Создание тепловой карты в MatPlotLib с помощью набора данных scatter
У меня есть набор точек данных X,Y (около 10k), которые легко построить в виде точечной диаграммы, но которые я хотел бы представить в виде тепловой карты.
Я просмотрел примеры в MatPlotLib, и все они, похоже, уже начинаются со значений ячеек heatmap для создания изображения.
есть ли метод, который преобразует кучу x, y, все разные, в тепловую карту (где зоны с более высокой частотой x,y были бы "теплее")?
8 ответов:
если вы не хотите, шестигранники, вы можете использовать NumPy и обратно в
histogram2dфункция:import numpy as np import numpy.random import matplotlib.pyplot as plt # Generate some test data x = np.random.randn(8873) y = np.random.randn(8873) heatmap, xedges, yedges = np.histogram2d(x, y, bins=50) extent = [xedges[0], xedges[-1], yedges[0], yedges[-1]] plt.clf() plt.imshow(heatmap.T, extent=extent, origin='lower') plt.show()это делает тепловую карту 50x50. Если вы хотите, скажем, 512x384, вы можете поставить
bins=(512, 384)в вызовеhistogram2d.пример:
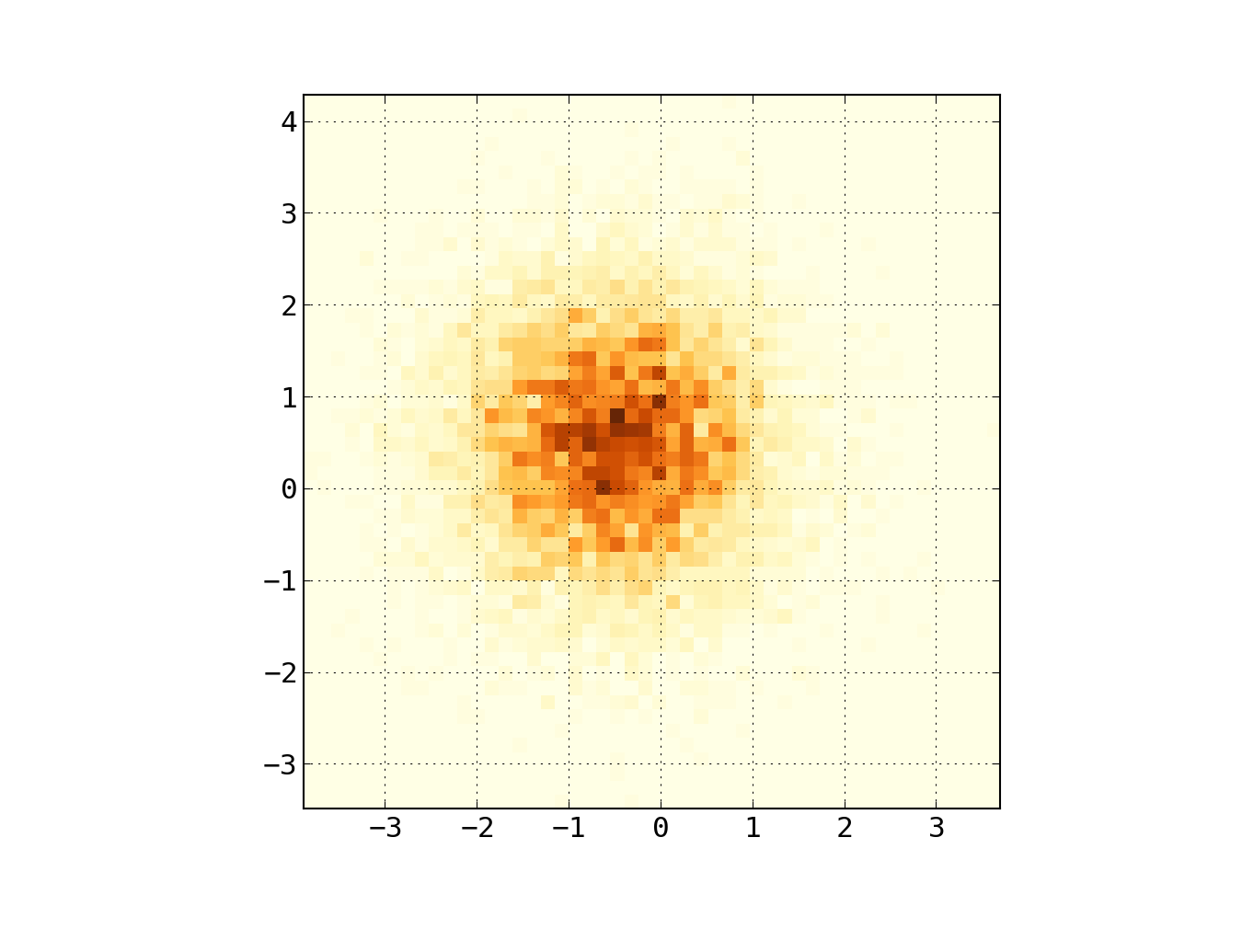
In Matplotlib лексикон, я думаю, вы хотите hexbin сюжет.
