Преобразование панды метода groupBy объекта в таблице данных
Я начинаю с входных данных, как это
df1 = pandas.DataFrame( {
"Name" : ["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"] ,
"City" : ["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"] } )
который при печати выглядит следующим образом:
City Name
0 Seattle Alice
1 Seattle Bob
2 Portland Mallory
3 Seattle Mallory
4 Seattle Bob
5 Portland Mallory
группировка достаточно прост:
g1 = df1.groupby( [ "Name", "City"] ).count()
и дает печать
8 ответов:
g1здесь и таблицы данных. Он имеет иерархический индекс, хотя:In [19]: type(g1) Out[19]: pandas.core.frame.DataFrame In [20]: g1.index Out[20]: MultiIndex([('Alice', 'Seattle'), ('Bob', 'Seattle'), ('Mallory', 'Portland'), ('Mallory', 'Seattle')], dtype=object)может быть, вы хотите что-то вроде этого?
In [21]: g1.add_suffix('_Count').reset_index() Out[21]: Name City City_Count Name_Count 0 Alice Seattle 1 1 1 Bob Seattle 2 2 2 Mallory Portland 2 2 3 Mallory Seattle 1 1или что-то вроде:
In [36]: DataFrame({'count' : df1.groupby( [ "Name", "City"] ).size()}).reset_index() Out[36]: Name City count 0 Alice Seattle 1 1 Bob Seattle 2 2 Mallory Portland 2 3 Mallory Seattle 1
я хочу немного изменить ответ, данный Wes, потому что версия 0.16.2 требует
as_index=False. Если вы не установите его, вы получите пустой фрейм данных.агрегатные функции не будут возвращать группы, которые вы агрегируете, если они называются столбцами, когда
as_index=Trueпо умолчанию. Сгруппированные столбцы будут индексами возвращаемого объекта.передает
as_index=Falseвернет группы, которые вы агрегируются, если они называются столбцами.агрегирующие функции-это те, которые уменьшают размерность возвращаемых объектов, например:
mean,sum,size,count,std,var,sem,describe,first,last,nth,min,max. Вот что происходит, когда вы делаете, напримерDataFrame.sum()иSeries.nth может действовать как редуктор или фильтр, см. здесь.
import pandas as pd df1 = pd.DataFrame({"Name":["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"], "City":["Seattle","Seattle","Portland","Seattle","Seattle","Portland"]}) print df1 # # City Name #0 Seattle Alice #1 Seattle Bob #2 Portland Mallory #3 Seattle Mallory #4 Seattle Bob #5 Portland Mallory # g1 = df1.groupby(["Name", "City"], as_index=False).count() print g1 # # City Name #Name City #Alice Seattle 1 1 #Bob Seattle 2 2 #Mallory Portland 2 2 # Seattle 1 1 #EDIT:
в версии
0.17.1и позже вы можете использоватьsubsetнаcountиreset_indexс параметромnameinsize:print df1.groupby(["Name", "City"], as_index=False ).count() #IndexError: list index out of range print df1.groupby(["Name", "City"]).count() #Empty DataFrame #Columns: [] #Index: [(Alice, Seattle), (Bob, Seattle), (Mallory, Portland), (Mallory, Seattle)] print df1.groupby(["Name", "City"])[['Name','City']].count() # Name City #Name City #Alice Seattle 1 1 #Bob Seattle 2 2 #Mallory Portland 2 2 # Seattle 1 1 print df1.groupby(["Name", "City"]).size().reset_index(name='count') # Name City count #0 Alice Seattle 1 #1 Bob Seattle 2 #2 Mallory Portland 2 #3 Mallory Seattle 1разницу между
countиsizeэтоsizeподсчитывает значения NaN в то время какcountнет.
просто, это должно сделать задачу:
import pandas as pd grouped_df = df1.groupby( [ "Name", "City"] ) pd.DataFrame(grouped_df.size().reset_index(name = "Group_Count"))здесь, grouped_df.size() поднимает уникальный счетчик groupby, а метод reset_index () сбрасывает имя столбца, которым вы хотите его видеть. Наконец, функция pandas Dataframe () вызывается для создания объекта DataFrame.
Я обнаружил, что это работает для меня.
import numpy as np import pandas as pd df1 = pd.DataFrame({ "Name" : ["Alice", "Bob", "Mallory", "Mallory", "Bob" , "Mallory"] , "City" : ["Seattle", "Seattle", "Portland", "Seattle", "Seattle", "Portland"]}) df1['City_count'] = 1 df1['Name_count'] = 1 df1.groupby(['Name', 'City'], as_index=False).count()
возможно, я неправильно понял вопрос, но если вы хотите преобразовать groupby обратно в фрейм данных, который вы можете использовать .to_frame(). я хотел сбросить индекс, когда я это сделал, поэтому я включил и эту часть.
