Как я могу использовать numpy.коррелировать, чтобы сделать автокорреляцию?
Мне нужно сделать автокорреляцию набора чисел, который, как я понимаю, это просто корреляция набора с самим собой.
Я пробовал использовать корреляционную функцию numpy, но я не верю в результат, так как он почти всегда дает вектор, где первое число не самый большой, как это должно быть.
Итак, этот вопрос действительно два вопроса:
- что такое numpy.коррелировать делать?
- как я могу используйте его (или что-то еще), чтобы сделать автокорреляцию?
11 ответов:
чтобы ответить на ваш первый вопрос,
numpy.correlate(a, v, mode)выполняет сверткуaС обратной стороныvи дает результаты, обрезанные указанным режимом. Элемент определение свертки, C (t)=∑ - ∞ aяvt+i где - ∞
- "полный" режим возвращает результаты для каждого
tкогда какaиvесть некоторые совпадения.- режим"same" возвращает результат с той же длиной, что и самый короткий вектор (
aилиv).- "действует" режим возвращает результаты только тогда, когда
aиvполностью перекрывают друг друга. Элемент документация наnumpy.convolveдает более подробную информацию о режимах.для ваш второй вопрос, я думаю
numpy.correlateи давая вам автокорреляцию, это просто дает вам немного больше, а также. Автокорреляция используется для определения того, насколько похож сигнал или функция на себя при определенной разнице во времени. При разнице во времени 0 автокорреляция должна быть самой высокой, потому что сигнал идентичен самому себе, поэтому вы ожидали, что первый элемент в массиве результатов автокорреляции будет самым большим. Однако корреляции нет начиная со времени 0. Он начинается с отрицательной разницы во времени, закрывается до 0, а затем становится положительным. То есть, вы ожидали:автокорреляция (a) = ∑ - ∞ aяvt+i где 0
но то, что вы получили было:
автокорреляция (a) = ∑ - ∞ aяvt+i где - ∞
что вам нужно сделать, это возьмите последнюю половину вашего результата корреляции и автокорреляции, которые вы ищете. Простая функция python для этого будет:
def autocorr(x): result = numpy.correlate(x, x, mode='full') return result[result.size/2:]вам, конечно, понадобится проверка ошибок, чтобы убедиться, что
xна самом деле 1-d массив. Кроме того, это объяснение, вероятно, не является самым математически строгим. Я бросал вокруг бесконечностей, потому что определение свертки использует их, но это не обязательно относится к автокорреляции. Итак, теоретическая часть этого объяснения может быть немного шаткой, но, надеюсь, практические результаты полезны. этистраницы на автокорреляции довольно полезны, и может дать вам гораздо лучший теоретический фон, если вы не возражаете пробираться через нотации и тяжелые концепции.
автокорреляция поставляется в двух версиях: статистическая и свертка. Они оба делают то же самое, за исключением маленькой детали: бывший нормированы на интервал [-1,1]. Вот пример того, как вы делаете статистический:
def acf(x, length=20): return numpy.array([1]+[numpy.corrcoef(x[:-i], x[i:]) \ for i in range(1, length)])
поскольку я только что столкнулся с той же проблемой, я хотел бы поделиться с вами несколькими строками кода. На самом деле сейчас есть несколько довольно похожих сообщений об автокорреляции в stackoverflow. Если вы определяете автокорреляцию как
a(x, L) = sum(k=0,N-L-1)((xk-xbar)*(x(k+L)-xbar))/sum(k=0,N-1)((xk-xbar)**2)[это определение, данное в функции A_CORRELATE IDL, и оно согласуется с тем, что я вижу в ответе 2 вопроса #12269834], то следующие, кажется, дают правильные результаты:import numpy as np import matplotlib.pyplot as plt # generate some data x = np.arange(0.,6.12,0.01) y = np.sin(x) # y = np.random.uniform(size=300) yunbiased = y-np.mean(y) ynorm = np.sum(yunbiased**2) acor = np.correlate(yunbiased, yunbiased, "same")/ynorm # use only second half acor = acor[len(acor)/2:] plt.plot(acor) plt.show()как вы видите, я проверил это с помощью кривая sin и равномерное случайное распределение, и оба результата выглядят так, как я ожидал бы их. Обратите внимание, что я использовал
mode="same"вместоmode="full"как и остальные.
Ваш вопрос 1 уже широко обсуждался в нескольких отличных ответах здесь.