Если вы не знакомы с этим типом сюжета, это просто двумерной гистограммы в котором XY-плоскость мозаична регулярной сеткой шестиугольников.
таким образом, из гистограммы вы можете просто подсчитать количество точек, попадающих в каждый шестиугольник, дискретизировать область построения как набор windows, назначьте каждую точку для одного из этих окон; наконец, сопоставьте окна на цвет блока, а у вас есть схема hexbin.
хотя менее часто используется, чем, например, круги или квадраты, что шестиугольники являются лучшим выбором для геометрии контейнера биннинга интуитивно понятно:
шестигранники есть симметрия ближайших соседей (например, квадратные ящики не делают, например, расстояние С точка на границе квадрата до точка внутри этого квадрата находится не везде равны) и
шестиугольник-это самый высокий N-многоугольник, который дает обычный самолет тесселяция (т. е. вы можете безопасно смоделировать свой кухонный пол с шестиугольными плитками, потому что у вас не будет пустого пространства между плитками, когда вы закончите-не верно для всех других более высоких-n, n >= 7, полигонов).
( Matplotlib использует термин hexbin сюжет; так что (AFAIK) все построение библиотеки на R; все же я не знаю, является ли это общепринятым термином для сюжетов этого типа, хотя я подозреваю, что это вероятно, учитывая, что hexbin сокращенно гексагональная дискретизация, который описывает существенный шаг в подготовке данных для отображения.)
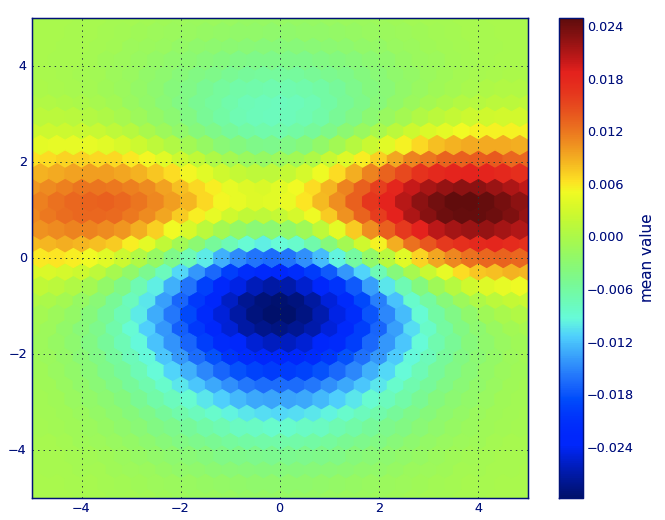
from matplotlib import pyplot as PLT from matplotlib import cm as CM from matplotlib import mlab as ML import numpy as NP n = 1e5 x = y = NP.linspace(-5, 5, 100) X, Y = NP.meshgrid(x, y) Z1 = ML.bivariate_normal(X, Y, 2, 2, 0, 0) Z2 = ML.bivariate_normal(X, Y, 4, 1, 1, 1) ZD = Z2 - Z1 x = X.ravel() y = Y.ravel() z = ZD.ravel() gridsize=30 PLT.subplot(111) # if 'bins=None', then color of each hexagon corresponds directly to its count # 'C' is optional--it maps values to x-y coordinates; if 'C' is None (default) then # the result is a pure 2D histogram PLT.hexbin(x, y, C=z, gridsize=gridsize, cmap=CM.jet, bins=None) PLT.axis([x.min(), x.max(), y.min(), y.max()]) cb = PLT.colorbar() cb.set_label('mean value') PLT.show()
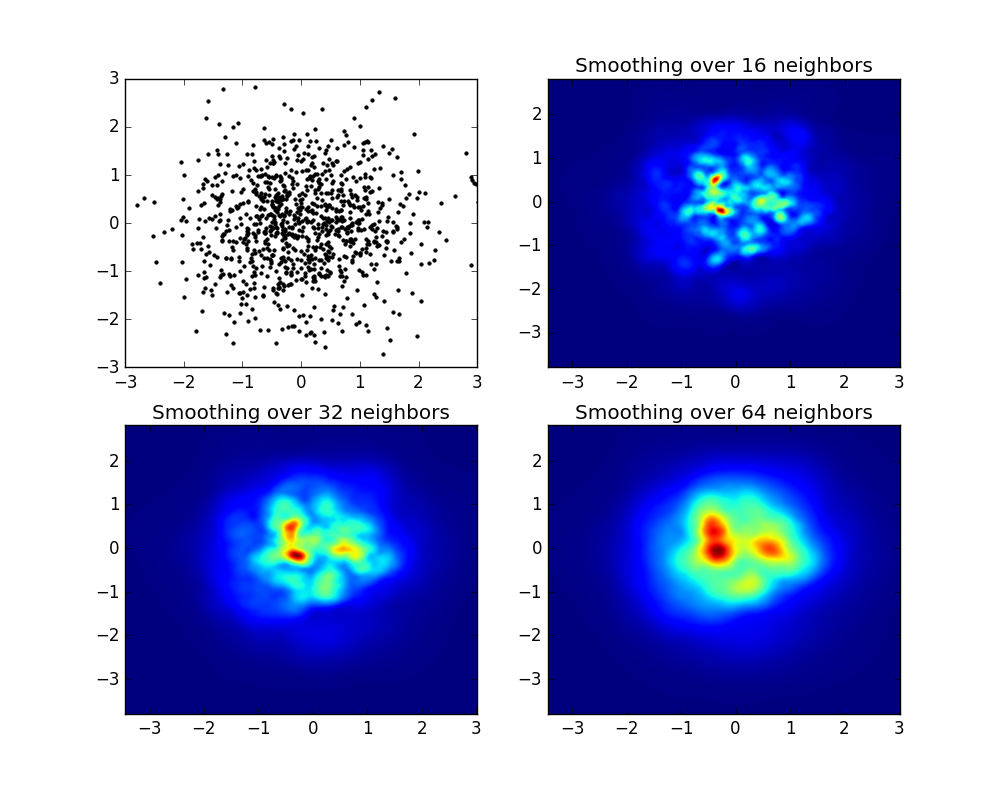