пример кода, не связанный с вопросом
df = df['TIME'].groupby(df['Name']).min() df = df.to_frame() df = df.reset_index(level=['Name',"TIME"])
Я агрегировал с кол-во мудрых данных и хранить в dataframe
almo_grp_data = pd.DataFrame({'Qty_cnt' : almo_slt_models_data.groupby( ['orderDate','Item','State Abv'] )['Qty'].sum()}).reset_index()
ниже Решение может быть проще:
df1.reset_index().groupby( [ "Name", "City"],as_index=False ).count()
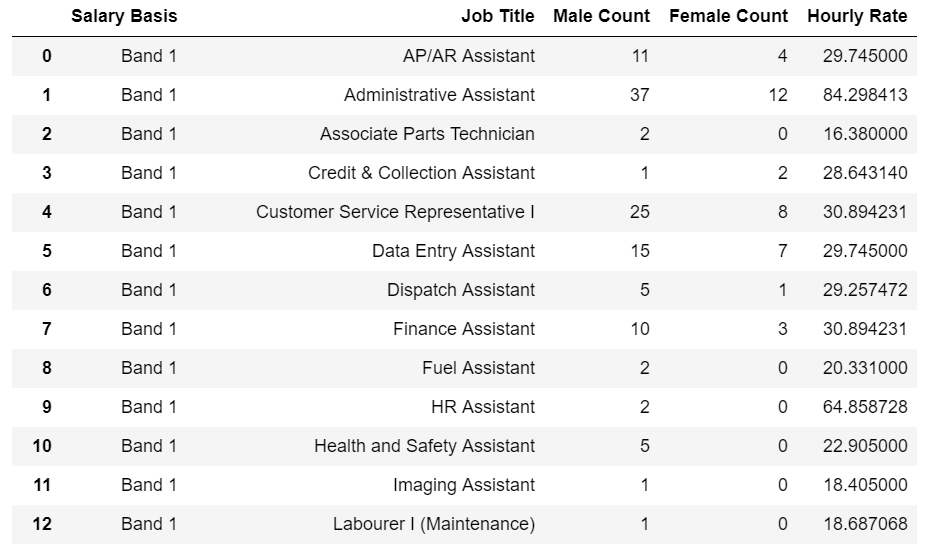
эти решения только частично работали для меня, потому что я делал несколько агрегаций. Вот пример вывода моей группы, которую я хотел преобразовать в фрейм данных:
потому что я хотел больше, чем количество, предоставленное reset_index (), я написал ручной метод для преобразования изображения выше в фрейм данных. Я понимаю, что это не самый питонический / панд способ сделать это, поскольку он довольно многословен и явен, но это было все, что я необходимый. В принципе, использовать reset_index() метод, описанный выше, чтобы начать "монтаж" таблицы данных, затем петли через группу пар сгруппированы в таблицы данных, извлекать показатели, проанализировать свои расчеты в отношении этой таблицы данных, и установите значение в новой сводные таблицы данных.
df_grouped = df[['Salary Basis', 'Job Title', 'Hourly Rate', 'Male Count', 'Female Count']] df_grouped = df_grouped.groupby(['Salary Basis', 'Job Title'], as_index=False) # Grouped gives us the indices we want for each grouping # We cannot convert a groupedby object back to a dataframe, so we need to do it manually # Create a new dataframe to work against df_aggregated = df_grouped.size().to_frame('Total Count').reset_index() df_aggregated['Male Count'] = 0 df_aggregated['Female Count'] = 0 df_aggregated['Job Rate'] = 0 def manualAggregations(indices_array): temp_df = df.iloc[indices_array] return { 'Male Count': temp_df['Male Count'].sum(), 'Female Count': temp_df['Female Count'].sum(), 'Job Rate': temp_df['Hourly Rate'].max() } for name, group in df_grouped: ix = df_grouped.indices[name] calcDict = manualAggregations(ix) for key in calcDict: #Salary Basis, Job Title columns = list(name) df_aggregated.loc[(df_aggregated['Salary Basis'] == columns[0]) & (df_aggregated['Job Title'] == columns[1]), key] = calcDict[key]Если словарь не ваша вещь, вычисления могут быть применены встраиваемые в цикл for:
df_aggregated['Male Count'].loc[(df_aggregated['Salary Basis'] == columns[0]) & (df_aggregated['Job Title'] == columns[1])] = df['Male Count'].iloc[ix].sum()
Comments