Продвинутая генерация ответа, дополненная результатами поиска (RAG): от теории до реализации на LlamaIndex
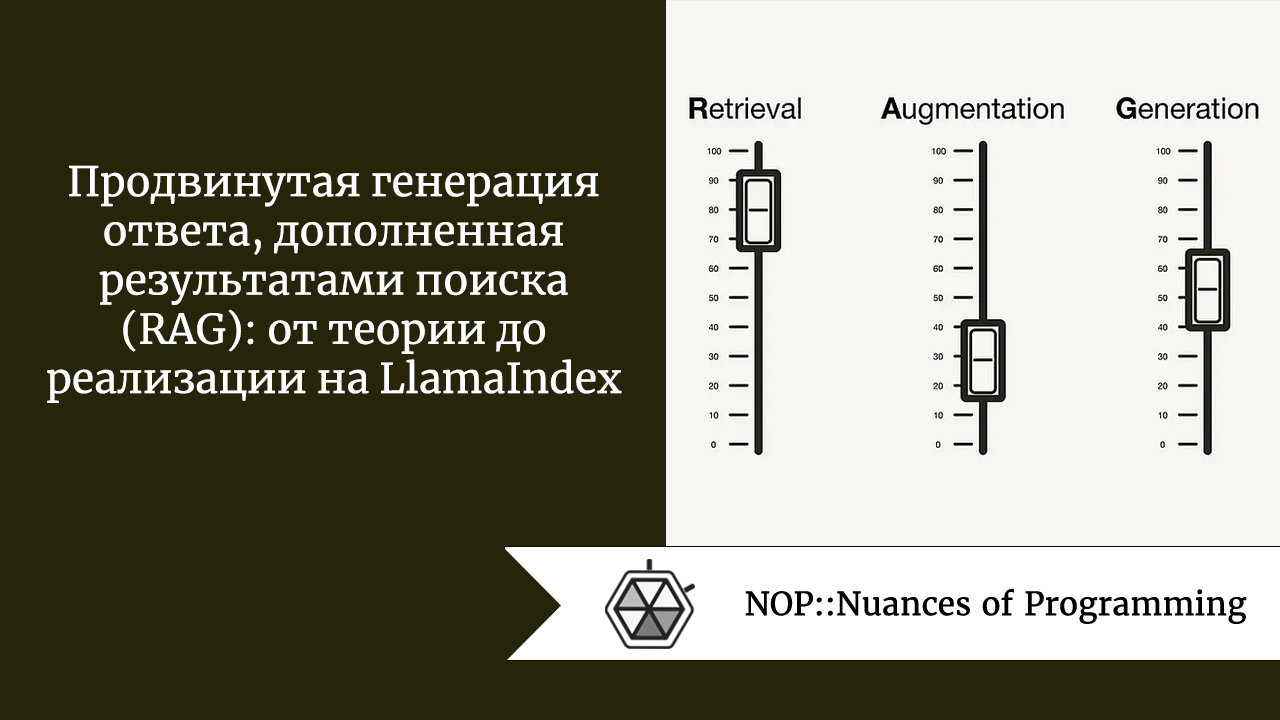
В последнем научном обзоре генерации ответа, дополненной результатами поиска (RAG), были выведены три недавно наметившиеся парадигмы RAG:
- простая (Naive);
- продвинутая (Advanced);
- модульная (Modular).
Продвинутая парадигма RAG включает набор методик, направленных на устранение известных ограничений простой системы RAG. Рассмотрим эти методики, определив их как способы оптимизации перед извлечением, при извлечении и после извлечения данных.
Во второй половине статьи вы узнаете, как реализовать простой RAG-пайплайн с помощью Llamaindex на Python, который затем будет усовершенствован до продвинутого RAG-пайплайна с использованием методик, расширяющих возможности RAG:
- Оптимизация перед извлечением данных (Pre-retrieval optimization): поиск по окну предложений.
- Оптимизация извлечения данных (Retrieval optimization): гибридный поиск.
- Оптимизация после извлечения данных (Post-retrieval optimization): повторное ранжирование.
