Получение данных для построения гистограммы
есть ли способ указать размеры ячеек в MySQL? Прямо сейчас я пытаюсь выполнить следующий SQL-запрос:
select total, count(total) from faults GROUP BY total;
данные, которые генерируются достаточно хорошо, но есть просто слишком много строк. Мне нужен способ сгруппировать данные в предопределенные ячейки. Я могу сделать это с помощью языка сценариев, но есть ли способ сделать это непосредственно в SQL?
пример:
+-------+--------------+
| total | count(total) |
+-------+--------------+
| 30 | 1 |
| 31 | 2 |
| 33 | 1 |
| 34 | 3 |
| 35 | 2 |
| 36 | 6 |
| 37 | 3 |
| 38 | 2 |
| 41 | 1 |
| 42 | 5 |
| 43 | 1 |
| 44 | 7 |
| 45 | 4 |
| 46 | 3 |
| 47 | 2 |
| 49 | 3 |
| 50 | 2 |
| 51 | 3 |
| 52 | 4 |
| 53 | 2 |
| 54 | 1 |
| 55 | 3 |
| 56 | 4 |
| 57 | 4 |
| 58 | 2 |
| 59 | 2 |
| 60 | 4 |
| 61 | 1 |
| 63 | 2 |
| 64 | 5 |
| 65 | 2 |
| 66 | 3 |
| 67 | 5 |
| 68 | 5 |
------------------------
Я ищу:
+------------+---------------+
| total | count(total) |
+------------+---------------+
| 30 - 40 | 23 |
| 40 - 50 | 15 |
| 50 - 60 | 51 |
| 60 - 70 | 45 |
------------------------------
Я думаю, это не может быть достигнуто в прямом смысле, но ссылка на любую связанную хранимую процедуру также была бы прекрасна.
10 ответов:
Это пост о супер-быстрый-и-грязный способ создания гистограммы в MySQL для числовых значений.
есть несколько других способов создания гистограмм, которые лучше и более гибкий, используя операторы CASE и другие типы сложной логики. Этот метод побеждает меня снова и снова, так как это так просто чтобы изменить для каждого случая использования, и так коротко и лаконично. Вот как ты ... сделай это:
SELECT ROUND(numeric_value, -2) AS bucket, COUNT(*) AS COUNT, RPAD('', LN(COUNT(*)), '*') AS bar FROM my_table GROUP BY bucket;просто изменить numeric_value к чему бы ни была ваша колонка, измените округление приращения, и все. Я сделал решетку в логарифмическая шкала, так что они не растут слишком много, когда у вас есть большое значение.
numeric_value должно быть смещено в операции округления, на основе приращения округления, чтобы гарантировать, что первый блок содержит столько элементов, сколько следующие блоки.
например, с круглым (numeric_value, -1), numeric_value в диапазоне [0,4] (5 элементов) будет помещается в первое ведро, в то время как [5,14] (10 элементов) во втором, [15,24] в третьем, если numeric_value не смещается соответствующим образом через раунд(numeric_value - 5, -1).
Это пример такого запроса на некоторые случайные данные, что выглядит довольно сладкий. Достаточно хорошо для быстрой оценки данных.
+--------+----------+-----------------+ | bucket | count | bar | +--------+----------+-----------------+ | -500 | 1 | | | -400 | 2 | * | | -300 | 2 | * | | -200 | 9 | ** | | -100 | 52 | **** | | 0 | 5310766 | *************** | | 100 | 20779 | ********** | | 200 | 1865 | ******** | | 300 | 527 | ****** | | 400 | 170 | ***** | | 500 | 79 | **** | | 600 | 63 | **** | | 700 | 35 | **** | | 800 | 14 | *** | | 900 | 15 | *** | | 1000 | 6 | ** | | 1100 | 7 | ** | | 1200 | 8 | ** | | 1300 | 5 | ** | | 1400 | 2 | * | | 1500 | 4 | * | +--------+----------+-----------------+некоторые примечания: диапазоны, которые не совпадают, не будут отображаться в графе - у вас не будет нуля в столбце count. Кроме того, я использую Круглая функция здесь. Вы можете так же легко заменить его на усечение если вы чувствуете, что это имеет больше смысла для вас.
Я нашел его здесь http://blog.shlomoid.com/2011/08/how-to-quickly-create-histogram-in.html
Майк DelGaudio является, как я это делаю, но с небольшим изменением:
select floor(mycol/10)*10 as bin_floor, count(*) from mytable group by 1 order by 1преимущество? Вы можете сделать бункеры как большие или как маленькие, как вы хотите. Ящики размером 100?
floor(mycol/100)*100. Бункеры 5-го размера?floor(mycol/5)*5.Бернардо.
