэша создает такую проблему, как инвалидация кэша.
За годы работы Meta улучшила показатель согласованности кэша с 99,9999 (шесть девяток) до 99,99999999 (10 девяток). Это означает, что в кэш-кластерах компании может быть несогласованной менее 1 из 10 миллиардов кэш-записей.
Инвалидация и согласованность кэша
По определению, кэш не является источником истины для ваших данных. Поэтому требуется процесс активной инвалидации (удаления/обновления) устаревших записей в кэше при изменении данных в источнике истины. Если в процессе инвалидации записи будут неправильно обработаны, в кэше на неопределенное время могут остаться противоречивые значения, отличающиеся от тех, что содержатся в источнике истины.
Как же инвалидировать кэш?
Можно для поддержания его актуальности использовать что-то вроде TTL (time-to-live — стратегия, при которой указывается время жизни данных в кэше), чтобы не допустить инвалидации кэша какой-либо другой системой. Но в этой статье, где обсуждается согласованность кэша Meta, будем предполагать, что инвалидация кэша выполняется чем-то другим, а не самим кэшем.
Для начала посмотрим, как может возникнуть несогласованность кэша:
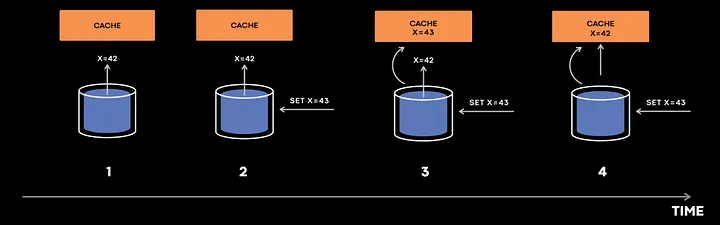
Предположим, что 1, 2, 3 и 4 — это временные метки в возрастающей последовательности.
- Сначала кэш пытается заполнить значение из БД.
- Но прежде чем значение x=42 попадет в кэш, какая-то операция обновила БД до значения x=43.
- БД посылает событие инвалидации кэша для x=43, которое поступает в кэш раньше, чем x=42, и значение кэша устанавливается на 43.
- Теперь в кэш приходит событие x=42, и в кэше устанавливается значение 42, что приводит к возникновению несоответствия.
Для устранения этой проблемы можно использовать поле version, чтобы более старая версия никогда не переопределяла текущую. Такое решение приемлемо почти для 99% компаний, имеющих веб-платформы. Но учитывая масштабы операционной деятельности Meta, даже этого может быть недостаточно из-за сложности системы.
Почему Meta так заботится о согласованности кэша?
С точки зрения Meta, несогласованность кэша — почти то же самое, что потеря данных в базе данных. С точки зрения пользователей, подобная проблема может привести к резкому снижению качества взаимодействия с платформой.
Когда вы отправляете пользователю соцсети личное сообщение, система сопоставляет его с сообщениями для этого пользователя, содержащимися в первичном хранилище.
Представим трех пользователей Meta: Боба, Мэри и Алису. Боб и Мэри отправляют Алисе по сообщению. Боб находится в США, Алиса — в Европе, а Мэри — в Японии. Поэтому система запросит регион, ближайший к тому, где живет пользователь, и отправит сообщение в хранилище данных Алисы. Если у Боба и Мэри будут несогласованные данные, реплика TAO (The Associations and Objects — распределенное хранилище данных пользователей в Meta), запросив регион, где живут Боб и Мэри, отправит сообщение в регион, в котором не будет сообщений Алисы.
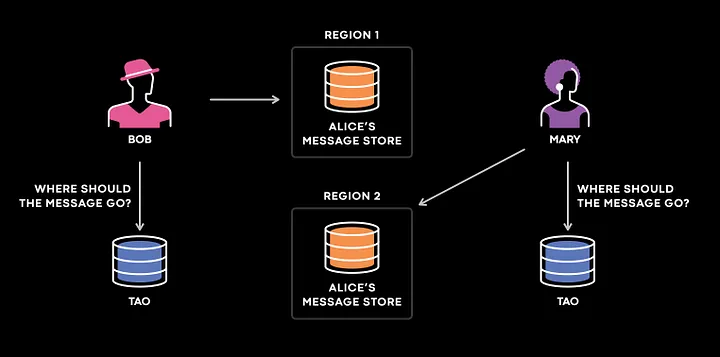
В этом случае произошла бы потеря сообщений, что привело бы к снижению качества взаимодействия пользователей, поэтому данная проблема была одной из основных для решения в компании Meta.
Мониторинг
Первым шагом на пути решения проблемы инвалидации и согласованности кэша должно стать измерение. Если точно измерить согласованность кэша, можно подать сигнал тревоги при наличии несогласованных кэш-записей. Meta позаботилась о том, чтобы ее измерения не содержали ложных срабатываний, поскольку дежурные инженеры научились бы игнорировать их, а метрика потеряла бы доверие и стала бы бесполезной.