Эта статья посвящена продвинутой парадигме RAG и ее реализации. Для ознакомления с основами RAG прочтите предыдущую статью.
Что такое продвинутая RAG
В свете последних достижений в области генеративного ИИ продвинутая RAG стала новой парадигмой с методиками, целенаправленно расширяющими возможности извлечения информации и устраняющими ограничения простой парадигмы RAG. Как уже отмечалось, методики, расширяющие возможности RAG, можно разделить на три вида оптимизации: до извлечения, при извлечении и после извлечения данных.
Оптимизация перед извлечением данных
Эта методика нацелена как на оптимизацию индексирования данных, так и на оптимизацию запросов. Методы оптимизации индексирования данных направлены на хранение данных таким образом, чтобы повысить эффективность их извлечения, например:
- “Скользящее” окно (sliding window) — один из самых простых методов — использует перекрытие между фрагментами (чанками).
- Повышение уровня глубины детализации данных предполагает применение методов очистки данных, таких как удаление нерелевантной информации, подтверждение фактической точности, обновление устаревшей информации и т. д.
- Добавление метаданных, таких как даты, цели и главы для фильтрации данных.
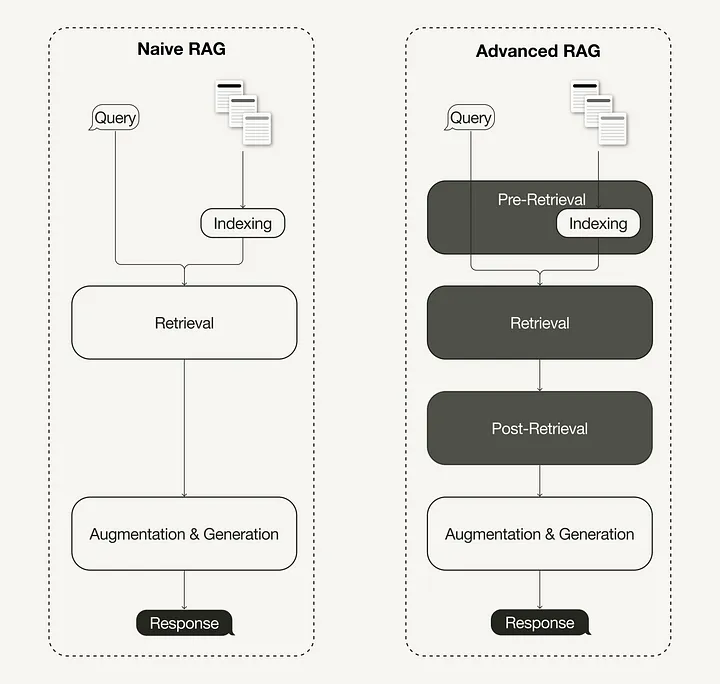
- Оптимизация индексных структур включает различные стратегии индексирования данных, такие как регулировка размеров чанков и использование стратегий мультииндексации. Один из методов, реализация которого будет продемонстрирована в этой статье, — поиск по окну предложений — встраивает отдельные предложения для извлечения данных, заменяя их во время вывода текстовым окном большего размера.
Добавим, что методики оптимизации перед извлечением данных не ограничиваются индексированием данных и могут охватывать такие методы на этапе вывода, как маршрутизация запросов, переписывание запросов и расширение запросов.
Оптимизация извлечения данных
Эта методика нацелена на выявление наиболее релевантного контекста. Обычно извлечение данных основано на векторном поиске, который позволяет вычислить семантическое сходство между запросом и проиндексированными данными. Таким образом, большинство методов оптимизации извлечения данных вращаются вокруг эмбеддинг-моделей:
- Тонкая настройка эмбеддинг-моделей позволяет адаптировать их к контексту конкретного домена, что особенно ценно в случае доменов с изменяющимися со временем или редкими терминами. Например,
BAAI/bge-small-en— это высокопроизводительная эмбеддинг-модель, которая может быть тонко настроена. - Динамический эмбеддинг адаптируется к контексту, в котором используются слова, в отличие от статического эмбеддинга, который использует один вектор для каждого слова. Например,
embeddings-ada-02— это сложная OpenAI-модель динамического эмбеддинга, способная учитывать контекст.
