* Алгоритм для очень больших графов, любые мысли о кэшировании ярлыков?
Я пишу моделирование курьера / логистики на картах OpenStreetMap и понял, что базовый алгоритм A*, как показано ниже, не будет достаточно быстрым для больших карт (например, Большого Лондона).
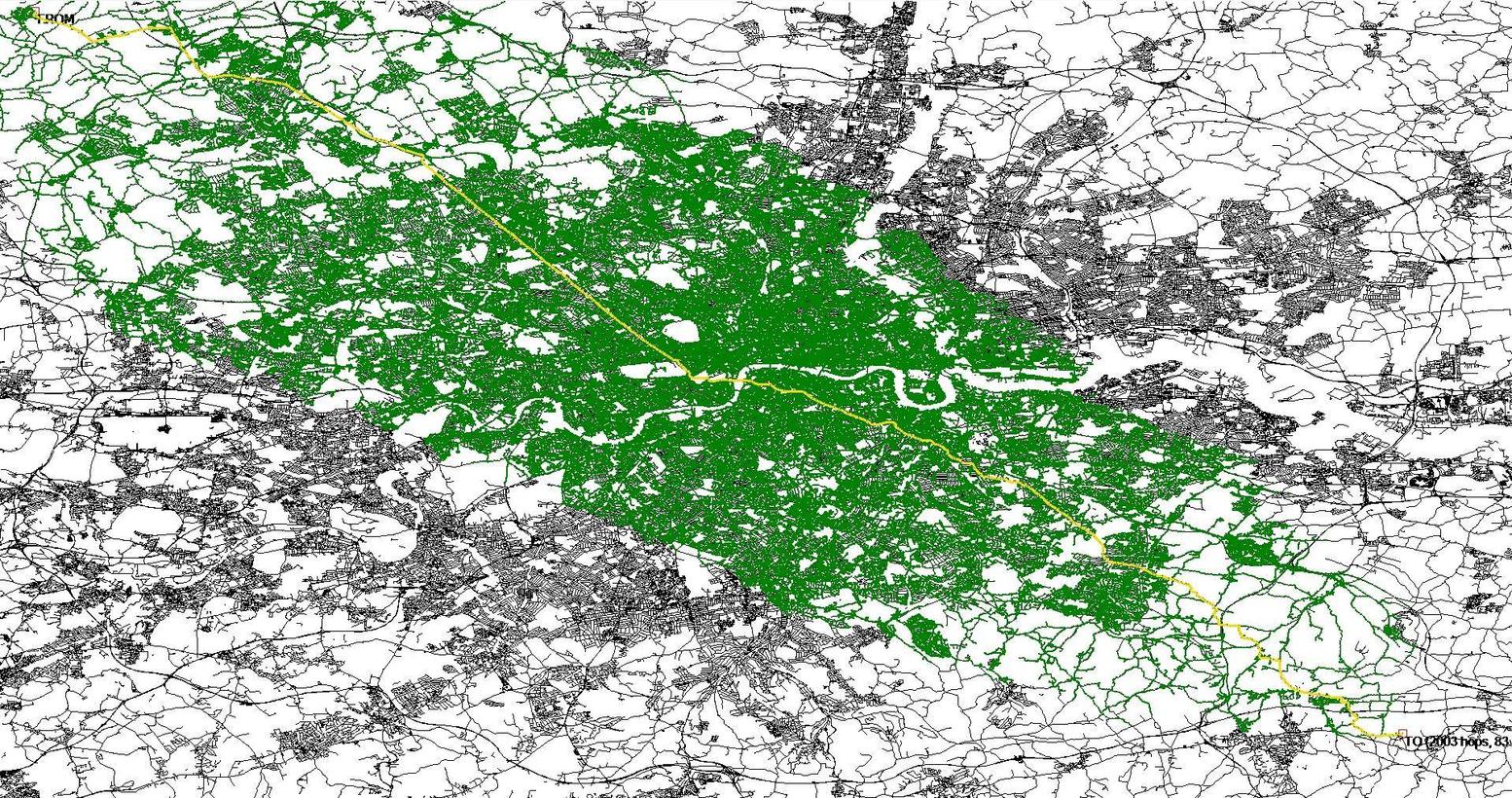
зеленые узлы соответствуют тем, которые были помещены в очередь open set/priority, и из-за огромного количества (вся карта-это что-то вроде 1-2 миллионов), требуется 5 секунд или около того, чтобы найти изображенный маршрут. К сожалению, 100 МС на маршрут составляет около мой абсолютный предел.