вместо использования np.hist2d, который в целом производит довольно уродливые гистограммы, я хотел бы переработать py-sphviewer, пакет python для рендеринга моделирования частиц с использованием адаптивного ядра сглаживания, который можно легко установить из pip (см. документацию по веб-странице). Рассмотрим следующий код, который основан на примере:
import numpy as np import numpy.random import matplotlib.pyplot as plt import sphviewer as sph def myplot(x, y, nb=32, xsize=500, ysize=500): xmin = np.min(x) xmax = np.max(x) ymin = np.min(y) ymax = np.max(y) x0 = (xmin+xmax)/2. y0 = (ymin+ymax)/2. pos = np.zeros([3, len(x)]) pos[0,:] = x pos[1,:] = y w = np.ones(len(x)) P = sph.Particles(pos, w, nb=nb) S = sph.Scene(P) S.update_camera(r='infinity', x=x0, y=y0, z=0, xsize=xsize, ysize=ysize) R = sph.Render(S) R.set_logscale() img = R.get_image() extent = R.get_extent() for i, j in zip(xrange(4), [x0,x0,y0,y0]): extent[i] += j print extent return img, extent fig = plt.figure(1, figsize=(10,10)) ax1 = fig.add_subplot(221) ax2 = fig.add_subplot(222) ax3 = fig.add_subplot(223) ax4 = fig.add_subplot(224) # Generate some test data x = np.random.randn(1000) y = np.random.randn(1000) #Plotting a regular scatter plot ax1.plot(x,y,'k.', markersize=5) ax1.set_xlim(-3,3) ax1.set_ylim(-3,3) heatmap_16, extent_16 = myplot(x,y, nb=16) heatmap_32, extent_32 = myplot(x,y, nb=32) heatmap_64, extent_64 = myplot(x,y, nb=64) ax2.imshow(heatmap_16, extent=extent_16, origin='lower', aspect='auto') ax2.set_title("Smoothing over 16 neighbors") ax3.imshow(heatmap_32, extent=extent_32, origin='lower', aspect='auto') ax3.set_title("Smoothing over 32 neighbors") #Make the heatmap using a smoothing over 64 neighbors ax4.imshow(heatmap_64, extent=extent_64, origin='lower', aspect='auto') ax4.set_title("Smoothing over 64 neighbors") plt.show()которая производит следующим образом:
Как вы видите, изображения выглядят довольно красиво, и мы можем идентифицировать различные подструктуры на нем. Эти изображения строятся с распределением заданного веса для каждой точки в пределах определенной области, определяемой длиной сглаживания, которая в свою очередь задается расстоянием до ближайшего nb сосед (я выбрал 16, 32 и 64 для примеров). Таким образом, области с более высокой плотностью обычно распределены по меньшим областям по сравнению с областями с более низкой плотностью.
