20 ответов:
нет никакого способа, Если вы
перечислите их все в партиях по 1000 (которые могут быть медленными и сосать пропускную способность-amazon, похоже, никогда не сжимает ответы XML), или
войдите в свою учетную запись на S3 и перейдите к использованию учетной записи. Кажется, отдел биллинга точно знает, сколько объектов вы сохранили!
просто загрузка списка всех ваших объектов на самом деле займет некоторое время и будет стоить некоторых денег, если вы храните 50 миллионов объектов.
см. Также эта тема о StorageObjectCount - который находится в данных об использовании.
API S3, чтобы получить хотя бы основы, даже если это было несколько часов назад, было бы здорово.
использование AWS CLI
aws s3 ls s3://mybucket/ --recursive | wc -lили
aws cloudwatch get-metric-statistics \ --namespace AWS/S3 --metric-name NumberOfObjects \ --dimensions Name=BucketName,Value=BUCKETNAME \ Name=StorageType,Value=AllStorageTypes \ --start-time 2016-11-05T00:00 --end-time 2016-11-05T00:10 \ --period 60 --statistic AverageПримечание: выше cloudwatch команда, кажется, работает в течение некоторого времени не для других. Обсуждается здесь:https://forums.aws.amazon.com/thread.jspa?threadID=217050
использование веб-консоли AWS
вы можете посмотреть метрическая секция cloudwatch чтобы получить приблизительное количество сохраненных объектов.
