Выравнивание неглубокого списка в Python [дубликат]
этот вопрос уже есть ответ здесь:
есть ли простой способ сгладить список итераций с пониманием списка или в противном случае, что бы вы все считали лучшим способом сгладить неглубокий список, как это, балансируя производительность и читаемость?
Я попытался сгладить такой список с вложенным списком понимания, как это:
[image for image in menuitem for menuitem in list_of_menuitems]
но я попадаю в беду NameError выбор есть, потому что name 'menuitem' is not defined. После гугла и оглядываясь на переполнение стека, я получил желаемые результаты с reduce о себе:
reduce(list.__add__, map(lambda x: list(x), list_of_menuitems))
но этот метод довольно нечитабельный, потому что мне это нужно list(x) позвоните туда, потому что x-это Django QuerySet объект.
вывод:
спасибо всем, кто внес свой вклад в этот вопрос. Вот краткое изложение того, что я узнал. Я также делаю это Вики сообщества, если другие хотят добавить или исправить эти наблюдения.
мой оригинальный оператор reduce является избыточным и лучше пишется следующим образом:
>>> reduce(list.__add__, (list(mi) for mi in list_of_menuitems))
это правильный синтаксис для понимания вложенного списка (блестящее резюме ДФ!):
>>> [image for mi in list_of_menuitems for image in mi]
но ни один из этих методов не так эффективен, как использование itertools.chain:
>>> from itertools import chain
>>> list(chain(*list_of_menuitems))
и как отмечает @cdleary, это, вероятно, лучший стиль, чтобы избежать * operator magic с помощью chain.from_iterable вот так:
>>> chain = itertools.chain.from_iterable([[1,2],[3],[5,89],[],[6]])
>>> print(list(chain))
>>> [1, 2, 3, 5, 89, 6]
23 ответов:
если вы просто хотите перебрать сглаженную версию структуры данных и не нуждаетесь в индексируемой последовательности, рассмотрите itertools.сеть и компания.
>>> list_of_menuitems = [['image00', 'image01'], ['image10'], []] >>> import itertools >>> chain = itertools.chain(*list_of_menuitems) >>> print(list(chain)) ['image00', 'image01', 'image10']он будет работать на все, что итерируемый, которая должна включать и Iterable s, который, похоже, вы используете в вопросе.
Edit: это, вероятно, так же хорошо, как уменьшить в любом случае, потому что уменьшение будет иметь те же накладные расходы копирования элементы в список, который расширяется.
chainтолько понесет эти (те же) накладные расходы, если вы запуститеlist(chain)В конце.Meta-Edit: на самом деле, это меньше накладных расходов, чем предлагаемое решение вопроса, потому что вы выбрасываете временные списки, которые вы создаете, когда расширяете оригинал с временным.
Edit: как говорит Дж. Ф. Себастьян
itertools.chain.from_iterableво избежание распаковки и вы должны использовать это, чтобы избежать*магия, но приложение timeit показывает незначительную разницу в производительности.
у тебя почти получается! Элемент способ сделать вложенные списки понимания поставить
forоператоры в том же порядке, как они будут идти в регулярных вложенныхforзаявления.таким образом,
for inner_list in outer_list: for item in inner_list: ...соответствует
[... for inner_list in outer_list for item in inner_list]так ты хочешь
[image for menuitem in list_of_menuitems for image in menuitem]
@S. Lott: вы вдохновили меня написать приложение timeit.
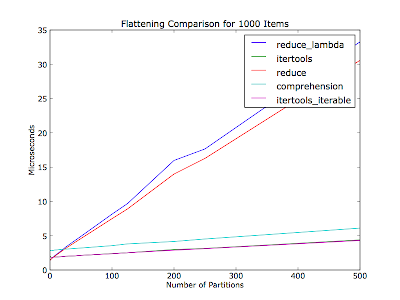
Я полагал, что это также будет зависеть от количества разделов (количество итераторов в списке контейнеров) - ваш комментарий не упоминал, сколько разделов было из тридцати элементов. Этот участок сглаживает тысячу элементов в каждом прогоне, с различным количеством разделов. Элементы равномерно распределены между разделами.