Я подумал поделиться с вами несколькими строками кода, которые позволяют вычислить автокорреляцию сигнала, основанного только на математических свойствах автокорреляции. То есть автокорреляция может быть вычислена следующим образом:
вычесть среднее из сигнала и получить несмещенный сигнал
вычислить Преобразование Фурье несмещенного сигнала
вычислите спектральную плотность мощности сигнала, взяв квадратную норму каждого значения преобразования Фурье несмещенного сигнала
вычислить обратное преобразование Фурье от спектральной плотности мощности
нормализуем обратное преобразование Фурье спектральной плотности мощности на сумму квадратов несмещенного сигнала и берем только половину полученного вектор
код для этого следующий:
def autocorrelation (x) : """ Compute the autocorrelation of the signal, based on the properties of the power spectral density of the signal. """ xp = x-np.mean(x) f = np.fft.fft(xp) p = np.array([np.real(v)**2+np.imag(v)**2 for v in f]) pi = np.fft.ifft(p) return np.real(pi)[:x.size/2]/np.sum(xp**2)
Я думаю, что есть 2 вещи, которые запутывают эту тему:
- statistical v. s. определение обработки сигналов: как указывали другие, в статистике мы нормализуем автокорреляцию в [-1,1].
- частичное V. s. неполное среднее / дисперсия: когда временные ряды сдвигаются с лагом>0, их размер перекрытия всегда будет
Я создал 5 функций, которые вычисляют автокорреляционные массива 1д, с частичным В. С. номера-частичные различия. Некоторые используют формулу из статистики, некоторые используют коррелят в смысле обработки сигнала, что также может быть сделано с помощью БПФ. Но все результаты являются автокорреляциями в статистика определение, поэтому они иллюстрируют, как они есть связаны друг с другом. Код ниже:
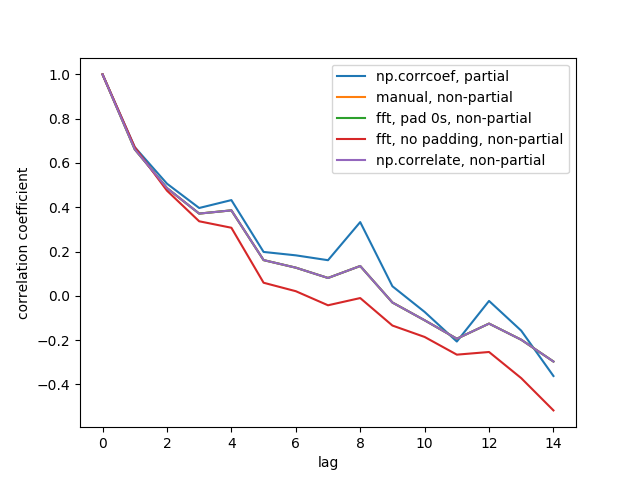
import numpy import matplotlib.pyplot as plt def autocorr1(x,lags): '''numpy.corrcoef, partial''' corr=[1. if l==0 else numpy.corrcoef(x[l:],x[:-l])[0][1] for l in lags] return numpy.array(corr) def autocorr2(x,lags): '''manualy compute, non partial''' mean=numpy.mean(x) var=numpy.var(x) xp=x-mean corr=[1. if l==0 else numpy.sum(xp[l:]*xp[:-l])/len(x)/var for l in lags] return numpy.array(corr) def autocorr3(x,lags): '''fft, pad 0s, non partial''' n=len(x) # pad 0s to 2n-1 ext_size=2*n-1 # nearest power of 2 fsize=2**numpy.ceil(numpy.log2(ext_size)).astype('int') xp=x-numpy.mean(x) var=numpy.var(x) # do fft and ifft cf=numpy.fft.fft(xp,fsize) sf=cf.conjugate()*cf corr=numpy.fft.ifft(sf).real corr=corr/var/n return corr[:len(lags)] def autocorr4(x,lags): '''fft, don't pad 0s, non partial''' mean=x.mean() var=numpy.var(x) xp=x-mean cf=numpy.fft.fft(xp) sf=cf.conjugate()*cf corr=numpy.fft.ifft(sf).real/var/len(x) return corr[:len(lags)] def autocorr5(x,lags): '''numpy.correlate, non partial''' mean=x.mean() var=numpy.var(x) xp=x-mean corr=numpy.correlate(xp,xp,'full')[len(x)-1:]/var/len(x) return corr[:len(lags)] if __name__=='__main__': y=[28,28,26,19,16,24,26,24,24,29,29,27,31,26,38,23,13,14,28,19,19,\ 17,22,2,4,5,7,8,14,14,23] y=numpy.array(y).astype('float') lags=range(15) fig,ax=plt.subplots() for funcii, labelii in zip([autocorr1, autocorr2, autocorr3, autocorr4, autocorr5], ['np.corrcoef, partial', 'manual, non-partial', 'fft, pad 0s, non-partial', 'fft, no padding, non-partial', 'np.correlate, non-partial']): cii=funcii(y,lags) print(labelii) print(cii) ax.plot(lags,cii,label=labelii) ax.set_xlabel('lag') ax.set_ylabel('correlation coefficient') ax.legend() plt.show()вот выходная цифра:
мы не видим все 5 линий, потому что 3 из них перекрываются (на фиолетовом). Перекрытия - это все неполные автокорреляции. Это связано с тем, что вычисления из методов обработки сигналов (
np.correlate, FFT) не вычисляйте разные средние/std для каждого перекрытия.также обратите внимание, что
fft, no padding, non-partial(красная линия) результат разный, потому что это не pad timeseries с 0s, прежде чем делать БПФ, так что это круговой БПФ. Я не могу объяснить подробно почему, вот что я узнал из других источников.