у меня есть около 50 миллионов продуктов, и это заняло более часа для подсчета с помощью
aws s3 ls
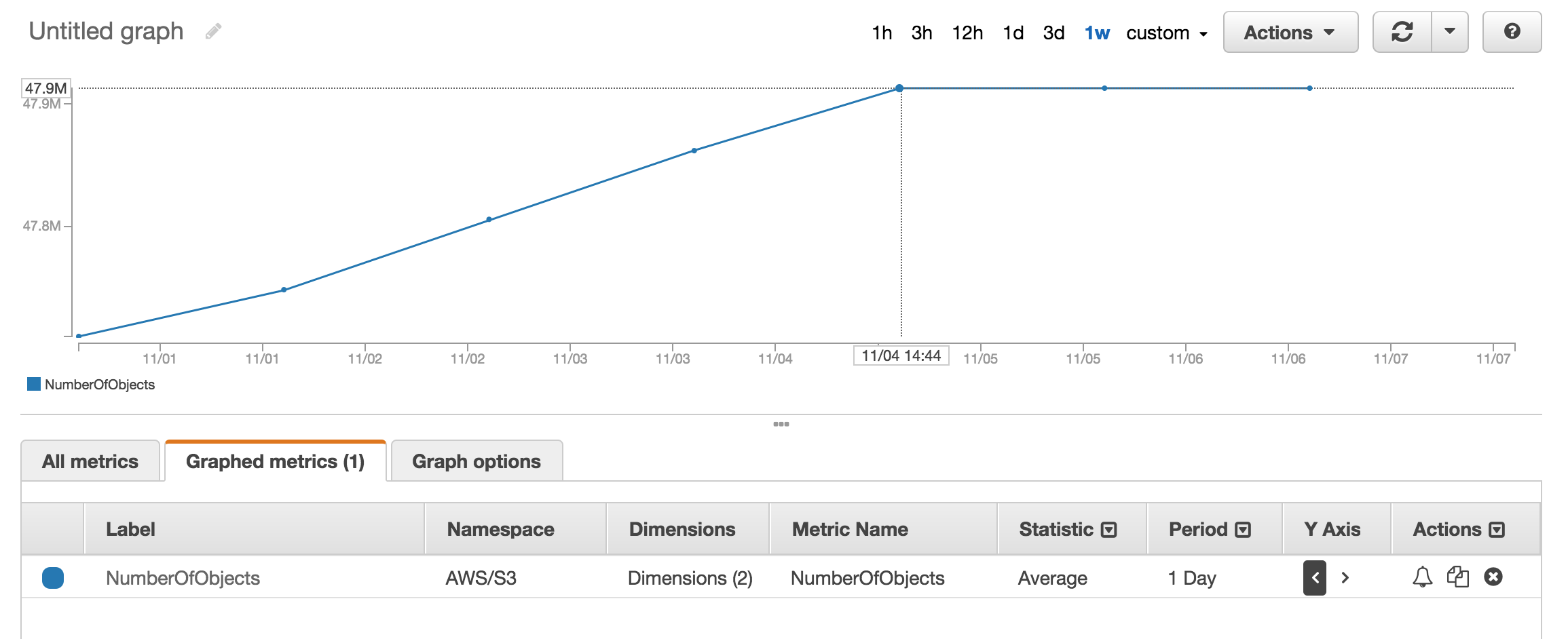
есть
--summarizeпереключение на отображение сводная информация по ведру (т. е. количество объектов, общий размер).вот правильный ответ с помощью AWS cli:
aws s3 ls s3://bucketName/path/ --recursive --summarize | grep "Total Objects:" Total Objects: 194273посмотреть документация
Если вы используете s3cmd инструмент командной строки, вы можете получить рекурсивный список конкретного ведра, выводя его в текстовый файл.
s3cmd ls -r s3://logs.mybucket/subfolder/ > listing.txtзатем в linux вы можете запустить wc-l в файле для подсчета строк (1 строка на объект).
wc -l listing.txt
теперь есть простое решение с API S3 (доступно в AWS cli):
aws s3api list-objects --bucket BUCKETNAME --output json --query "[length(Contents[])]"или для определенной папки:
aws s3api list-objects --bucket BUCKETNAME --prefix "folder/subfolder/" --output json --query "[length(Contents[])]"
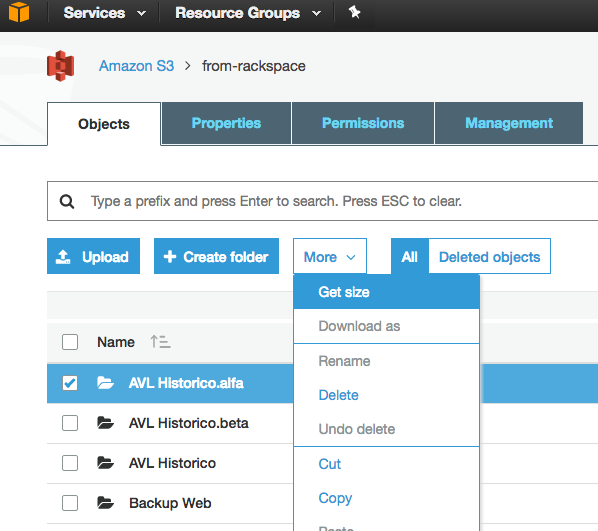
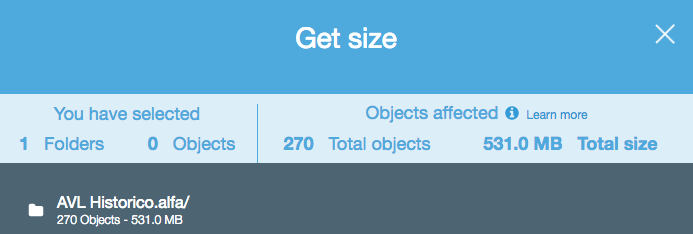
хотя это старый вопрос, и обратная связь была предоставлена в 2015 году, сейчас это намного проще, так как веб-консоль S3 включила опцию "получить размер":
, который предусматривает следующее:
вы можете использовать метрики AWS cloudwatch для s3, чтобы увидеть точное количество для каждого ведра.

