Чтение PDF выделенного текста (выделение аннотаций) с помощью C#
Я написал инструмент извлечения с помощью iTextSharp, который извлекает информацию аннотаций из PDF-документов. Для выделения аннотации я получаю только прямоугольник для области на странице, которая выделена.
Я стремлюсь извлечь текст, который был выделен. Для этого я использую "PdfTextExtractor".
Rectangle rect = new Rectangle(
pdfArray.GetAsNumber(0).FloatValue,
pdfArray.GetAsNumber(1).FloatValue,
pdfArray.GetAsNumber(2).FloatValue,
pdfArray.GetAsNumber(3).FloatValue);
RenderFilter[] filter = { new RegionTextRenderFilter(rect) };
ITextExtractionStrategy strategy = new FilteredTextRenderListener(new LocationTextExtractionStrategy(), filter);
string textInsideRect = PdfTextExtractor.GetTextFromPage(pdfReader, pageNo, strategy);
return textInsideRect;
Результат, возвращаемый PdfTextExtractor, не совсем корректен. Например, он возвращает "собирался устранить бумажную погоню" , хотя только было выделено слово"устранить".
Достаточно интересный весь текст для TJ, содержащий выделенный "устранить" является "собирался устранить бумажную погоню" (TJ-это инструкция PDF, которая записывает текст на страницу).
Я хотел бы услышать любую информацию по этому вопросу - также решения, которые не включают iTextSharp.
2 ответов:
Причина
Достаточно интересно, что весь текст для TJ, содержащий выделенное "устранить", "собирался устранить бумажную погоню" (TJ-это инструкция PDF, которая записывает текст на страницу).
Это на самом деле причина вашей проблемы. Классы синтаксического анализатора iText передают текст слушателям рендеринга в частях, которые они находят как непрерывные строки в потоке содержимого. Механизм фильтрации, который вы используете, фильтрует эти части. Таким образом, это целое предложение принимается фильтром.
Поэтому вам нужен какой-то предварительный этап обработки, который разбивает эти фрагменты на отдельные символы и передает их по отдельности вашему отфильтрованному слушателю рендеринга.Это на самом деле довольно легко реализовать. Тип аргумента, в котором передаются фрагменты текста,
TextRenderInfo,предлагает метод для разделения себя:/** * Provides detail useful if a listener needs access to the position of each individual glyph in the text render operation * @return A list of {@link TextRenderInfo} objects that represent each glyph used in the draw operation. The next effect is if there was a separate Tj opertion for each character in the rendered string * @since 5.3.3 */ public List<TextRenderInfo> getCharacterRenderInfos() // iText / Java virtual public List<TextRenderInfo> GetCharacterRenderInfos() // iTextSharp / .NetТаким образом, все, что вам нужно сделать, это создать и использовать
RenderListener/IRenderListenerреализация, которая вперед всех вызовы он получает к другому слушателю (ваш фильтрованный слушатель в вашем случае) с поворотом, чтоrenderText/RenderTextрасщепляет свой аргументTextRenderInfoи направляет осколки один за другим по отдельности.Пример Java
Поскольку ОП попросил более подробную информацию, вот еще один код. Поскольку я в основном работаю с Java, я предоставляю его на Java для iText. Но это легко портировать в C# для iTextSharp.
Как упоминалось выше, необходим предварительный этап обработки, который разбивает фрагменты текста разбиваются на отдельные символы и пересылаются по отдельности вашему отфильтрованному слушателю рендеринга.
Для этого шага можно использовать следующий класс
TextRenderInfoSplitter:package stackoverflow.itext.extraction; import com.itextpdf.text.pdf.parser.ImageRenderInfo; import com.itextpdf.text.pdf.parser.TextExtractionStrategy; import com.itextpdf.text.pdf.parser.TextRenderInfo; public class TextRenderInfoSplitter implements TextExtractionStrategy { public TextRenderInfoSplitter(TextExtractionStrategy strategy) { this.strategy = strategy; } public void renderText(TextRenderInfo renderInfo) { for (TextRenderInfo info : renderInfo.getCharacterRenderInfos()) { strategy.renderText(info); } } public void beginTextBlock() { strategy.beginTextBlock(); } public void endTextBlock() { strategy.endTextBlock(); } public void renderImage(ImageRenderInfo renderInfo) { strategy.renderImage(renderInfo); } public String getResultantText() { return strategy.getResultantText(); } final TextExtractionStrategy strategy; }Если у вас есть