в настоящее время узлы хранятся как в списке смежности, так и в пространственном массиве 100x100 2D.
Я ищу методы, где я могу обменять время предварительной обработки, пространство и при необходимости оптимальность маршрута, для более быстрых запросов. Линейная формула Haversine для эвристической стоимости является самой дорогой функцией в соответствии с профилировщиком-я оптимизировал свой базовый A* столько, сколько могу.
например, я думал, если я выберите произвольный узел X из каждого квадранта 2D-массива и запустите a* между каждым, я могу хранить маршруты на диск для последующего моделирования. При запросе я могу запустить поиск* только в квадрантах, чтобы попасть между предварительно вычисленным маршрутом и X.
есть ли более утонченная версия того, что я описал выше, или, возможно, другой метод, который я должен преследовать. Большое спасибо!
для записи, вот некоторые результаты сравнения для произвольного взвешивания эвристической стоимости и вычисление пути между 10 парами случайно выбранных узлов:
Weight // AvgDist% // Time (ms)
1 1 1461.2
1.05 1 1327.2
1.1 1 900.7
1.2 1.019658848 196.4
1.3 1.027619169 53.6
1.4 1.044714394 33.6
1.5 1.063963413 25.5
1.6 1.071694171 24.1
1.7 1.084093229 24.3
1.8 1.092208509 22
1.9 1.109188175 22.5
2 1.122856792 18.2
2.2 1.131574742 16.9
2.4 1.139104895 15.4
2.6 1.140021962 16
2.8 1.14088128 15.5
3 1.156303676 16
4 1.20256964 13
5 1.19610861 12.9
удивительно увеличение коэффициента до 1.1 почти вдвое сократило время выполнения при сохранении того же маршрута.
9 ответов:
вы должны быть в состоянии сделать это гораздо быстрее, торгуя оптимальность. Смотрите допустимость и оптимальность на Википедии.
идея в том, чтобы использовать
epsilonзначение, которое приведет к решению не хуже, чем1 + epsilonумножает оптимальный путь, но это приведет к тому, что алгоритм будет рассматривать меньше узлов. Обратите внимание, что это не означает, что возвращаемое решение всегда будет1 + epsilonраз оптимальный путь. Это просто худший случай. Я точно не знаю как он будет вести себя на практике для вашей проблемы, но я думаю, что это стоит изучить.вы получаете ряд алгоритмов, которые полагаются на эту идею в Википедии. Я считаю, что это ваш лучший выбор для улучшения алгоритма и что он может работать в течение вашего срока, все еще возвращая хорошие пути.
поскольку ваш алгоритм имеет дело с миллионами узлов за 5 секунд, я предполагаю, что вы также используете двоичные кучи для реализации, правильно? Если вы их реализовали вручную убедитесь, что они реализованы как простые массивы и что они являются двоичными кучами.
существуют специальные алгоритмы для этой проблемы, которые делают много предварительных вычислений. Из памяти предварительное вычисление добавляет информацию к графику, который A* использует для получения гораздо более точной эвристики, чем расстояние прямой линии. Википедия дает имена ряда методов в http://en.wikipedia.org/wiki/Shortest_path_problem#Road_networks и говорит, что хаб маркировка является лидером. Быстрый поиск по этому вопросу появляется http://research.microsoft.com/pubs/142356/HL-TR.pdf. более старый, используя*, находится в http://research.microsoft.com/pubs/64505/goldberg-sp-wea07.pdf.
вам действительно нужно использовать Haversine? Чтобы охватить Лондон, я бы подумал, что вы могли бы предположить плоскую землю и использовать Пифагора или сохранить длину каждой ссылки в графике.