Код (Python 2.6):
#!/usr/bin/env python2.6 """Usage: %prog item_count""" from __future__ import print_function import collections import itertools import operator from timeit import Timer import sys import matplotlib.pyplot as pyplot def itertools_flatten(iter_lst): return list(itertools.chain(*iter_lst)) def itertools_iterable_flatten(iter_iter): return list(itertools.chain.from_iterable(iter_iter)) def reduce_flatten(iter_lst): return reduce(operator.add, map(list, iter_lst)) def reduce_lambda_flatten(iter_lst): return reduce(operator.add, map(lambda x: list(x), [i for i in iter_lst])) def comprehension_flatten(iter_lst): return list(item for iter_ in iter_lst for item in iter_) METHODS = ['itertools', 'itertools_iterable', 'reduce', 'reduce_lambda', 'comprehension'] def _time_test_assert(iter_lst): """Make sure all methods produce an equivalent value. :raise AssertionError: On any non-equivalent value.""" callables = (globals()[method + '_flatten'] for method in METHODS) results = [callable(iter_lst) for callable in callables] if not all(result == results[0] for result in results[1:]): raise AssertionError def time_test(partition_count, item_count_per_partition, test_count=10000): """Run flatten methods on a list of :param:`partition_count` iterables. Normalize results over :param:`test_count` runs. :return: Mapping from method to (normalized) microseconds per pass. """ iter_lst = [[dict()] * item_count_per_partition] * partition_count print('Partition count: ', partition_count) print('Items per partition:', item_count_per_partition) _time_test_assert(iter_lst) test_str = 'flatten(%r)' % iter_lst result_by_method = {} for method in METHODS: setup_str = 'from test import %s_flatten as flatten' % method t = Timer(test_str, setup_str) per_pass = test_count * t.timeit(number=test_count) / test_count print('%20s: %.2f usec/pass' % (method, per_pass)) result_by_method[method] = per_pass return result_by_method if __name__ == '__main__': if len(sys.argv) != 2: raise ValueError('Need a number of items to flatten') item_count = int(sys.argv[1]) partition_counts = [] pass_times_by_method = collections.defaultdict(list) for partition_count in xrange(1, item_count): if item_count % partition_count != 0: continue items_per_partition = item_count / partition_count result_by_method = time_test(partition_count, items_per_partition) partition_counts.append(partition_count) for method, result in result_by_method.iteritems(): pass_times_by_method[method].append(result) for method, pass_times in pass_times_by_method.iteritems(): pyplot.plot(partition_counts, pass_times, label=method) pyplot.legend() pyplot.title('Flattening Comparison for %d Items' % item_count) pyplot.xlabel('Number of Partitions') pyplot.ylabel('Microseconds') pyplot.show()Edit: решил сделать это сообщество Вики.
Примечание:
METHODSвероятно, должен быть накоплен с декоратором, но я думаю, что людям было бы легче читать таким образом.
sum(list of lists, [])будет плющить.l = [['image00', 'image01'], ['image10'], []] print sum(l,[]) # prints ['image00', 'image01', 'image10']
Это решение работает для произвольных глубин вложенности-не только" список списков " глубины, что некоторые (все?) из других решений ограничиваются:
def flatten(x): result = [] for el in x: if hasattr(el, "__iter__") and not isinstance(el, basestring): result.extend(flatten(el)) else: result.append(el) return resultэто рекурсия, которая позволяет произвольную глубину вложенности-пока вы не достигнете максимальной глубины рекурсии, конечно...
Результаты Работы. Исправленный.
import itertools def itertools_flatten( aList ): return list( itertools.chain(*aList) ) from operator import add def reduce_flatten1( aList ): return reduce(add, map(lambda x: list(x), [mi for mi in aList])) def reduce_flatten2( aList ): return reduce(list.__add__, map(list, aList)) def comprehension_flatten( aList ): return list(y for x in aList for y in x)я выровнял 2-уровневый список из 30 пунктов 1000 раз
itertools_flatten 0.00554 comprehension_flatten 0.00815 reduce_flatten2 0.01103 reduce_flatten1 0.01404уменьшить всегда плохой выбор.
в Python 2.6, используя
chain.from_iterable():>>> from itertools import chain >>> list(chain.from_iterable(mi.image_set.all() for mi in h.get_image_menu()))Это позволит избежать создания промежуточного списка.