перейдите в раздел AWS Billing, затем отчеты, затем отчеты об использовании AWS. Выберите Amazon Simple Storage Service, затем Operation StandardStorage. Затем вы можете загрузить CSV-файл, который включает тип Usagetype StorageObjectCount, в котором указано количество элементов для каждого ведра.
ни один из API не даст вам подсчета, потому что на самом деле нет никакого конкретного API Amazon для этого. Вы должны просто запустить список-содержание и подсчитать количество результатов, которые возвращаются.
api вернет список с шагом 1000. Проверьте свойство IsTruncated, чтобы узнать, есть ли еще больше. Если есть, вам нужно сделать еще один вызов и передать Последний ключ, который вы получили в качестве свойства маркера при следующем вызове. Затем вы продолжите цикл, как это, пока IsTruncated не станет ложным.
смотрите этот документ Amazon для получения дополнительной информации:Итерация По Многостраничным Результатам
старая нить, но все еще актуальна, поскольку я искал ответ, пока я просто не понял это. Я хотел подсчет файлов с помощью инструмента на основе графического интерфейса (т. е. без кода). Я уже использую инструмент под названием 3Hub для переноса перетаскивания в и из S3. Я хотел знать, сколько файлов у меня было в определенном ведре (Я не думаю, что биллинг разбивает его на ведра).
So, using 3Hub, - list the contents of the bucket (looks basically like a finder or explorer window) - go to the bottom of the list, click 'show all' - select all (ctrl+a) - choose copy URLs from right-click menu - paste the list into a text file (I use TextWrangler for Mac) - look at the line countу меня было 20521 файлов в ведре и сделал количество файлов меньше, чем a минута.
я использовал скрипт python из scalablelogic.com (Добавление в журнал подсчета). Работал отлично.
#!/usr/local/bin/python import sys from boto.s3.connection import S3Connection s3bucket = S3Connection().get_bucket(sys.argv[1]) size = 0 totalCount = 0 for key in s3bucket.list(): totalCount += 1 size += key.size print 'total size:' print "%.3f GB" % (size*1.0/1024/1024/1024) print 'total count:' print totalCount
вы можете скачать и установить браузер s3 из http://s3browser.com/. при выборе корзины в правом Центральном углу вы можете увидеть количество файлов в корзине. Но он показывает неправильно в текущей версии.
Gubs
самый простой способ-использовать консоль разработчика, например, если вы находитесь в chrome, выберите инструменты разработчика, и вы можете увидеть следующее, Вы можете найти и посчитать или сделать какое-то совпадение, например 280-279 + 1 = 2
...
из командной строки в AWS CLI используйте
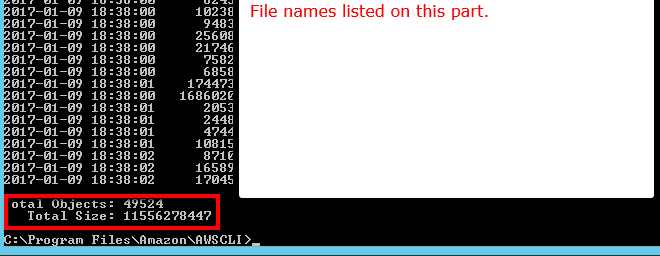
ls plus --summarize. Он даст вам список всех ваших элементов и общее количество документов в определенном ведре. Я не пробовал это с ведрами, содержащими суб-ведра:aws s3 ls "s3://MyBucket" --summarizeэто займет немного времени (потребовалось перечислить Мои документы 16+K около 4 минут), но это быстрее, чем подсчет 1K за раз.
Как насчет S3 storage class analytics - вы получаете API, а также на консоли -https://docs.aws.amazon.com/AmazonS3/latest/dev/analytics-storage-class.html
Я нашел S3 browser tool очень пользователь, он предоставляет файлы и папки и общее количество, а также размер для любой папки рекурсивно
ссылка для скачивания:https://s3browser.com/download.aspx
вы можете потенциально использовать Amazon S3 inventory, который даст вам список объектов в csv-файле
Comments