Учитывая простое число N, вычислите следующее простое число?
коллега только что сказал мне, что коллекция словарей C# изменяется по простым числам по тайным причинам, связанным с хешированием. И мой непосредственный вопрос был: "как он узнает, что такое следующий Прайм? они рассказывают гигантский стол или вычисляют на лету? это страшная недетерминированная среда выполнения на вставке, вызывающая изменение размера"
Итак, мой вопрос, учитывая N, которое является простым числом, каков наиболее эффективный способ вычисления следующего простого числа?
9 ответов:
The пробелы между последовательными простыми числами, Как известно, довольно мал, с первым разрывом более 100 происходит для простого числа 370261. Это означает, что даже простая грубая сила будет достаточно быстрой в большинстве случаев, принимая O(ln(p)*sqrt(p)) в среднем.
для p=10,000 это o (921) операций. Имея в виду, что мы будем выполнять это один раз каждую вставку O(ln(p)) (грубо говоря), это хорошо укладывается в ограничения большинства проблем, берущих на себя порядка миллисекунды на самом современном оборудовании.
около года назад я работал в этой области для libc++ при осуществлении неупорядоченный (хэш) контейнеры для C++11. Я думал, что поделюсь мой опыт здесь. Этот опыт поддерживает marcog принял ответ для a разумный определение "грубой силы".
это означает, что даже простой перебор будет достаточно быстро в большинстве обстоятельства, принимая O(ln(p)*sqrt (p)) на средний.
я разработал несколько реализаций
size_t next_prime(size_t n)где спецификация для этой функции:возвращает: наименьшее простое число, которое больше или равно
n.каждая реализация
next_primeсопровождается вспомогательной функциейis_prime.is_primeследует рассматривать как частную деталь реализации; не предназначен для вызова непосредственно клиентом. Каждая из этих реализаций был конечно проверен на корректность, но тоже протестировано с помощью следующего теста производительности:int main() { typedef std::chrono::high_resolution_clock Clock; typedef std::chrono::duration<double, std::milli> ms; Clock::time_point t0 = Clock::now(); std::size_t n = 100000000; std::size_t e = 100000; for (std::size_t i = 0; i < e; ++i) n = next_prime(n+1); Clock::time_point t1 = Clock::now(); std::cout << e/ms(t1-t0).count() << " primes/millisecond\n"; return n; }я должен подчеркнуть, что это тест производительности, и не отражает типичный использование, которое было бы больше похоже:
// Overflow checking not shown for clarity purposes n = next_prime(2*n + 1);все тесты производительности были составлены с:
clang++ -stdlib=libc++ -O3 main.cppреализация 1
есть семь реализаций. Цель для показа первого реализация должна продемонстрировать, что если вы не можете остановить тестирование кандидата премьер -
xдля факторовsqrt(x)тогда вы не смогли даже добиться реализация, которая может быть классифицирована как грубая сила. Эта реализация является зверски медленно.bool is_prime(std::size_t x) { if (x < 2) return false; for (std::size_t i = 2; i < x; ++i) { if (x % i == 0) return false; } return true; } std::size_t next_prime(std::size_t x) { for (; !is_prime(x); ++x) ; return x; }для этой реализации только я должен был установить
eк 100 вместо 100000, как раз к получить разумное время работы:0.0015282 primes/millisecondреализация 2
эта реализация является самой медленной из грубую силу реализации и единственное отличие от реализации 1 заключается в том, что она прекращает тестирование на простоту когда коэффициент превышает
sqrt(x).bool is_prime(std::size_t x) { if (x < 2) return false; for (std::size_t i = 2; true; ++i) { std::size_t q = x / i; if (q < i) return true; if (x % i == 0) return false; } return true; } std::size_t next_prime(std::size_t x) { for (; !is_prime(x); ++x) ; return x; }обратите внимание, что
sqrt(x)непосредственно не вычисляется, а определяетсяq < i. Этот ускоряет вещи в тысячи раз:5.98576 primes/millisecondи предсказание проверяет marcog это:
... это хорошо в пределах ограничений большинство проблем при принятии заказа из миллисекунда на самом современном оборудовании.