есть действительно отличная статья, которую Microsoft Research написала на эту тему:
http://research.microsoft.com/en-us/news/features/shortestpath-070709.aspx
Оригинал статьи размещен здесь (PDF):
http://www.cc.gatech.edu/~thad/6601-gradAI-fall2012/02-search-Gutman04siam.pdf
по сути, есть несколько вещей, которые вы можете попробовать:
- начните с обоих источников, а также назначение. Это помогает свести к минимуму количество ненужной работы, которую вы выполняете при переходе от источника наружу к месту назначения.
- используйте ориентиры и шоссе. По существу, найти некоторые позиции на каждой карте, которые обычно принимаются пути и выполнить некоторые предварительные вычисления, чтобы определить, как эффективно перемещаться между этими точками. Если вы можете найти путь от вашего источника до ориентира, затем до других ориентиров, а затем до места назначения, вы можете быстро найти жизнеспособный маршрут и оптимизировать оттуда.
- исследуйте алгоритмы, такие как алгоритм" reach". Это помогает свести к минимуму объем работы, которую вы будете выполнять при обходе графа, минимизируя количество вершин, которые необходимо учитывать, чтобы найти правильный маршрут.
GraphHopper делает еще две вещи, чтобы получить быстрый, нет-эвристическая и гибкая маршрутизация (примечание: Я автор, и вы можете попробовать его в интернете здесь)
- не столь очевидная оптимизация заключается в том, чтобы избежать сопоставления узлов OSM с внутренними узлами 1:1. Вместо этого GraphHopper использует только соединения в качестве узлов и сохраняет примерно 1/8 пройденных узлов.
- он имеет эффективные инструменты для A*, Dijkstra или, например, один ко многим Dijkstra. Что делает маршрут под 1С возможно через всю Германию. Двунаправленная версия A* (без эвристики) делает это еще быстрее.
Так что это должно быть возможно, чтобы получить вам быстрые маршруты для Большого Лондона.
кроме того, режим по умолчанию-это режим скорости, который делает все на порядок быстрее (например, 30 мс для европейских широких маршрутов), но менее гибким, поскольку он требует предварительной обработки (Иерархии Сужение). Если вам это не нравится, просто отключите его а также дополнительно настроить включенные улицы для автомобилей или, возможно, лучше создать новый профиль для грузовиков - например, исключить сервисные улицы и дорожки, которые должны дать вам еще 30% прироста. И как с любым двунаправленным алгоритмом вы можете легко реализовать параллельный поиск.
Я думаю, что стоит проработать вашу идею с "квадрантами". Более строго, я бы назвал это поиском маршрута с низким разрешением.
вы можете выбрать X подключенных узлов, которые находятся достаточно близко, и рассматривать их как один узел с низким разрешением. Разделите весь график на такие группы, и вы получите график с низким разрешением. Это подготовительный этап.
чтобы вычислить маршрут от источника до цели, сначала определите узлы с низким разрешением, к которым они принадлежат, и найдите низкое разрешение маршрут. Затем улучшите свой результат, найдя маршрут на графике с высоким разрешением, однако ограничивая алгоритм только узлами, которые принадлежат узлам hte с низким разрешением маршрута с низким разрешением (необязательно вы также можете рассмотреть соседние узлы с низким разрешением до некоторой глубины).
Это также может быть обобщено на несколько разрешений, а не только высокое/низкое.
в конце вы должны получить маршрут, который достаточно близок к оптимальному. Это локально оптимально, но может быть несколько хуже, чем оптимальный глобально в некоторой степени, что зависит от скачка разрешения (т. е. приближения, которое вы делаете, когда группа узлов определяется как один узел).
есть десятки вариантов A*, которые могут соответствовать законопроекту здесь. Однако вы должны подумать о своих случаях использования.
- вы ограничены в памяти (а также в кэше)?
- вы можете выполнять поиск?
- будет ли ваша реализация алгоритма использоваться только в одном месте (например, в Большом Лондоне, а не в Нью-Йорке или Мумбаи или где угодно)?