Я использую Талиб.Корреляция для автокорреляции, как это, я подозреваю, что вы могли бы сделать то же самое с другими пакетами:
def autocorrelate(x, period): # x is a deep indicator array # period of sample and slices of comparison # oldest data (period of input array) may be nan; remove it x = x[-np.count_nonzero(~np.isnan(x)):] # subtract mean to normalize indicator x -= np.mean(x) # isolate the recent sample to be autocorrelated sample = x[-period:] # create slices of indicator data correls = [] for n in range((len(x)-1), period, -1): alpha = period + n slices = (x[-alpha:])[:period] # compare each slice to the recent sample correls.append(ta.CORREL(slices, sample, period)[-1]) # fill in zeros for sample overlap period of recent correlations for n in range(period,0,-1): correls.append(0) # oldest data (autocorrelation period) will be nan; remove it correls = np.array(correls[-np.count_nonzero(~np.isnan(correls)):]) return correls # CORRELATION OF BEST FIT # the highest value correlation max_value = np.max(correls) # index of the best correlation max_index = np.argmax(correls)
простое решение без панд:
import numpy as np def auto_corrcoef(x): return np.corrcoef(x[1:-1], x[2:])[0,1]
Я думаю, что реальный ответ на вопрос OP кратко содержится в этом отрывке из Numpy.соотнесите документацию:
mode : {'valid', 'same', 'full'}, optional Refer to the `convolve` docstring. Note that the default is `valid`, unlike `convolve`, which uses `full`.это означает, что при использовании без определения "mode" Numpy.функция correlate возвращает скаляр, когда задан один и тот же вектор для его двух входных аргументов (т. е. - при использовании для выполнения автокорреляции).
Я вычислительный биолог, и когда мне пришлось вычислять авто/кросс-корреляции между парами временных рядов стохастических процессов, я понял, что np.коррелят не делал работу, в которой я нуждался.
действительно, то, что кажется отсутствующим в np.коррелят-это усреднение по всем возможным парам точек времени на расстоянии \тау.
вот как я определил функцию, делающую то, что мне нужно:
def autocross(x, y): c = np.correlate(x, y, "same") v = [c[i]/( len(x)-abs( i - (len(x)/2) ) ) for i in range(len(c))] return vКажется для меня ни один из предыдущих ответов не охватывает этот случай автоматической/перекрестной корреляции: надеюсь, что этот ответ может быть полезен кому-то, кто работает со стохастическими процессами, такими как я.
используя преобразование Фурье и теорему свертки
сложность времени N * log (N)
def autocorr1(x): r2=np.fft.ifft(np.abs(np.fft.fft(x))**2).real return r2[:len(x)//2]вот нормализованная и беспристрастная версия, это также N * log (N)
def autocorr2(x): r2=np.fft.ifft(np.abs(np.fft.fft(x))**2).real c=(r2/x.shape-np.mean(x)**2)/np.std(x)**2 return c[:len(x)//2]метод, предоставленный А. Леви работает, но я протестировал его на своем ПК, его временная сложность кажется N*N
def autocorr(x): result = numpy.correlate(x, x, mode='full') return result[result.size/2:]
Comments