Быстрая проверка для NaN в NumPy
Я ищу самый быстрый способ проверить наличие NaN (np.nan) в массиве NumPy X. np.isnan(X) не может быть и речи, так как он строит логический массив shape X.shape, который потенциально гигантские.
пробовал np.nan in X, но это, кажется, не работает, потому что np.nan != np.nan. Есть ли быстрый и эффективный для памяти способ сделать это вообще?
(для тех кто спросит "как гигантский": я не могу сказать. Это проверка ввода кода библиотеки.)
7 ответов:
решение Рэя хорошо. Однако, на моей машине это примерно в 2,5 раза быстрее, чтобы использовать
numpy.sumна местеnumpy.min:In [13]: %timeit np.isnan(np.min(x)) 1000 loops, best of 3: 244 us per loop In [14]: %timeit np.isnan(np.sum(x)) 10000 loops, best of 3: 97.3 us per loopв отличие от
min,sumне требует ветвления, что на современном оборудовании, как правило, довольно дорого. Это вероятно, причина, почемуsumбыстрее.edit вышеуказанный тест был выполнен с одним NaN прямо в середине массива.
интересно отметить, что
minмедленнее в присутствии НАН, чем в их отсутствие. Он также, кажется, становится медленнее, поскольку NaNs приближается к началу массива. С другой стороны,sumпропускная способность кажется постоянной независимо от того, есть ли NaN и где они расположены:In [40]: x = np.random.rand(100000) In [41]: %timeit np.isnan(np.min(x)) 10000 loops, best of 3: 153 us per loop In [42]: %timeit np.isnan(np.sum(x)) 10000 loops, best of 3: 95.9 us per loop In [43]: x[50000] = np.nan In [44]: %timeit np.isnan(np.min(x)) 1000 loops, best of 3: 239 us per loop In [45]: %timeit np.isnan(np.sum(x)) 10000 loops, best of 3: 95.8 us per loop In [46]: x[0] = np.nan In [47]: %timeit np.isnan(np.min(x)) 1000 loops, best of 3: 326 us per loop In [48]: %timeit np.isnan(np.sum(x)) 10000 loops, best of 3: 95.9 us per loop
даже существует принятый ответ, я хотел бы продемонстрировать следующее (С Python 2.7.2 и Numpy 1.6.0 на Vista):
dot(.) основанный, кажется, самый стабильный.In []: x= rand(1e5) In []: %timeit isnan(x.min()) 10000 loops, best of 3: 200 us per loop In []: %timeit isnan(x.sum()) 10000 loops, best of 3: 169 us per loop In []: %timeit isnan(dot(x, x)) 10000 loops, best of 3: 134 us per loop In []: x[5e4]= NaN In []: %timeit isnan(x.min()) 100 loops, best of 3: 4.47 ms per loop In []: %timeit isnan(x.sum()) 100 loops, best of 3: 6.44 ms per loop In []: %timeit isnan(dot(x, x)) 10000 loops, best of 3: 138 us per loop
здесь есть два общих подхода:
- проверять каждый элемент массива на
nanи забратьany.- применить некоторую накопительную операцию, которая сохраняет
nans (напримерsum) и проверить ее результат.хотя первый подход, безусловно, самый чистый, тяжелая оптимизация некоторых кумулятивных операций (особенно тех, которые выполняются в BLAS, например
dot) может сделать это довольно быстро. Обратите внимание, чтоdot, как некоторые другие операции BLAS, многопоточны при определенных условиях. Это объясняет разницу в скорости между различными машинами.
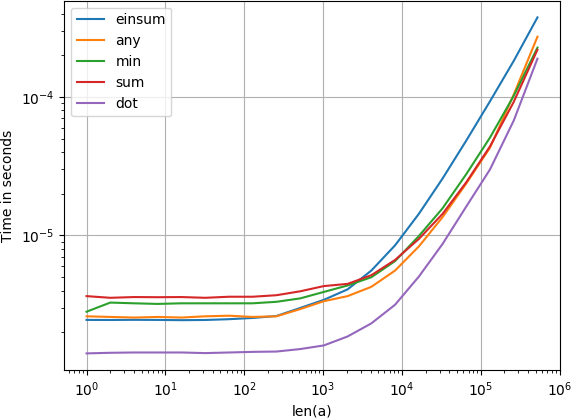
import numpy import perfplot def min(a): return numpy.isnan(numpy.min(a)) def sum(a): return numpy.isnan(numpy.sum(a)) def dot(a): return numpy.isnan(numpy.dot(a, a)) def any(a): return numpy.any(numpy.isnan(a)) def einsum(a): return numpy.isnan(numpy.einsum('i->', a)) perfplot.show( setup=lambda n: numpy.random.rand(n), kernels=[min, sum, dot, any, einsum], n_range=[2**k for k in range(20)], logx=True, logy=True, xlabel='len(a)' )
Если вам удобно с numba это позволяет создать быстрое короткое замыкание (останавливается, как только NaN найден) функция:
import numba as nb import math @nb.njit def anynan(array): array = array.ravel() for i in range(array.size): if math.isnan(array[i]): return True return Falseесли нет
NaNфункции на самом деле может быть медленнее, чемnp.min, Я думаю, что это потому, чтоnp.minиспользует многопроцессорность для больших массивов:import numpy as np array = np.random.random(2000000) %timeit anynan(array) # 100 loops, best of 3: 2.21 ms per loop %timeit np.isnan(array.sum()) # 100 loops, best of 3: 4.45 ms per loop %timeit np.isnan(array.min()) # 1000 loops, best of 3: 1.64 ms per loopно если в массиве есть NaN, особенно если его позиция находится на низких индексах, то это намного быстрее:
array = np.random.random(2000000) array[100] = np.nan %timeit anynan(array) # 1000000 loops, best of 3: 1.93 µs per loop %timeit np.isnan(array.sum()) # 100 loops, best of 3: 4.57 ms per loop %timeit np.isnan(array.min()) # 1000 loops, best of 3: 1.65 ms per loopпохожие результаты могут быть достигнуты с помощью Cython или расширения C, они немного сложнее (или легко доступны как
bottleneck.anynan) но в конечном итоге сделать то же самое, что и мой
С этим связан вопрос о том, как найти первое вхождение Нэн. Это самый быстрый способ справиться с тем, что я знаю:
index = next((i for (i,n) in enumerate(iterable) if n!=n), None)
enter code here
- использовать .любой()
if numpy.isnan(myarray).any()
- numpy.isfinite может быть лучше, чем isnan для проверки
if not np.isfinite(prop).all()
Comments