функция myplot - это просто очень простая функция, которую я написал,чтобы дать данные x, y для py-sphviewer, чтобы сделать магию.
Edit: для лучшего приближения ответа Алехандро см. ниже.
Я знаю, что это старый вопрос, но хотел добавить что-то к anwser Алехандро: если вы хотите хорошее сглаженное изображение без использования py-sphviewer вы можете вместо этого использовать
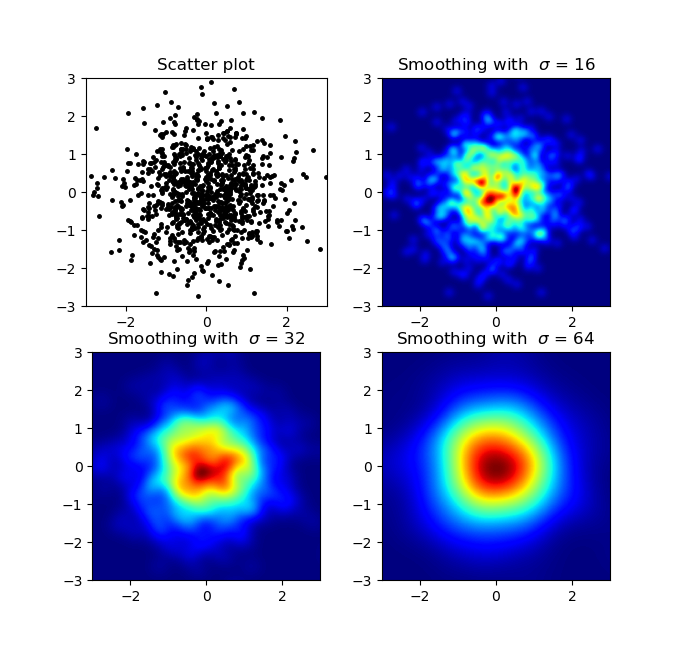
np.histogram2dи применить гауссов фильтр (отscipy.ndimage.filters) на карту:import numpy as np import matplotlib.pyplot as plt import matplotlib.cm as cm from scipy.ndimage.filters import gaussian_filter def myplot(x, y, s, bins=1000): heatmap, xedges, yedges = np.histogram2d(x, y, bins=bins) heatmap = gaussian_filter(heatmap, sigma=s) extent = [xedges[0], xedges[-1], yedges[0], yedges[-1]] return heatmap.T, extent fig, axs = plt.subplots(2, 2) # Generate some test data x = np.random.randn(1000) y = np.random.randn(1000) sigmas = [0, 16, 32, 64] for ax, s in zip(axs.flatten(), sigmas): if s == 0: ax.plot(x, y, 'k.', markersize=5) ax.set_title("Scatter plot") else: img, extent = myplot(x, y, s) ax.imshow(img, extent=extent, origin='lower', cmap=cm.jet) ax.set_title("Smoothing with $\sigma$ = %d" % s) plt.show()выдает:
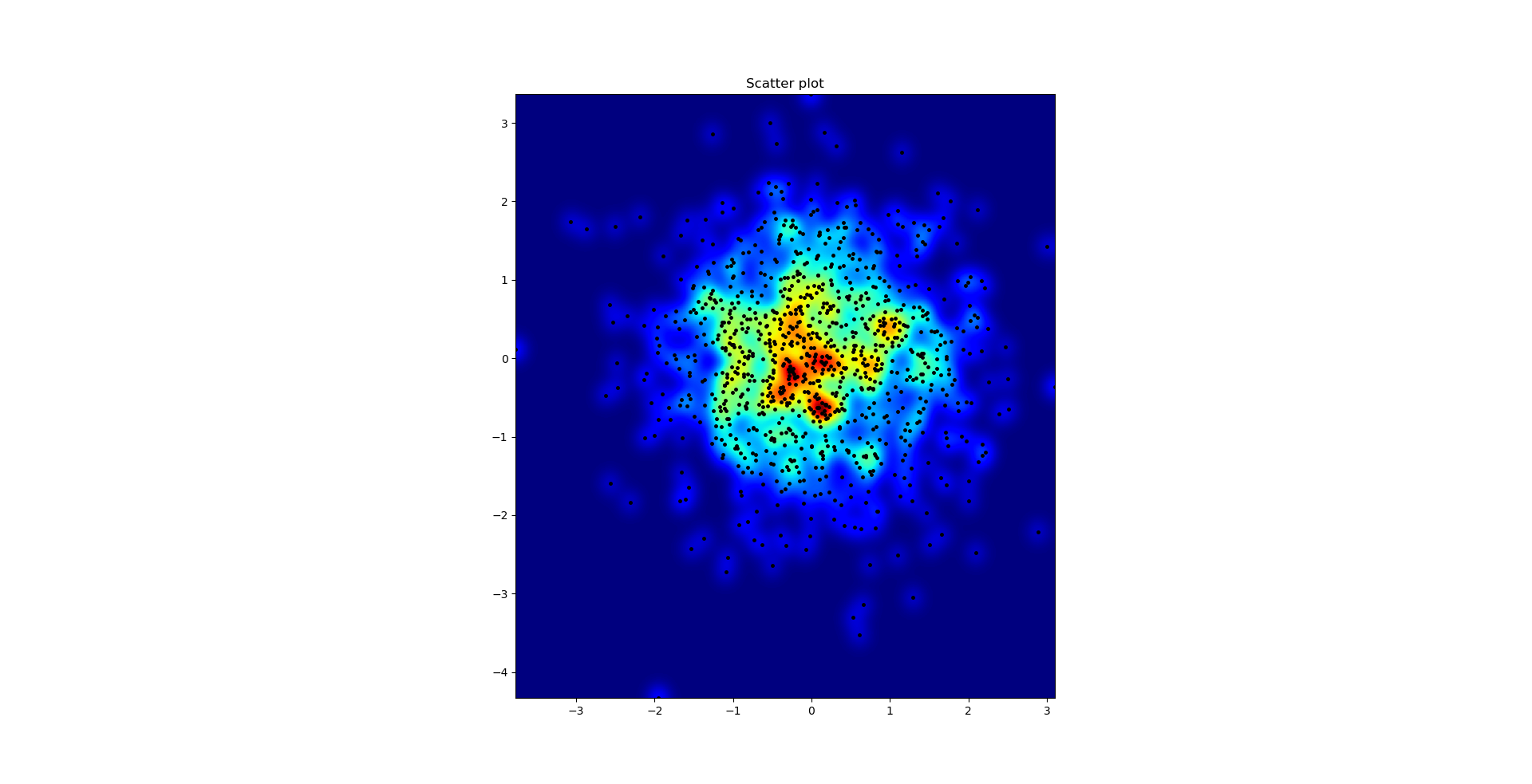
график рассеяния и s=16 нанесены поверх друг друга для Agape Gal'lo (нажмите для лучшего обзора):
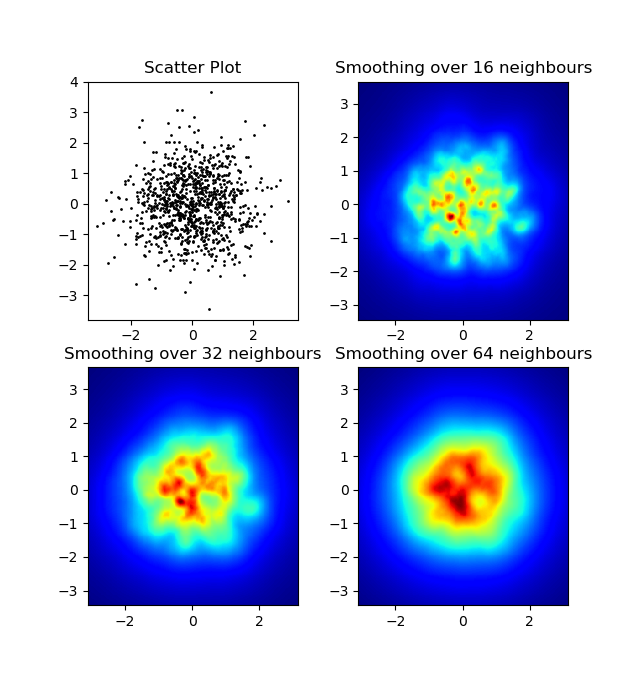
n ближайшие точки в данных. Этот метод имеет высокое разрешение довольно вычислительно дорогой и я думаю, что есть более быстрый способ, так что дайте мне знать, если у вас есть какие-либо улучшения. В любом случае, вот код:import numpy as np import matplotlib.pyplot as plt import matplotlib.cm as cm def data_coord2view_coord(p, vlen, pmin, pmax): dp = pmax - pmin dv = (p - pmin) / dp * vlen return dv def nearest_neighbours(xs, ys, reso, n_neighbours): im = np.zeros([reso, reso]) extent = [np.min(xs), np.max(xs), np.min(ys), np.max(ys)] xv = data_coord2view_coord(xs, reso, extent[0], extent[1]) yv = data_coord2view_coord(ys, reso, extent[2], extent[3]) for x in range(reso): for y in range(reso): xp = (xv - x) yp = (yv - y) d = np.sqrt(xp**2 + yp**2) im[y][x] = 1 / np.sum(d[np.argpartition(d.ravel(), n_neighbours)[:n_neighbours]]) return im, extent n = 1000 xs = np.random.randn(n) ys = np.random.randn(n) resolution = 250 fig, axes = plt.subplots(2, 2) for ax, neighbours in zip(axes.flatten(), [0, 16, 32, 64]): if neighbours == 0: ax.plot(xs, ys, 