там, кажется, путаница с
operator.add! Когда вы добавляете два списка вместе, правильный термин для этого -concatне добавлять.operator.concatэто то, что вам нужно использовать.если вы думаете функционально, это так же просто, как это::
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9)) >>> reduce(operator.concat, list2d) (1, 2, 3, 4, 5, 6, 7, 8, 9)вы видите, что reduce уважает тип последовательности, поэтому, когда вы предоставляете кортеж, вы возвращаете кортеж. давайте попробуем со списком::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]] >>> reduce(operator.concat, list2d) [1, 2, 3, 4, 5, 6, 7, 8, 9]Ага, вы получите обратно список.
как насчет производительность::
>>> list2d = [[1,2,3],[4,5,6], [7], [8,9]] >>> %timeit list(itertools.chain.from_iterable(list2d)) 1000000 loops, best of 3: 1.36 µs per loopfrom_iterable довольно быстро! Но это не сравнение, чтобы уменьшить с concat.
>>> list2d = ((1,2,3),(4,5,6), (7,), (8,9)) >>> %timeit reduce(operator.concat, list2d) 1000000 loops, best of 3: 492 ns per loop
С верхней части моей головы, вы можете устранить лямбда:
reduce(list.__add__, map(list, [mi.image_set.all() for mi in list_of_menuitems]))или даже устранить карту, так как у вас уже есть список-comp:
reduce(list.__add__, [list(mi.image_set.all()) for mi in list_of_menuitems])вы также можете просто выразить в виде суммы списков:
sum([list(mi.image_set.all()) for mi in list_of_menuitems], [])
вот правильное решение с использованием списка понимания (они отстают в вопросе):
>>> join = lambda it: (y for x in it for y in x) >>> list(join([[1,2],[3,4,5],[]])) [1, 2, 3, 4, 5]в вашем случае это будет
[image for menuitem in list_of_menuitems for image in menuitem.image_set.all()]или вы могли бы использовать
joinи сказалjoin(menuitem.image_set.all() for menuitem in list_of_menuitems)в любом случае, gotcha было гнездование
forпетли.
вы пробовали плющить? От matplotlib.cbook.сплющить(seq, scalarp=) ?
l=[[1,2,3],[4,5,6], [7], [8,9]]*33 run("list(flatten(l))") 3732 function calls (3303 primitive calls) in 0.007 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 0.007 0.007 <string>:1(<module>) 429 0.001 0.000 0.001 0.000 cbook.py:475(iterable) 429 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like) 429 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string) 727/298 0.001 0.000 0.007 0.000 cbook.py:605(flatten) 429 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray) 858 0.001 0.000 0.001 0.000 {isinstance} 429 0.000 0.000 0.000 0.000 {iter} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} l=[[1,2,3],[4,5,6], [7], [8,9]]*66 run("list(flatten(l))") 7461 function calls (6603 primitive calls) in 0.007 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 0.007 0.007 <string>:1(<module>) 858 0.001 0.000 0.001 0.000 cbook.py:475(iterable) 858 0.002 0.000 0.003 0.000 cbook.py:484(is_string_like) 858 0.002 0.000 0.006 0.000 cbook.py:565(is_scalar_or_string) 1453/595 0.001 0.000 0.007 0.000 cbook.py:605(flatten) 858 0.000 0.000 0.001 0.000 core.py:5641(isMaskedArray) 1716 0.001 0.000 0.001 0.000 {isinstance} 858 0.000 0.000 0.000 0.000 {iter} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} l=[[1,2,3],[4,5,6], [7], [8,9]]*99 run("list(flatten(l))") 11190 function calls (9903 primitive calls) in 0.010 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 0.010 0.010 <string>:1(<module>) 1287 0.002 0.000 0.002 0.000 cbook.py:475(iterable) 1287 0.003 0.000 0.004 0.000 cbook.py:484(is_string_like) 1287 0.002 0.000 0.009 0.000 cbook.py:565(is_scalar_or_string) 2179/892 0.001 0.000 0.010 0.000 cbook.py:605(flatten) 1287 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray) 2574 0.001 0.000 0.001 0.000 {isinstance} 1287 0.000 0.000 0.000 0.000 {iter} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} l=[[1,2,3],[4,5,6], [7], [8,9]]*132 run("list(flatten(l))") 14919 function calls (13203 primitive calls) in 0.013 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 1 0.000 0.000 0.013 0.013 <string>:1(<module>) 1716 0.002 0.000 0.002 0.000 cbook.py:475(iterable) 1716 0.004 0.000 0.006 0.000 cbook.py:484(is_string_like) 1716 0.003 0.000 0.011 0.000 cbook.py:565(is_scalar_or_string) 2905/1189 0.002 0.000 0.013 0.000 cbook.py:605(flatten) 1716 0.001 0.000 0.001 0.000 core.py:5641(isMaskedArray) 3432 0.001 0.000 0.001 0.000 {isinstance} 1716 0.001 0.000 0.001 0.000 {iter} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler'обновление Что навело меня на другую мысль:
l=[[1,2,3],[4,5,6], [7], [8,9]]*33 run("flattenlist(l)") 564 function calls (432 primitive calls) in 0.000 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 133/1 0.000 0.000 0.000 0.000 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.000 0.000 0.000 0.000 <string>:1(<module>) 429 0.000 0.000 0.000 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} l=[[1,2,3],[4,5,6], [7], [8,9]]*66 run("flattenlist(l)") 1125 function calls (861 primitive calls) in 0.001 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 265/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.000 0.000 0.001 0.001 <string>:1(<module>) 858 0.000 0.000 0.000 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} l=[[1,2,3],[4,5,6], [7], [8,9]]*99 run("flattenlist(l)") 1686 function calls (1290 primitive calls) in 0.001 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 397/1 0.001 0.000 0.001 0.001 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.000 0.000 0.001 0.001 <string>:1(<module>) 1287 0.000 0.000 0.000 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} l=[[1,2,3],[4,5,6], [7], [8,9]]*132 run("flattenlist(l)") 2247 function calls (1719 primitive calls) in 0.002 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 529/1 0.001 0.000 0.002 0.002 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.000 0.000 0.002 0.002 <string>:1(<module>) 1716 0.001 0.000 0.001 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} l=[[1,2,3],[4,5,6], [7], [8,9]]*1320 run("flattenlist(l)") 22443 function calls (17163 primitive calls) in 0.016 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 5281/1 0.011 0.000 0.016 0.016 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.000 0.000 0.016 0.016 <string>:1(<module>) 17160 0.005 0.000 0.005 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}Итак, чтобы проверить, насколько это эффективно, когда рекурсивный становится глубже: насколько глубже?
l=[[1,2,3],[4,5,6], [7], [8,9]]*1320 new=[l]*33 run("flattenlist(new)") 740589 function calls (566316 primitive calls) in 0.418 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 174274/1 0.281 0.000 0.417 0.417 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.001 0.001 0.418 0.418 <string>:1(<module>) 566313 0.136 0.000 0.136 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} new=[l]*66 run("flattenlist(new)") 1481175 function calls (1132629 primitive calls) in 0.809 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 348547/1 0.542 0.000 0.807 0.807 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.002 0.002 0.809 0.809 <string>:1(<module>) 1132626 0.266 0.000 0.266 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} new=[l]*99 run("flattenlist(new)") 2221761 function calls (1698942 primitive calls) in 1.211 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 522820/1 0.815 0.000 1.208 1.208 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.002 0.002 1.211 1.211 <string>:1(<module>) 1698939 0.393 0.000 0.393 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} new=[l]*132 run("flattenlist(new)") 2962347 function calls (2265255 primitive calls) in 1.630 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 697093/1 1.091 0.000 1.627 1.627 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.003 0.003 1.630 1.630 <string>:1(<module>) 2265252 0.536 0.000 0.536 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects} new=[l]*1320 run("flattenlist(new)") 29623443 function calls (22652523 primitive calls) in 16.103 seconds Ordered by: standard name ncalls tottime percall cumtime percall filename:lineno(function) 6970921/1 10.842 0.000 16.069 16.069 <ipython-input-55-39b139bad497>:4(flattenlist) 1 0.034 0.034 16.103 16.103 <string>:1(<module>) 22652520 5.227 0.000 5.227 0.000 {isinstance} 1 0.000 0.000 0.000 0.000 {method 'disable' of '_lsprof.Profiler' objects}Я буду держать пари "flattenlist" я собираюсь использовать это, а не matploblib в течение длительного времени, если я не хочу генератор урожайности и быстрый результат, как "flatten" использует в матплоблиб.cbook
этого, быстро.
