7 ответов:
на самом деле, это довольно просто: вместо количества ячеек вы можете дать список с границами ячеек. Они также могут быть неравномерно распределены:
plt.hist(data, bins=[0, 10, 20, 30, 40, 50, 100])если вы просто хотите, чтобы они равномерно распределены, вы можете просто использовать диапазон:
plt.hist(data, bins=range(min(data), max(data) + binwidth, binwidth))
добавлено в оригинальный ответ
выше строка работает для
dataзаполняется только целые числа. Как macrocosme указывает, что для поплавков вы можете использовать:import numpy as np plt.hist(data, bins=np.arange(min(data), max(data) + binwidth, binwidth))
для N ячеек края ячейки задаются списком из N+1 значений, где первые N дают нижние края ячейки, а +1 дает верхний край последней ячейки.
код:
from numpy import np; from pylab import * bin_size = 0.1; min_edge = 0; max_edge = 2.5 N = (max_edge-min_edge)/bin_size; Nplus1 = N + 1 bin_list = np.linspace(min_edge, max_edge, Nplus1)обратите внимание, что linspace создает массив от min_edge до max_edge, разбитый на N + 1 значений или N ячеек
Я думаю, что простой способ будет вычислить минимум и максимум данных, которые у вас есть, а затем вычислить
L = max - min. Тогда вы делитеLпо желаемой ширине бункера (я предполагаю, что это то, что вы подразумеваете под размером бункера) и использовать потолок этого значения в качестве количества бункеров.
У меня была та же проблема, что и OP (я думаю!), но я не мог заставить его работать так, как указала Ластальда. Я не знаю, правильно ли я интерпретировал вопрос, но я нашел другое решение (вероятно, это действительно плохой способ сделать это).
вот как я это сделал:
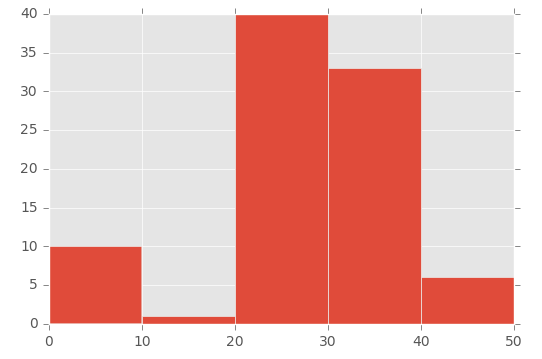
plt.hist([1,11,21,31,41], bins=[0,10,20,30,40,50], weights=[10,1,40,33,6]);который создает это:
поэтому первый параметр в основном "инициализирует" бин-я в частности, создание числа, которое находится между диапазоном, который я установил в параметре bins.
чтобы продемонстрировать это, посмотрите на массив в первом параметре ([1,11,21,31,41]) и массив "bins" во втором параметре ([0,10,20,30,40,50]):
- число 1 (из первого массива) находится между 0 и 10 (в массиве' bins')
- число 11 (из первого массива) находится между 11 и 20 (в массиве' bins')
- число 21 (из первого массива) падает между 21 и 30 (в массиве 'bins') и т. д.
затем я использую параметр 'weights' для определения размера каждого Бина. Это массив, используемый для параметра weights: [10,1,40,33,6].
таким образом, от 0 до 10 бин получает значение 10, от 11 до 20 бин получает значение 1, от 21 до 30 бин получает значение 40 и т.д.
для гистограммы с целочисленными значениями X я в конечном итоге с помощью
plt.hist(data, np.arange(min(data)-0.5, max(data)+0.5)) plt.xticks(range(min(data), max(data)))смещение 0,5 центрирует ячейки по значениям оси X. Элемент
plt.xticksвызов добавляет галочку для каждого целого числа.
Я знаю, что это старый вопрос, но я не видел, чтобы кто-то просто добавлял размер Бина в качестве аргумента после выделения диапазона. Bin размер = 50 в этом случае.
plt.hist(data2, bins = np.arange(min(data),max(data),50))
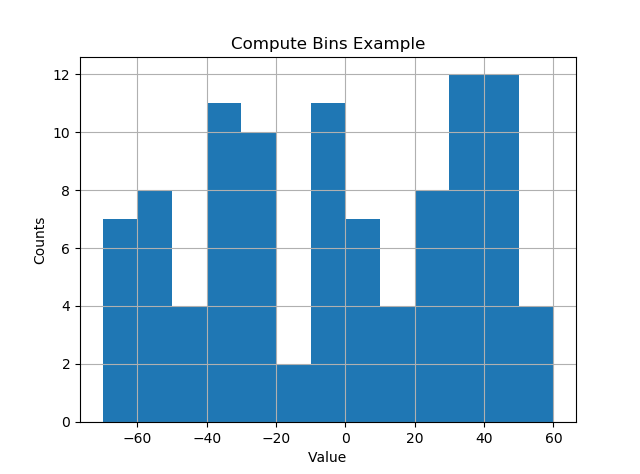
мне нравится, чтобы все происходило автоматически и чтобы бункеры падали на "хорошие" значения. Следующее, кажется, работает довольно хорошо.
import numpy as np import numpy.random as random import matplotlib.pyplot as plt def compute_histogram_bins(data, desired_bin_size): min_val = np.min(data) max_val = np.max(data) min_boundary = -1.0 * (min_val % desired_bin_size - min_val) max_boundary = max_val - max_val % desired_bin_size + desired_bin_size n_bins = int((max_boundary - min_boundary) / desired_bin_size) + 1 bins = np.linspace(min_boundary, max_boundary, n_bins) return bins if __name__ == '__main__': data = np.random.random_sample(100) * 123.34 - 67.23 bins = compute_histogram_bins(data, 10.0) print(bins) plt.hist(data, bins=bins) plt.xlabel('Value') plt.ylabel('Counts') plt.title('Compute Bins Example') plt.grid(True) plt.show()результат имеет бункеры на хороших интервалах размера бункера.
[-70. -60. -50. -40. -30. -20. -10. 0. 10. 20. 30. 40. 50. 60.]
Comments