'k.', markersize=2) ax.set_aspect('equal') ax.set_title("Scatter Plot") else: im, extent = nearest_neighbours(xs, ys, resolution, neighbours) ax.imshow(im, origin='lower', extent=extent, cmap=cm.jet) ax.set_title("Smoothing over %d neighbours" % neighbours) ax.set_xlim(extent[0], extent[1]) ax.set_ylim(extent[2], extent[3]) plt.show()результат:
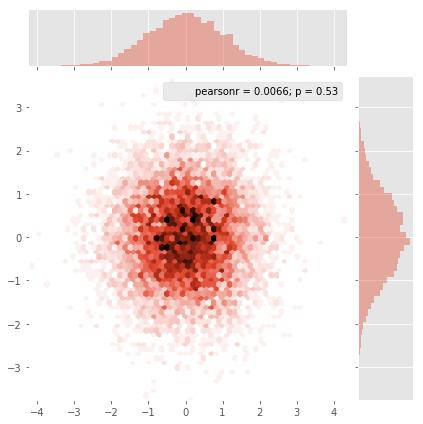
Seaborn теперь имеет функция jointplot который должен хорошо работать здесь:
import numpy as np import seaborn as sns import matplotlib.pyplot as plt # Generate some test data x = np.random.randn(8873) y = np.random.randn(8873) sns.jointplot(x=x, y=y, kind='hex') plt.show()
сделать 2-мерный массив, который соответствует ячейкам в конечном изображении, называется say
heatmap_cellsи создать его как все нули.выберите два коэффициента масштабирования, которые определяют разницу между каждым элементом массива в вещественных единицах, для каждого измерения, скажем
x_scaleиy_scale. Выберите их таким образом, чтобы все ваши точки данных попадали в пределы массива тепловой карты.для каждой точки данных с
x_valueиy_value:
heatmap_cells[floor(x_value/x_scale),floor(y_value/y_scale)]+=1
и первый вопрос был... как преобразовать значения рассеяния в значения сетки, верно?