Прежде чем погрузиться в решение, которое реализовала Meta, отметим, что самым простым выходом было бы регистрировать и отслеживать каждое изменение состояния кэша. Такое решение было бы целесообразно в случае небольших рабочих нагрузок. Но система Meta выполняет более 10 триллионов заполнений кэша в день. Логирование и отслеживание всех состояний кэша превратило бы большую нагрузку на кэш в чрезвычайно тяжелую (уже не говоря о том, какие усилия понадобились бы на отладку всего этого).
Polaris
Polaris на очень высоком уровне взаимодействует с сервисом отслеживания состояний как клиент, не предполагая никаких знаний о внутреннем устройстве сервиса. Polaris работает по принципу: “Кэш в конечном итоге должен быть согласован с базой данных”. Polaris получает событие об инвалидации и запрашивает все реплики, чтобы проверить, не произошло ли других нарушений.
Рассмотрим такой пример. Polaris получает событие инвалидации, в котором говорится следующее: “x=4, версия 4”. Он проверяет все реплики кэша как клиент, чтобы убедиться, не произошло ли нарушение какого-либо инварианта. Если одна из реплик возвращает “x=3, @ версия 3”, Polaris помечает ее как несогласованную и запрашивает образец, чтобы позже проверить его на том же целевом хосте кэша. Polaris сообщает о несоответствиях на определенных временных интервалах, например через 1 минуту, 5 минут или 10 минут.
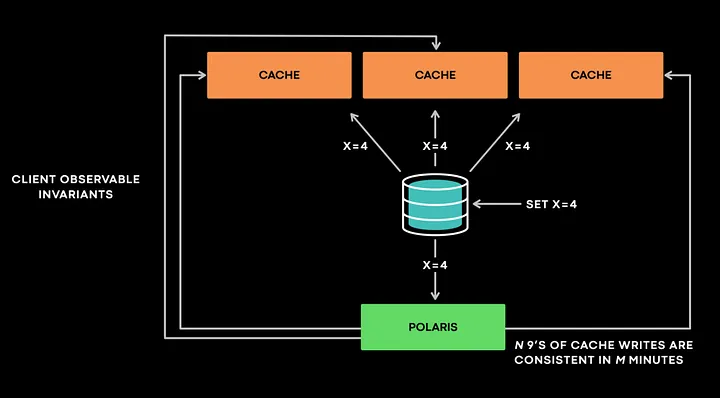
Такой дизайн со множеством временных шкал не только позволяет Polaris иметь несколько внутренних очередей для эффективной реализации отката и повторных попыток, но и необходим для предотвращения ложных срабатываний.
Рассмотрим это на еще одном примере.
Предположим, Polaris получает инвалидацию “x = 4, версия 4”. Но когда Polaris проверяет кэш, он не может найти запись для x, и это должно быть отмечено как несоответствие. В этом случае возможны два варианта:
- x был невидим в версии 3, но запись в версии 4 является последней записью в ключе, и это действительно несоответствие в кэше.
- Вероятно, существует запись версии 5, которая удаляет ключ x, и, возможно, Polaris просто видит представление данных, более актуальное, чем то, что содержится в событии инвалидации.
Итак, как убедиться, что один из двух случаев правильный?
Чтобы проверить, какой из двух случаев верный, Polaris должен выполнить запрос к базе данных. Запросы в обход кэша могут быть вычислительно трудоемкими и подвергать базу данных риску, поскольку защита базы данных и масштабирование тяжелых рабочих нагрузок — два наиболее распространенных случая использования кэша. Поэтому нельзя отправлять в систему слишком много запросов.
Polaris решает эту проблему, откладывая выполнение таких проверок и делая обращение к базе данных до тех пор, пока выборка с несогласованными данными не пересечет установленный порог, например 1 минуту или 5 минут. Polaris создает метрику, которая показывает: “N девяток кэш-записей являются согласованными за M минут”. Таким образом, сейчас Polaris предоставляет метрику, которая показывает, что 99,99999999 кэш-записей являются согласованными для 5-минутной шкалы времени.
Теперь посмотрим, как Polaris помог Meta исправить ошибку и как могут возникать несогласованности в кэше.
Разобраться в этом поможет пример с фрагментами кода.