Кроме векторного поиска существуют и другие методы извлечения данных, например гибридный поиск, который зачастую имеет отношение к концепции сочетания векторного поиска с поиском по ключевым словам. Этот метод полезен в случаях, когда извлечение данных требует точного совпадения ключевых слов.
Оптимизация после извлечения данных
Дополнительная обработка извлеченного контекста помогает решить такие проблемы, как превышение ограничения контекстного окна и появление шума, мешающего сосредоточиться на важной информации. К методам оптимизации после извлечения данных относятся:
- Сжатие промпта (prompt compression), сокращающее общую его длину за счет удаления нерелевантного и выделения важного контекста.
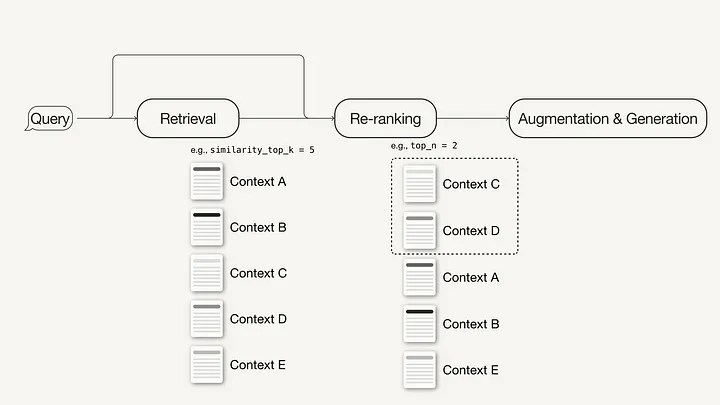
- Повторное ранжирование (re-ranking) с помощью моделей машинного обучения для пересчета оценки релевантности найденных контекстов.
Условия реализаций RAG
Убедитесь, что у вас есть пакеты и ключ API, которые потребуются для выполнения практической части работы по изучению RAG.
Необходимые пакеты
Мы будем выполнять Python-реализацию простого и продвинутого RAG-пайплайнов с помощью LlamaIndex.
pip install llama-index
В данном случае будет использована модель LlamaIndex v0.10. Для перехода с более старой версии LlamaIndex на новую необходимо выполнить следующие команды, которые помогут правильно установить и запустить модель:
pip uninstall llama-index
pip install llama-index --upgrade --no-cache-dir --force-reinstall
LlamaIndex предлагает возможность локального размещения векторных эмбеддингов в JSON-файлах для постоянного хранения, что отлично подходит для быстрого прототипирования идеи. Однако мы будем использовать векторную базу данных для постоянного хранения, так как продвинутые методики RAG нацелены на готовые к производству приложения.
Поскольку, помимо хранения векторных эмбеддингов, нам понадобятся возможности хранения метаданных и гибридного поиска, будем использовать векторную базу данных Weaviate (v3.26.2) с открытым исходным кодом, которая поддерживает эти функции.
pip install weaviate-client llama-index-vector-stores-weaviate
API-ключ
Будем использовать Weaviate Embedded, так как в этом случае предоставляется возможность бесплатного доступа без регистрации для получения API-ключа. Однако, поскольку в данном руководстве используются эмбеддинг-модель и LLM от OpenAI, понадобится API-ключ OpenAI. Чтобы получить его, нужно завести аккаунт OpenAI и затем кликнуть “Create new secret key” (“Создать новый секретный ключ”) в разделе API keys (API-ключи).
После этого можно создать локальный файл .env в корневом каталоге и определить в нем API-ключ:
OPENAI_API_KEY="<YOUR_OPENAI_API_KEY>"
Загрузить API-ключ поможет следующий код:
# !pip install python-dotenv
import os
from dotenv import load_dotenv,find_dotenv
load_dotenv(find_dotenv())
Реализация простой RAG с помощью LlamaIndex
Итак, наша задача — реализовать простой RAG-пайплайн с помощью LlamaIndex. Весь код реализации простого RAG-пайплайна можно найти в этом ноутбуке Jupyter. Реализацию простого RAG-пайплайна с использованием LangChain поможет выполнить эта статья.