- а вот код
:
typ=(list,tuple) def flattenlist(d): thelist = [] for x in d: if not isinstance(x,typ): thelist += [x] else: thelist += flattenlist(x) return thelist
эта версия является генератор.Настроить его, если вы хотите список.
def list_or_tuple(l): return isinstance(l,(list,tuple)) ## predicate will select the container to be flattened ## write your own as required ## this one flattens every list/tuple def flatten(seq,predicate=list_or_tuple): ## recursive generator for i in seq: if predicate(seq): for j in flatten(i): yield j else: yield iвы можете добавить предикат ,если хотите сгладить те, которые удовлетворяют условию
взято из Поваренной книги python
по моему опыту, наиболее эффективный способ сгладить список списков:
flat_list = [] map(flat_list.extend, list_of_list)некоторые сравнения timeit с другими предложенными методами:
list_of_list = [range(10)]*1000 %timeit flat_list=[]; map(flat_list.extend, list_of_list) #10000 loops, best of 3: 119 µs per loop %timeit flat_list=list(itertools.chain.from_iterable(list_of_list)) #1000 loops, best of 3: 210 µs per loop %timeit flat_list=[i for sublist in list_of_list for i in sublist] #1000 loops, best of 3: 525 µs per loop %timeit flat_list=reduce(list.__add__,list_of_list) #100 loops, best of 3: 18.1 ms per loopтеперь, увеличение эффективности появляется лучше при обработке более длинных подсписков:
list_of_list = [range(1000)]*10 %timeit flat_list=[]; map(flat_list.extend, list_of_list) #10000 loops, best of 3: 60.7 µs per loop %timeit flat_list=list(itertools.chain.from_iterable(list_of_list)) #10000 loops, best of 3: 176 µs per loopи этот метод также работает с любой итерационный объекта:
class SquaredRange(object): def __init__(self, n): self.range = range(n) def __iter__(self): for i in self.range: yield i**2 list_of_list = [SquaredRange(5)]*3 flat_list = [] map(flat_list.extend, list_of_list) print flat_list #[0, 1, 4, 9, 16, 0, 1, 4, 9, 16, 0, 1, 4, 9, 16]
вот версия, работающая для нескольких уровней списка с помощью
collectons.Iterable:import collections def flatten(o): result = [] for i in o: if isinstance(i, collections.Iterable): result.extend(flatten(i)) else: result.append(i) return result
о:
from operator import add reduce(add, map(lambda x: list(x.image_set.all()), [mi for mi in list_of_menuitems]))но Гвидо рекомендует не выполнять слишком много в одной строке кода, поскольку это снижает читаемость. Существует минимальный, если таковые имеются, прирост производительности, выполняя то, что вы хотите в одной строке против нескольких строк.
pylab обеспечивает сплющивание: ссылка на numpy flatten
Если вы ищете встроенный, простой, один лайнер вы можете использовать:
a = [[1, 2, 3], [4, 5, 6] b = [i[x] for i in a for x in range(len(i))] print bвозвращает
[1, 2, 3, 4, 5, 6]
Если каждый элемент в списке является строкой (и любые строки внутри этих строк используют " ", а не"'), вы можете использовать регулярные выражения (
reмодуль)>>> flattener = re.compile("\'.*?\'") >>> flattener <_sre.SRE_Pattern object at 0x10d439ca8> >>> stred = str(in_list) >>> outed = flattener.findall(stred)выше преобразует код in_list в строку, использует регулярное выражение, чтобы найти все подстроки в кавычках (т. е. каждый элемент списка) и выплевывает их в виде списка.
если у вас есть плоский более сложный список с не повторяющимися элементами или с глубиной более 2 Вы можете использовать следующую функцию:
def flat_list(list_to_flat): if not isinstance(list_to_flat, list): yield list_to_flat else: for item in list_to_flat: yield from flat_list(item)он вернет объект генератора, который вы можете преобразовать в список с
простой альтернативой является использование библиотеки numpy объединить но он преобразует содержимое в float:
import numpy as np print np.concatenate([[1,2],[3],[5,89],[],[6]]) # array([ 1., 2., 3., 5., 89., 6.]) print list(np.concatenate([[1,2],[3],[5,89],[],[6]])) # [ 1., 2., 3., 5., 89., 6.]
самый простой способ сделать это в Python 2 или 3-Использовать оборотень библиотека с помощью
pip install morph.код:
import morph list = [[1,2],[3],[5,89],[],[6]] flattened_list = morph.flatten(list) # returns [1, 2, 3, 5, 89, 6]
def flatten(items): for i in items: if hasattr(i, '__iter__'): for m in flatten(i): yield m else: yield i
In Python 3.4 вы сможете делать:
[*innerlist for innerlist in outer_list]
Comments