Предположим, что кэш поддерживает сопоставление ключей с метаданными и сопоставление ключей с версиями.
cache_data = {}
cache_version = {}
meta_data_table = {"1": 42}
version_table = {"1": 4}1. Когда приходит запрос на чтение, значение сначала проверяется в кэше. Если значение отсутствует в кэше, то оно возвращается из базы данных.
def read_value(key):
value = read_value_from_cache(key)
if value is not None:
return value
else:
return meta_data_table[key]
def read_value_from_cache(key):
if key in cache_data:
return cache_data[key]
else:
fill_cache_thread = threading.Thread(target=fill_cache(key))
fill_cache_thread.start()
return None
2. Кэш возвращает результат None и затем начинает заполнять кэш из базы данных (я использовал потоки, чтобы сделать этот процесс асинхронным).
def fill_cache(key):
fill_cache_metadata(key)
fill_cache_version(key)
def fill_cache_metadata(key):
meta_data = meta_data_table[key]
print("Filling cache meta data for", meta_data)
cache_data[key] = meta_data
def fill_cache_version(key):
time.sleep(2)
version = version_table[key]
print("Filling cache version data for", version)
cache_version[key] = version
def write_value(key, value):
version = 1
if key in version_table:
version = version_table[key]
version = version + 1
write_in_databse_transactionally(key, value, version)
time.sleep(3)
invalidate_cache(key, value, version)
def write_in_databse_transactionally(key, data, version):
meta_data_table[key] = data
version_table[key] = version
3. Тем временем, пока данные версии заполняют кэш, в базу данных поступает новый запрос на запись, обновляющий значение метаданных и значение версии. В данный момент подобное выглядит как ошибка, но это не так, поскольку инвалидация кэша должна вернуть кэш в согласованное состояние с базой данных (я добавил функцию time.sleep в кэш и write в функцию базы данных, чтобы воспроизвести проблему).
def invalidate_cache(key, metadata, version):
try:
cache_data = cache_data[key][value] ## To produce error
except:
drop_cache(key, version)
def drop_cache(key, version):
cache_version_value = cache_version[key]
if version > cache_version_value:
cache_data.pop(key)
cache_version.pop(key)
read_thread = threading.Thread(target=read_value, args=("1"))
write_thread = threading.Thread(target=write_value, args=("1",43))
print_thread = threading.Thread(target=print_values)4. Позже во время инвалидации кэша по какой-то причине не удалось выполнить инвалидацию, и перед обработчиком исключений было поставлено условие, при котором произошел сброс кэша.
Логика функции сброса кэша заключается в том, что если последнее значение больше значения cache_version_value, то ключ удаляется, но в нашем случае это не так. Устаревшие метаданные остаются в кэше на неопределенное время.
Имейте в виду, что это очень упрощенный случай возникновения ошибки. В действительности ситуация с возникновением ошибок еще более запутанная, с репликацией базы данных и межрегиональным взаимодействием. Ошибка запускается, только когда происходят все вышеперечисленные шаги и именно в такой последовательности. Несогласованность возникает очень редко. Проблемы скрываются в коде обработки ошибок за чередующимися операциями и ошибками во время переходных процессов.
Отслеживание несогласованностей
Теперь, когда вы получили сообщение о несогласованностях в кэше от Polaris, очень важно проверить логи и выяснить, где может быть проблема. Как уже было замечено, логировать каждое изменение данных кэша практически невозможно, но что, если регистрировать только то, что потенциально способно привести к изменению?
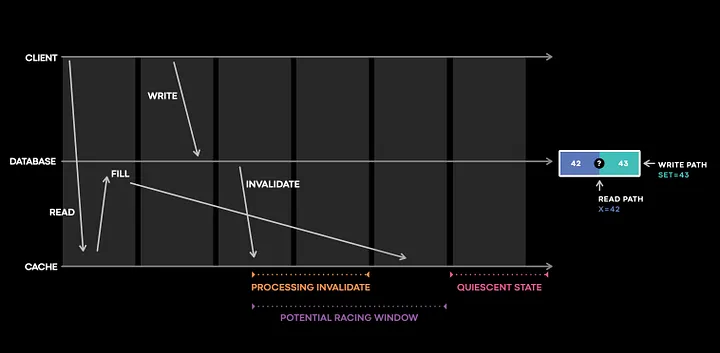
Если посмотреть на приведенный выше код, который мы реализовали, то проблема может возникнуть в том случае, если кэш не получил событие инвалидации или инвалидация не сработала. С точки зрения дежурного инженера, нужно проверить следующее:
- Получил ли кэш-сервер событие инвалидации?
- Правильно ли сервер обработал инвалидацию?
- Стал ли элемент после этого несогласованным?
Meta создала библиотеку отслеживания состояния, которая регистрирует и мониторит мутации кэша в маленьком фиолетовом окне, где видно, как интересные и сложные взаимодействия вызывают ошибки, приводящие к несогласованности кэша.
Заключение
Любым распределенным приложениям нужны надежные системы мониторинга и логирования. Они позволяют отслеживать ошибки и быстро находить их первопричины, чтобы устранить проблему. Пример с Meta продемонстрировал, как Polaris определил аномалию и немедленно подал сигнал тревоги. Благодаря информации, полученной в результате отслеживания согласованности, дежурным инженерам потребовалось менее 30 минут, чтобы обнаружить ошибку.
Comments