TextExtractionStrategy strategy(например, вашnew FilteredTextRenderListener(new LocationTextExtractionStrategy(), filter)), теперь вы можете кормить его односимвольнымиTextRenderInfoэкземплярами, такими как:String textInsideRect = PdfTextExtractor.getTextFromPage(reader, pageNo, new TextRenderInfoSplitter(strategy));Я протестировал его с PDF, созданным в этом ответе для области
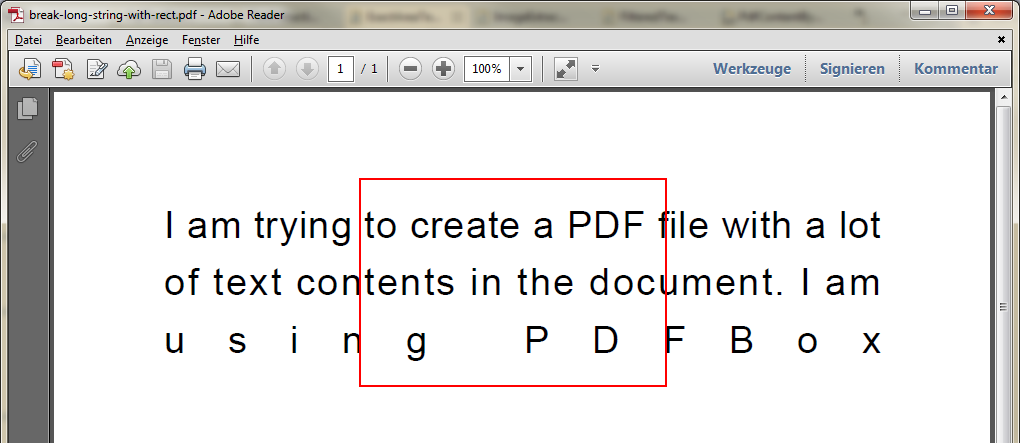
Rectangle rect = new Rectangle(200, 600, 200, 135);Для справки я отметил область в PDF:
Текст экстракция фильтруется по площади без
TextRenderInfoSplitterприводит к:I am trying to create a PDF file with a lot of text contents in the document. I am using PDFBoxИзвлечение текста, отфильтрованное по области с помощью
TextRenderInfoSplitter, приводит к:to create a PDF f ntents in the docu n g P D FКстати, здесь вы видите недостаток раннего разбиения текста на отдельные символы: последняя строка текста набирается с использованием очень большого интервала между символами. Если вы сохраняете текстовые сегменты из PDF, как они есть, стратегии извлечения текста все еще легко могут увидеть, что строка состоит из двух слов , используя и PDFBox . Как только вы вводите текстовые сегменты символ за символом в стратегии извлечения текста, они, вероятно, интерпретируют такие широко заданные слова, как много однобуквенных слов.
Улучшение
Выделенное слово "устранить", например, извлекается как "o устранить t". Это было выделено двойным щелчком по Слову и выделено в Adobe Acrobat Reader.
Нечто подобное происходит в моем примере выше, письма едва прикоснувшись к интересующей вас области, вы получите результат.
Это связано с
RegionTextRenderFilterреализациейallowText, позволяющей продолжить весь текст, чья базовая линия пересекает рассматриваемый прямоугольник, даже если пересечение состоит всего из одной точки:public boolean allowText(TextRenderInfo renderInfo){ LineSegment segment = renderInfo.getBaseline(); Vector startPoint = segment.getStartPoint(); Vector endPoint = segment.getEndPoint(); float x1 = startPoint.get(Vector.I1); float y1 = startPoint.get(Vector.I2); float x2 = endPoint.get(Vector.I1); float y2 = endPoint.get(Vector.I2); return filterRect.intersectsLine(x1, y1, x2, y2); }Учитывая, что вы сначала разбили текст на символы, вы можете проверить, полностью ли их соответствующая базовая строка содержится в рассматриваемой области, т. е.
RenderFilterпутем копированияRegionTextRenderFilterа затем заменив строкуreturn filterRect.intersectsLine(x1, y1, x2, y2);By
return filterRect.contains(x1, y1) && filterRect.contains(x2, y2);В зависимости от того, как именно выделен текст в Adobe Acrobat Reader, вы можете изменить это полностью пользовательским способом.
Выделенные аннотации представляют собой набор четырехугольников, которые представляют область(области) на странице, окруженную аннотацией в записи
/QuadPointsв словаре.Почему они такие?
На самом деле это моя вина. В Acrobat 1.0 я работал над кодом "найти текст", который первоначально использовал только прямоугольник для представления выделенной области на странице. Работая над кодом, я был очень недоволен результатами, особенно картами, на которых был написан текст. затем земля.
В результате я заставил инструмент поиска построить набор четырехугольников на странице и отжечь их, когда это возможно, чтобы построить слова. В Acrobat 2.0 инженер, ответственный за полное обобщенное извлечение текста, построил алгоритм под названием Wordy, который был лучше, чем мой первый разрез, но он сохранил четырехугольник кода, так как это было самое точное представление того, что было на странице.Почти весь текстовый код был переработан, чтобы использовать это код.
Затем мы получаем аннотации выделения. При добавлении аннотаций разметки в Acrobat они использовались для оформления текста, который уже был на странице. Когда пользователь нажимает на страницу, Wordy извлекает текст в соответствующие структуры данных,а затем инструмент выбора текста отображает движение мыши на четырехугольные наборы. При создании аннотации выделения текста подмножество четырехугольников из Wordy помещается в новую аннотацию выделения текста.
Как вы получаете слова на странице, которые выделены. Хитрый. Вы должны извлечь текст на странице (у вас нет Wordy, Извините), а затем найти все квадратики, которые содержатся в наборе из аннотации.
Comments