реализация 3
можно почти удвоить скорость (по крайней мере, на оборудовании, которое я использую) избегая использования
%оператор:bool is_prime(std::size_t x) { if (x < 2) return false; for (std::size_t i = 2; true; ++i) { std::size_t q = x / i; if (q < i) return true; if (x == q * i) return false; } return true; } std::size_t next_prime(std::size_t x) { for (; !is_prime(x); ++x) ; return x; } 11.0512 primes/millisecondреализация 4
до сих пор я даже не использовал общеизвестное, что 2 является единственным четным простым числом. Эта реализация включает в себя эти знания, почти удвоив скорость и снова:
bool is_prime(std::size_t x) { for (std::size_t i = 3; true; i += 2) { std::size_t q = x / i; if (q < i) return true; if (x == q * i) return false; } return true; } std::size_t next_prime(std::size_t x) { if (x <= 2) return 2; if (!(x & 1)) ++x; for (; !is_prime(x); x += 2) ; return x; } 21.9846 primes/millisecondреализация 4, вероятно, то, что большинство людей имеют в виду, когда они думают "грубая сила."
реализация 5
используя следующую формулу, вы можете легко выбрать все числа, которые являются не делится ни на 2, ни на 3:
6 * k + {1, 5}где k >= 1. Следующая реализация использует эту формулу, но реализована с милой исключающее прием:
bool is_prime(std::size_t x) { std::size_t o = 4; for (std::size_t i = 5; true; i += o) { std::size_t q = x / i; if (q < i) return true; if (x == q * i) return false; o ^= 6; } return true; } std::size_t next_prime(std::size_t x) { switch (x) { case 0: case 1: case 2: return 2; case 3: return 3; case 4: case 5: return 5; } std::size_t k = x / 6; std::size_t i = x - 6 * k; std::size_t o = i < 2 ? 1 : 5; x = 6 * k + o; for (i = (3 + o) / 2; !is_prime(x); x += i) i ^= 6; return x; }это фактически означает, что алгоритм должен проверить только 1/3 целые числа для простоты вместо 1/2 чисел и теста производительности показывает ожидаемую скорость до почти 50%:
32.6167 primes/millisecondреализация 6
эта реализация является логическим расширением реализации 5: она использует следующая формула для вычисления всех чисел, которые не делятся на 2, 3 и 5:
30 * k + {1, 7, 11, 13, 17, 19, 23, 29}он также разворачивает внутренний цикл в is_prime и создает список "малых простые числа", что полезно для работы с числами менее 30.
static const std::size_t small_primes[] = { 2, 3, 5, 7, 11, 13, 17, 19, 23, 29 }; static const std::size_t indices[] = { 1, 7, 11, 13, 17, 19, 23, 29 }; bool is_prime(std::size_t x) { const size_t N = sizeof(small_primes) / sizeof(small_primes[0]); for (std::size_t i = 3; i < N; ++i) { const std::size_t p = small_primes[i]; const std::size_t q = x / p; if (q < p) return true; if (x == q * p) return false; } for (std::size_t i = 31; true;) { std::size_t q = x / i; if (q < i) return true; if (x == q * i) return false; i += 6; q = x / i; if (q < i) return true; if (x == q * i) return false; i += 4; q = x / i; if (q < i) return true; if (x == q * i) return false; i += 2; q = x / i; if (q < i) return true; if (x == q * i) return false; i += 4; q = x / i; if (q < i) return true; if (x == q * i) return false; i += 2; q = x / i; if (q < i) return true; if (x == q * i) return false; i += 4; q = x / i; if (q < i) return true; if (x == q * i) return false; i += 6; q = x / i; if (q < i) return true; if (x == q * i) return false; i += 2; } return true; } std::size_t next_prime(std::size_t n) { const size_t L = 30; const size_t N = sizeof(small_primes) / sizeof(small_primes[0]); // If n is small enough, search in small_primes if (n <= small_primes[N-1]) return *std::lower_bound(small_primes, small_primes + N, n); // Else n > largest small_primes // Start searching list of potential primes: L * k0 + indices[in] const size_t M = sizeof(indices) / sizeof(indices[0]); // Select first potential prime >= n // Known a-priori n >= L size_t k0 = n / L; size_t in = std::lower_bound(indices, indices + M, n - k0 * L) - indices; n = L * k0 + indices[in]; while (!is_prime(n)) { if (++in == M) { ++k0; in = 0; } n = L * k0 + indices[in]; } return n; }это, возможно, выходит за рамки "грубой силы" и хорошо для повышения скорость еще 27.5% до:
41.6026 primes/millisecondреализация 7
практически сыграть вышеуказанную игру для еще одной итерации, начиная а формула для чисел не делится на 2, 3, 5 и 7:
210 * k + {1, 11, ...},исходный код здесь не показан, но очень аналогично реализации 6. Это реализация, которую я решил фактически использовать для неупорядоченных контейнеров из libc++, и этот исходный код является открытым исходным кодом (находится по ссылке).
