5 ответов:
как уже упомянутый,
mapпозволяет перебирать элементы в отсортированном виде, ноunordered_mapнет. Это очень важно во многих ситуациях, например, при отображении коллекции (например, адресной книги). Это также проявляется другими косвенными способами, такими как: (1) Начните итерацию с итератора, возвращенногоfind(), или (2) существование функций-членов, таких какlower_bound().кроме того, я думаю, что есть некоторая разница в худшем случае поиск сложности.
на
map, Это O (lg N)на
unordered_map, Это O (N ) [This мая случается, когда хэш-функция не очень хороша, что приводит к слишком большому количеству хэш-коллизий.]то же самое применимо для худшем случаеудаление сложности.
в дополнение к ответам выше вы также должны отметить, что только потому, что
unordered_mapпостоянная скорость (O(1)) не означает, что это быстрее, чемmap(приказlog(N)). Константа может быть больше, чемlog(N)тем более чтоNограничено 232 (или 264).так что в дополнение к другим ответам (
mapподдерживает порядок и хэш-функции могут быть трудными) может быть, чтоmapболее производительным.например, в программе, которую я запускал для блоге я видел, что для VS10
std::unordered_mapменьше, чемstd::map(хотяboost::unordered_mapбыстрее, чем обе).
Примечание с 3-го по 5-й бары.
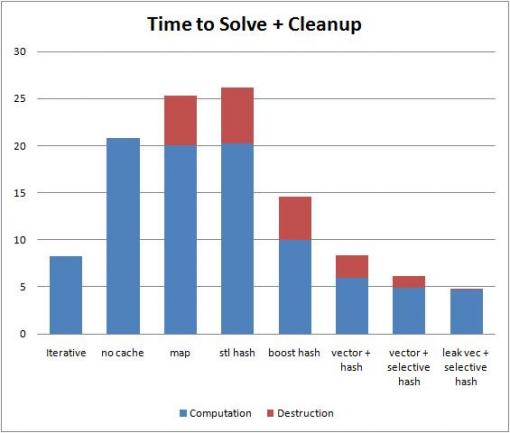
это связано с Carruth Гугл Чендлер в его CppCon 2014 лекция
std::map(по мнению многих) не полезно для ориентированной на производительность работы: Если вы хотите O (1)-амортизированный доступ, используйте правильный ассоциативный массив (или за его отсутствием,std::unorderded_map); Если вы хотите отсортировать последовательный доступ, используйте что-то на основе вектора.и
std::map- это сбалансированное дерево, и вы должны пересечь его, или ре-баланс это невероятно часто. Это операции Cache-killer и cache-apocalypse соответственно... так что просто скажи "нет"std::map.вы можете быть заинтересованы в это так вопрос на эффективных реализациях хэш-карты.
(PS -
std::unordered_mapэто кэш, потому что он использует связанные списки в качестве ведра.)
Я думаю, что это очевидно, что вы бы использовать
std::mapвам нужно перебирать элементы на карте в отсортированном порядке.вы также можете использовать его, когда вы хотите написать оператор сравнения (что интуитивно понятно) вместо хэш-функции (что вообще нелогично).
скажем, у вас есть очень большие ключи, возможно больших строк. Чтобы создать хэш-значение для большой строки, вам нужно пройти всю строку от начала до конца. Это займет по крайней мере линейное время до длины ключа. Однако, когда вы ищете только двоичное дерево с помощью
>оператор ключа каждое сравнение строк может возвращать при обнаружении первого несоответствия. Это, как правило, очень рано для больших строк.это рассуждение может быть применено к
Comments