Шаг 1. Определение эмбеддинг-модели и LLM
Можно определить эмбеддинг-модель и LLM в объекте глобальных настроек. Тогда не придется снова указывать модели в явном виде в коде.
- Эмбеддинг-модель: используется для генерации векторных эмбеддингов для фрагментов (чанков) документа и запроса.
- LLM: используется для генерации ответа на основе запроса пользователя и соответствующего контекста.
from llama_index.embeddings.openai import OpenAIEmbedding
from llama_index.llms.openai import OpenAI
from llama_index.core.settings import Settings
Settings.llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
Settings.embed_model = OpenAIEmbedding()
Шаг 2. Загрузка данных
Теперь создадим локальный каталог с именем data в корневом каталоге и загрузим несколько примеров данных из репозитория LlamaIndex GitHub repository (лицензированного Массачусетским технологическим институтом).
!mkdir -p 'data'
!wget '<https://raw.githubusercontent.com/run-llama/llama_index/main/docs/examples/data/paul_graham/paul_graham_essay.txt>' -O 'data/paul_graham_essay.txt'
После этого можно загрузить данные для дальнейшей обработки:
from llama_index.core import SimpleDirectoryReader
# Загрузка данных
documents = SimpleDirectoryReader(
input_files=["./data/paul_graham_essay.txt"]
).load_data()
Шаг 3. Разбивка документа на узлы
Поскольку весь документ слишком велик, чтобы поместиться в контекстное окно LLM, придется разбить его на небольшие текстовые фрагменты (или чанки от англ. “chunks”), которые в LlamaIndex называются узлами (Nodes). Разобьем загруженные документы на узлы с помощью SimpleNodeParser с определенным размером узла 1024.
from llama_index.core.node_parser import SimpleNodeParser
node_parser = SimpleNodeParser.from_defaults(chunk_size=1024)
# Извлечение узлов из документов
nodes = node_parser.get_nodes_from_documents(documents)
Шаг 4. Создание индекса
Теперь нам предстоит создать индекс, в котором будут храниться все внешние знания в Weaviate — векторной базе данных с открытым исходным кодом.
Сначала нужно подключиться к экземпляру Weaviate. В данном случае используем Weaviate Embedded, который позволяет бесплатно экспериментировать в ноутбуках без ключа API. Для получения готового к производству решения рекомендуется развернуть Weaviate самостоятельно, например с помощью Docker или управляемого сервиса.
import weaviate
# Подключитесь к вашему экземпляру Weaviate
client = weaviate.Client(
embedded_options=weaviate.embedded.EmbeddedOptions(),
)
Создадим VectorStoreIndex из клиента Weaviate для хранения данных и взаимодействия с ними.
from llama_index.core import VectorStoreIndex, StorageContext
from llama_index.vector_stores.weaviate import WeaviateVectorStore
index_name = "MyExternalContext"
# Создание векторного хранилища
vector_store = WeaviateVectorStore(
weaviate_client = client,
index_name = index_name
)
# Настройка хранилища для эмбеддингов
storage_context = StorageContext.from_defaults(vector_store=vector_store)
# Настройка индекса и
# создание VectorStoreIndex, который занимается разбитием документов на чанки
# и шифрованием чанков в эмбеддинги для будущего процесса извлечения
index = VectorStoreIndex(
nodes,
storage_context = storage_context,
)
Шаг 5. Настройка поискового движка (query engine)
Переводим индекс в режим поискового движка.
# Класс QueryEngine оснащен генератором
# и облегчает извлечение и генерацию.
query_engine = index.as_query_engine()
Шаг 6. Выполнение запроса для простой системы RAG с помощью собственных данных
Теперь можете запустить запрос для простого RAG-пайплайна на примере своих данных, как показано ниже:
# Запустите свой запрос для простого RAG-пайплайна
response = query_engine.query(
"What happened at Interleaf?"