SELECT b.*,count(*) as total FROM bins b left outer join table1 a on a.value between b.min_value and b.max_value group by b.min_valueячейки таблицы содержат столбцы min_value и max_value, которые определяют ячейки. обратите внимание, что оператор "присоединиться... на x между y и z " включено.
table1-это имя таблицы данных
ответ Офри Равива очень близок, но неверен. Элемент
count(*)будет1даже если есть нулевые результаты в интервале гистограммы. Запрос должен быть изменен, чтобы использовать условныйsum:SELECT b.*, SUM(a.value IS NOT NULL) AS total FROM bins b LEFT JOIN a ON a.value BETWEEN b.min_value AND b.max_value GROUP BY b.min_value;
select "30-34" as TotalRange,count(total) as Count from table_name where total between 30 and 34 union ( select "35-39" as TotalRange,count(total) as Count from table_name where total between 35 and 39) union ( select "40-44" as TotalRange,count(total) as Count from table_name where total between 40 and 44) union ( select "45-49" as TotalRange,count(total) as Count from table_name where total between 45 and 49) etc ....пока не слишком много интервалов, это довольно хорошее решение.
Я сделал процедуру, которая может быть использована для автоматического создания временной таблицы для бункеров в соответствии с указанным числом или размером, для последующего использования с решением Ofri Raviv.
CREATE PROCEDURE makebins(numbins INT, binsize FLOAT) # binsize may be NULL for auto-size BEGIN SELECT FLOOR(MIN(colval)) INTO @binmin FROM yourtable; SELECT CEIL(MAX(colval)) INTO @binmax FROM yourtable; IF binsize IS NULL THEN SET binsize = CEIL((@binmax-@binmin)/numbins); # CEIL here may prevent the potential creation a very small extra bin due to rounding errors, but no good where floats are needed. END IF; SET @currlim = @binmin; WHILE @currlim + binsize < @binmax DO INSERT INTO bins VALUES (@currlim, @currlim+binsize); SET @currlim = @currlim + binsize; END WHILE; INSERT INTO bins VALUES (@currlim, @maxbin); END; DROP TABLE IF EXISTS bins; # be careful if you have a bins table of your own. CREATE TEMPORARY TABLE bins ( minval INT, maxval INT, # or FLOAT, if needed KEY (minval), KEY (maxval) );# keys could perhaps help if using a lot of bins; normally negligible CALL makebins(20, NULL); # Using 20 bins of automatic size here. SELECT bins.*, count(*) AS total FROM bins LEFT JOIN yourtable ON yourtable.value BETWEEN bins.minval AND bins.maxval GROUP BY bins.minvalэто создаст количество гистограмм только для заполненных ячеек. Дэвид Уэст должен быть прав в своей коррекции, но по какой - то причине незаселенные бункеры не появляются в результате для меня (несмотря на использование левого соединения-я не понимаю, почему).
Это должно сработать. Не так элегантно, но все же:
select count(mycol - (mycol mod 10)) as freq, mycol - (mycol mod 10) as label from mytable group by mycol - (mycol mod 10) order by mycol - (mycol mod 10) ASCчерез Майк DelGaudio
select case when total >= 30 and total <= 40 THEN "30-40" else when total >= 40 and total <= 50 then "40-50" else "50-60" END as Total , count(total) group by Total
в дополнение к большому ответу https://stackoverflow.com/a/10363145/916682, Вы можете использовать инструмент диаграммы phpmyadmin для хорошего результата:
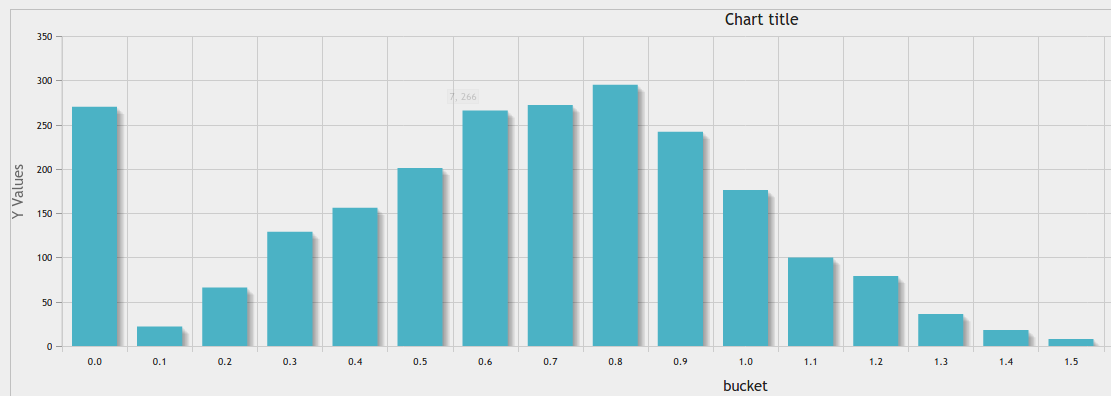
равная ширина биннинга в заданное количество бункеров:
WITH bins AS( SELECT min(col) AS min_value , ((max(col)-min(col)) / 10.0) + 0.0000001 AS bin_width FROM cars ) SELECT tab.*, floor((col-bins.min_value) / bins.bin_width ) AS bin FROM tab, bins;обратите внимание, что 0.0000001 есть, чтобы убедиться, что записи со значением, равным max(col) не делают его собственный бин просто сам по себе. Кроме того, аддитивная константа существует, чтобы убедиться, что запрос не терпит неудачу при делении на ноль, когда все значения в столбце идентичны.
также обратите внимание, что количество ячеек (10 в Примере) должно быть записано с десятичной меткой, чтобы избежать целочисленного деления (нескорректированная bin_width может быть десятичной).
Comments