эта последняя итерация хороша для еще 14,6% повышения скорости до:
47.685 primes/millisecondиспользование этого алгоритма гарантирует, что клиенты libc++хеш-таблицы можно выбрать любой премьер, который они решают, наиболее выгоден для их ситуации и производительности для этого применение вполне приемлемо.
на всякий случай, если кому-то интересно:
с помощью reflector я определил, что .Net использует статический класс, который содержит жестко закодированный список из ~72 простых чисел в диапазоне до 7199369, который сканирует на наименьшее простое число, которое по крайней мере в два раза превышает текущий размер, а для размеров больше, чем он вычисляет следующее простое число путем пробного деления всех нечетных чисел до sqrt потенциального числа. Этот класс является неизменяемым и потокобезопасным (т. е. большие простые числа не сохраняются в будущем использовать.)
хороший трюк заключается в использовании частичного сита. Например, какое следующее простое число следует за числом N = 2534536543556?
Проверьте модуль N относительно списка малых простых чисел. Таким образом...
mod(2534536543556,[3 5 7 11 13 17 19 23 29 31 37]) ans = 2 1 3 6 4 1 3 4 22 16 25мы знаем, что следующее простое число после N должно быть нечетным числом, и мы можем немедленно отбросить все нечетные кратные этого списка малых простых чисел. Эти модули позволяют нам отсеять кратные из этих малых простых чисел. Мы должны были использовать маленькие простые числа до 200, мы можем использовать эту схему, чтобы сразу отбросить большинство потенциальных простых чисел больше N, за исключением небольшого списка.
более явно, если мы ищем простое число за пределами 2534536543556, оно не может быть кратным 2, поэтому нам нужно рассматривать только нечетные числа за пределами этого значения. Вышеуказанные модули показывают, что 2534536543556 вполне конгруэнтна 2 мод 3, поэтому 2534536543556+1 совпадает с 0 мод 3, как должно быть 2534536543556+7, 2534536543556+13 и т. д. Эффектно, мы можем фильтровать вне многие числа без какой-либо необходимости проверять их на первичность и без каких-либо пробных делений.
аналогично тому, что
mod(2534536543556,7) = 3говорит нам, что 2534536543556+4 соответствует 0 mod 7. Конечно, это число четное, поэтому мы можем его игнорировать. Но 2534536543556+11-это нечетное число, которое делится на 7, как и 2534536543556+25 и т. д. Опять же, мы можем исключить эти числа как явно составные (потому что они делятся на 7) и поэтому не простые.
используя только небольшой список простых чисел до 37, мы можем исключить большинство чисел, которые непосредственно следуют за нашей отправной точкой 2534536543556, только за исключением нескольких:
{2534536543573 , 2534536543579 , 2534536543597}из этих чисел, они простые?
2534536543573 = 1430239 * 1772107 2534536543579 = 99833 * 25387763Я приложил усилия, чтобы обеспечить простые факторизации первых двух чисел в списке. Смотрите, что они составные, но основные факторы велики. Конечно, это имеет смысл, так как мы уже убедились, что ни один номер, который остается, не может иметь малые простые множители. Третий в нашем коротком списке (2534536543597) на самом деле является самым первым простым числом за пределами N. схема просеивания, которую я описал, будет иметь тенденцию приводить к числам, которые являются либо простыми, либо состоят из обычно больших простых факторов. Поэтому нам нужно было фактически применить явный тест на примитивность только к нескольким числам, прежде чем найти следующее простое число.
аналогичная схема быстро дает следующее простое число, превышающее N = 1000000000000000000000000000, как 1000000000000000000000000103.
