8 ответов:
Spark может работать без Hadoop, но некоторые его функции зависят от кода Hadoop (например, обработка паркетных файлов). Мы запускаем Spark на Mesos и S3, что было немного сложно настроить, но работает очень хорошо после завершения (вы можете прочитать резюме того, что нужно было правильно установить его здесь).
Искра - это распределенный вычислительный механизм в памяти.
Hadoop - это фреймворк для распределенного хранения ( HDFS) и распределенной обработки (пряжа).
Spark может работать с компонентами Hadoop или без них (HDFS/YARN)
Распределенного Хранения:
с Искра не имеет собственного распределенного хранилища система, она должна зависеть от одной из этих систем хранения данных для распределенных вычислений.
S3 – несрочных заданий. S3 подходит для очень конкретных случаев использования, когда локальность данных не является критической.
Кассандра - идеально подходит для анализа потоковых данных и перебора для пакетных заданий.
HDFS - отлично подходит для пакетных заданий без ущерба для данных местности.
распределенные обработка:
вы можете запустить Spark в трех различных режимах: автономный, пряжа и Мезос
посмотрите на вопрос ниже SE для подробного объяснения как распределенного хранения, так и распределенной обработки.
по умолчанию Spark не имеет механизма хранения.
для хранения данных необходима быстрая и масштабируемая файловая система. Вы можете использовать S3 или HDFS или любую другую файловую систему. Hadoop является экономичным вариантом из-за низкой стоимости.
кроме того, если вы используете Тахион, это повысит производительность с Hadoop. Это настоятельно рекомендуется Hadoop для apache spark обработка.
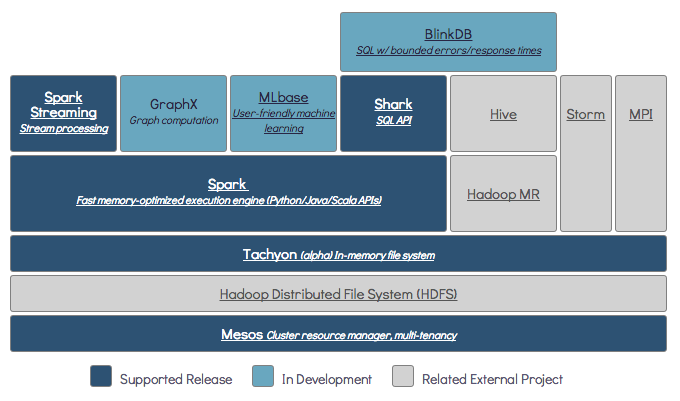
да, spark может работать без hadoop. Все основные функции spark будут продолжать работать, но вы пропустите такие вещи, как простое распространение всех ваших файлов (кода, а также данных) на все узлы кластера через hdfs и т. д.
Да, вы можете установить Spark без Hadoop. Это было бы немного сложно Вы можете обратиться к ссылке arnon, чтобы использовать parquet для настройки на S3 в качестве хранилища данных. http://arnon.me/2015/08/spark-parquet-s3/
Spark только делает обработку и использует динамическую память для выполнения задачи, но для хранения данных вам нужна некоторая система хранения данных. Здесь hadoop входит в роль с Spark, он обеспечивает хранение для Spark. Еще одна причина для использования Hadoop с Spark - это они являются открытым исходным кодом, и оба могут легко интегрироваться друг с другом по сравнению с другой системой хранения данных. Для другого хранилища, такого как S3, вам должно быть сложно настроить его, как указано в приведенной выше ссылке.
но у Hadoop также есть свой процессор под названием Mapreduce.
хотите узнать разницу в обоих?
проверьте эту статью: https://www.dezyre.com/article/hadoop-mapreduce-vs-apache-spark-who-wins-the-battle/83
I думаю, что эта статья поможет вам понять
Как использовать
при использовании и
Как использовать !!!
согласно документации Spark, Spark может работать без Hadoop.
вы можете запустить его в автономном режиме без какого-либо менеджера ресурсов.
но если вы хотите работать в многоузловой установке, вам нужен менеджер ресурсов,такой как YARN или Mesos, и распределенная файловая система, такая как HDFS, S3 и т. д.
Да, конечно. Spark-это независимая вычислительная структура. Hadoop-это распределительная система хранения данных (HDFS)с вычислительной платформой MapReduce. Spark может получать данные из HDFS, а также из любого другого источника данных, такого как традиционная база данных(JDBC), kafka или даже локальный диск.
нет. Для начала работы требуется полная установка Hadoop -https://issues.apache.org/jira/browse/SPARK-10944
Comments