У нас нет возможности узнать все детали, в которые вы и ваш работодатель посвящены. Ваш первая остановка при этом должна быть CiteSeer или Google Scholar: ищите документы, которые обрабатывают поиск пути с тем же общим набором ограничений, что и вы.
затем выберите три или четыре алгоритма, сделайте прототипирование, проверьте, как они масштабируются и настраивают их. Вы должны иметь в виду, что вы можете комбинировать различные алгоритмы в одной и той же процедуре поиска большого пути на основе расстояния между точками, оставшегося времени или любых других факторов.
Как уже было Саид, основываясь на малом масштабе вашей целевой области, падение Haversine, вероятно, является вашим первым шагом, экономящим драгоценное время на дорогостоящих оценках тригонометрии. Примечание: Я не рекомендую использовать Евклидово расстояние в координатах lat, lon - перепроектировать вашу карту, например, в поперечный Меркатор вблизи центра и использовать декартовы координаты в ярдах или метрах!
предварительное вычисление является вторым, и изменение компиляторов может быть очевидной третьей идеей (переключитесь на C или c++ - см. https://benchmarksgame.alioth.debian.org/ для деталей).
дополнительные шаги оптимизации могут включать в себя избавление от динамического выделения памяти и использование эффективной индексации для поиска среди узлов (подумайте о R-дереве и его производных/альтернативах).
Я работал в крупной навигационной компании, поэтому могу с уверенностью сказать, что 100 мс должны получить вам маршрут из Лондона в Афины даже на встроенном устройстве. Большой Лондон был бы тестовой картой для нас, так как он удобно мал (легко помещается в ОЗУ - это на самом деле не нужно)
во-первых, A* полностью устарел. Его главное преимущество заключается в том, что он" технически " не требует предварительной обработки. На практике вам все равно нужно предварительно обработать карту OSM, так что это бессмысленно выгода.
основной метод, чтобы дать вам огромный прирост скорости является флаги дуги. Если вы разделите карту, скажем, на секции 5x6, вы можете выделить 1 битную позицию в 32-битном целом для каждой секции. Теперь вы можете определить для каждого края, полезно ли это когда-либо во время путешествия до раздел
{X,Y}из другого раздела. Довольно часто дороги являются двунаправленными, и это означает, что полезно только одно из двух направлений. Таким образом, одно из двух направлений имеет этот бит, а другое имеет все прояснилось. Это может показаться не реальным преимуществом, но это означает, что на многих перекрестках вы уменьшаете количество вариантов для рассмотрения от 2 до 1, и это занимает всего одну битную операцию.
обычно A * приходит вместе с слишком большим потреблением памяти, а не время колеблется.
однако я думаю, что было бы полезно сначала вычислить только с узлами, которые являются частью "больших улиц", вы бы выбрали шоссе над крошечной аллеей обычно.
Я думаю, вы уже можете использовать это для своей весовой функции, но вы можете быть быстрее, если вы используете некоторую очередь приоритетов, чтобы решить, какой узел тестировать дальше для дальнейшего путешествия.
также вы можете попробовать снизить график только для узлов, которые являются частью ребер низкой стоимости, а затем найти путь от начала/конца до ближайшего из этих узлов. Таким образом, у вас есть 2 пути от начала до "Большой улицы" и "большой улицы" до конца. Теперь вы можете вычислить лучший путь между двумя узлами, которые являются частью "больших улиц" в уменьшенном графике.
старый вопрос, но все же:
попробуйте использовать разные кучи, что "двоичная куча". "Лучшая асимптотическая куча сложности" - это определенно куча Фибоначчи, и на этой странице wiki есть хороший обзор:
https://en.wikipedia.org/wiki/Fibonacci_heap#Summary_of_running_times
обратите внимание, что двоичная куча имеет более простой код, и он реализован над массивом, а обход массива предсказуем, поэтому современный процессор выполняет операции с двоичной кучей много быстрее.
однако, учитывая достаточно большой набор данных, другие кучи выиграют над двоичной кучей из-за их сложности...
этот вопрос кажется достаточно большим набором данных.
Comments