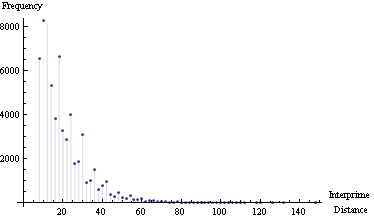
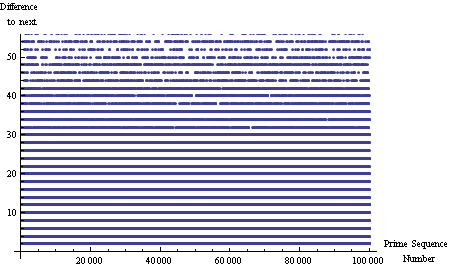
всего несколько экспериментов с расстоянием между простыми числами.
это дополнение для визуализации других ответов.
Я получил простые числа от 100.000-го (=1,299,709) до 200.000-го (=2,750,159)
иные данные:
Maximum interprime distance = 148 Mean interprime distance = 15помощью interprime расстояние частотного участка:
помощью interprime расстояние против простого числа
просто чтобы увидеть, что это"случайный". ...
нет функции f (n) для вычисления следующего простого числа. Вместо этого число должно быть проверено на первичность.
также очень полезно, находя N-е простое число, уже знать все простые числа от 1-го до (n-1) - го, потому что это единственные числа, которые нужно проверить как факторы.
в результате этих причин, я не удивлюсь, если есть расчитанный набор больших простых чисел. Это действительно не имеет смысла для меня если некоторые простые числа необходимо пересчитывать повторно.
Как уже отмечали другие, средство нахождения следующего простого числа с учетом текущего простого числа еще не найдено. Поэтому большинство алгоритмов больше ориентированы на использование быстрых средств проверки делением так как вы должны проверить n / 2 чисел между вашим известным простым и следующим.
в зависимости от приложения, вы также можете уйти с просто жесткого кодирования таблице, как отметил Пол Уилер.
для чистой новизны, всегда есть такой подход:
#!/usr/bin/perl for $p ( 2 .. 200 ) { next if (1x$p) =~ /^(11+)+$/; for ($n=1x(1+$p); $n =~ /^(11+)+$/; $n.=1) { } printf "next prime after %d is %d\n", $p, length($n); }что, конечно, производит
next prime after 2 is 3 next prime after 3 is 5 next prime after 5 is 7 next prime after 7 is 11 next prime after 11 is 13 next prime after 13 is 17 next prime after 17 is 19 next prime after 19 is 23 next prime after 23 is 29 next prime after 29 is 31 next prime after 31 is 37 next prime after 37 is 41 next prime after 41 is 43 next prime after 43 is 47 next prime after 47 is 53 next prime after 53 is 59 next prime after 59 is 61 next prime after 61 is 67 next prime after 67 is 71 next prime after 71 is 73 next prime after 73 is 79 next prime after 79 is 83 next prime after 83 is 89 next prime after 89 is 97 next prime after 97 is 101 next prime after 101 is 103 next prime after 103 is 107 next prime after 107 is 109 next prime after 109 is 113 next prime after 113 is 127 next prime after 127 is 131 next prime after 131 is 137 next prime after 137 is 139 next prime after 139 is 149 next prime after 149 is 151 next prime after 151 is 157 next prime after 157 is 163 next prime after 163 is 167 next prime after 167 is 173 next prime after 173 is 179 next prime after 179 is 181 next prime after 181 is 191 next prime after 191 is 193 next prime after 193 is 197 next prime after 197 is 199 next prime after 199 is 211все развлечения и игры в сторону, хорошо известно, что оптимальный размер хэш-таблицы строго доказуемо простое число вида
4N−1. Поэтому просто найти следующее простое число недостаточно. Вы должны сделать и другую проверку.
насколько я помню, он использует простое число рядом с двойной нынешних размеров. Он не вычисляет это простое число - там таблица с предварительно загруженными числами до некоторого большого значения (не совсем, что-то около 10 000 000). Когда это число достигнуто, он использует некоторый наивный алгоритм для получения следующего числа (например, curNum=curNum+1) и проверяет его с помощью некоторых, если эти методы:http://en.wikipedia.org/wiki/Prime_number#Verifying_primality
Comments