)
Реализация продвинутой RAG с помощью LlamaIndex
Теперь рассмотрим простые настройки, которые помогут превратить описанный выше простой RAG-пайплайн в продвинутый. В этой части руководства будут использованы продвинутые методики RAG:
- Оптимизация перед извлечением данных (Pre-retrieval optimization): поиск по окну предложений.
- Оптимизация извлечения данных (Retrieval optimization): гибридный поиск.
- Оптимизация после извлечения данных (Post-retrieval optimization): повторное ранжирование.
Поскольку здесь будут рассмотрены только модификации, можете найти код полноценного продвинутого RAG-пайплайна в этом ноутбуке Jupyter.
Пример оптимизации индексирования (поиск по окну предложений)
Для применения метода поиска по окну предложений необходимо внести две корректировки: изменить способ хранения и постобработки данных. Вместо SimpleNodeParser будем использовать SentenceWindowNodeParser.
from llama_index.core.node_parser import SentenceWindowNodeParser
# создайте парсер узлов окна предложений с настройками по умолчанию
node_parser = SentenceWindowNodeParser.from_defaults(
window_size=3,
window_metadata_key="window",
original_text_metadata_key="original_text",
)
SentenceWindowNodeParser выполняет две задачи:
- Разделяет документ на отдельные предложения, которые будут вложены.
- Для каждого предложения создает контекстное окно. Если указать
window_size = 3, результирующее окно будет длиной в три предложения, начиная с предложения, предшествующего встраиваемому предложению, и заканчивая последующим предложением. Окно будет сохранено в виде метаданных.
При извлечении данных возвращается предложение, наиболее точно соответствующее запросу. После извлечения необходимо заменить предложение на все окно из метаданных, определив MetadataReplacementPostProcessor и использовав его в списке node_postprocessors.
from llama_index.core.postprocessor import MetadataReplacementPostProcessor
# По умолчанию целевой ключ принимает значение `window`, чтобы соответствовать стандартному значению node_parser'а.
postproc = MetadataReplacementPostProcessor(
target_metadata_key="window"
)
...
query_engine = index.as_query_engine(
node_postprocessors = [postproc],
)
Пример оптимизации извлечения данных: гибридный поиск
Реализовать гибридный поиск в LlamaIndex очень просто. Достаточно изменить два параметра в query_engine, если базовая векторная база данных поддерживает гибридные поисковые запросы. Параметр alpha задает взвешивание между векторным поиском и поиском по ключевым словам, где alpha=0 означает поиск по ключевым словам, а alpha=1 — чистый векторный поиск.
query_engine = index.as_query_engine(
...,
vector_store_query_mode="hybrid",
alpha=0.5,
...
)
Пример оптимизации после извлечения данных (повторного ранжирования)
Добавление модели повторного ранжирования в продвинутый RAG-пайплайн осуществляется в три простых шага:
- Определение модели повторного ранжирования. Здесь будет использована модель BAAI/bge-reranker-base, размещенная на Hugging Face.
- Добавление модели повторного ранжирования в список
node_postprocessors(в поисковом движке). - Увеличение значения
similarity_top_kв поисковом движке для получения большего числа контекстных отрывков, которые после повторного ранжирования могут быть уменьшены доtop_n.
# !pip install torch sentence-transformers
from llama_index.core.postprocessor import SentenceTransformerRerank
# Определение модели повторного ранжирования
rerank = SentenceTransformerRerank(
top_n = 2,
model = "BAAI/bge-reranker-base"
)
...
# Добавление модели повторного ранжирования в поисковой движок
query_engine = index.as_query_engine(
similarity_top_k = 6,
...,
node_postprocessors = [rerank],
...,
)
Заключение
Мы рассмотрели концепцию продвинутой RAG, которая обладает набором методик, позволяющих устранить ограничения парадигмы простой RAG. После обзора этих методик мы реализовали простой и продвинутый RAG-пайплайны с использованием LlamaIndex для оркестровки.
Компонентами RAG-пайплайна были языковые модели от OpenAI, модель повторного ранжирования от BAAI, размещенная на Hugging Face, и векторная база данных Weaviate.
Comments