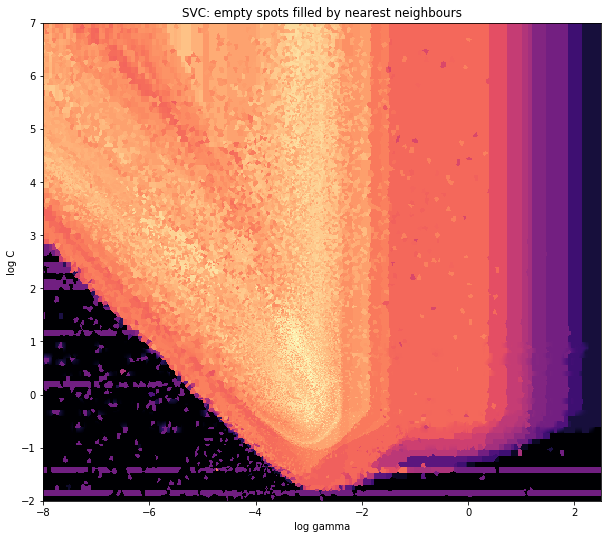
histogram2dподсчитывает частоту на ячейку, однако, если у вас есть другие данные на ячейку, чем просто частота, вам потребуется дополнительная работа.x = data_x # between -10 and 4, log-gamma of an svc y = data_y # between -4 and 11, log-C of an svc z = data_z #between 0 and 0.78, f1-values from a difficult datasetИтак, у меня есть набор данных с Z-результатами для координат X и Y. Тем не менее, я вычислял несколько точек за пределами области интереса (большие пробелы) и кучи точек в небольшой области интереса.
Да вот это становится сложнее, но и веселее. Некоторые библиотеки (извините):
from matplotlib import pyplot as plt from matplotlib import cm import numpy as np from scipy.interpolate import griddatapyplot-это мой графический движок сегодня, cm-это диапазон цветовых карт с некоторым выбором initeresting. numpy для расчетов, и griddata для прикрепления значений к фиксированной сетке.
последнее важно, особенно потому, что частота точек xy не равномерно распределена в моих данных. Во-первых, давайте начнем с некоторых границ, соответствующих моим данным и произвольному размеру сетки. Оригинал данные имеют точки данных также за пределами этих границ x и y.
#determine grid boundaries gridsize = 500 x_min = -8 x_max = 2.5 y_min = -2 y_max = 7Итак, мы определили сетку с 500 пикселями между минимальными и максимальными значениями x и y.
в моих данных есть много больше, чем 500 значений, доступных в области высокого интереса; в то время как в области низкого интереса нет даже 200 значений в общей сетке; между графическими границами
x_minиx_maxеще меньше.так что для получения хорошей картины, задача состоит в том, чтобы получить среднее значение для высоких процентных значений и заполнить пробелы в другом месте.
теперь я определяю свою сетку. Для каждой пары xx-yy я хочу иметь цвет.
xx = np.linspace(x_min, x_max, gridsize) # array of x values yy = np.linspace(y_min, y_max, gridsize) # array of y values grid = np.array(np.meshgrid(xx, yy.T)) grid = grid.reshape(2, grid.shape[1]*grid.shape[2]).Tпочему странная форма? scipy.griddata хочет форму (n, D).
Griddata вычисляет одно значение на точку в сетке, с помощью предопределенного метода. Я выбираю "ближайший" - пустые точки сетки будут заполнены значениями из ближайшего соседа. Это выглядит так, как будто области с меньшим количеством информации есть большие ячейки (даже если это не так). Можно было бы выбрать интерполяцию "линейной", тогда области с меньшей информацией выглядят менее резкими. Дело вкуса, правда.
points = np.array([x, y]).T # because griddata wants it that way z_grid2 = griddata(points, z, grid, method='nearest') # you get a 1D vector as result. Reshape to picture format! z_grid2 = z_grid2.reshape(xx.shape[0], yy.shape[0])и хоп, мы передаем matplotlib для отображения сюжета
fig = plt.figure(1, figsize=(10, 10)) ax1 = fig.add_subplot(111) ax1.imshow(z_grid2, extent=[x_min, x_max,y_min, y_max, ], origin='lower', cmap=cm.magma) ax1.set_title("SVC: empty spots filled by nearest neighbours") ax1.set_xlabel('log gamma') ax1.set_ylabel('log C') plt.show()вокруг заостренной части V-образной формы, вы видите, что я сделал много вычислений во время поиска сладкого пятна, тогда как менее интересные части почти везде имеют более низкий разрешение.
Comments