Как очистить застрявших / несвежих работников Resque?
Как вы можете видеть из прилагаемого изображения, у меня есть несколько рабочих, которые, похоже, застряли. Эти процессы не должны занимать больше нескольких секунд.
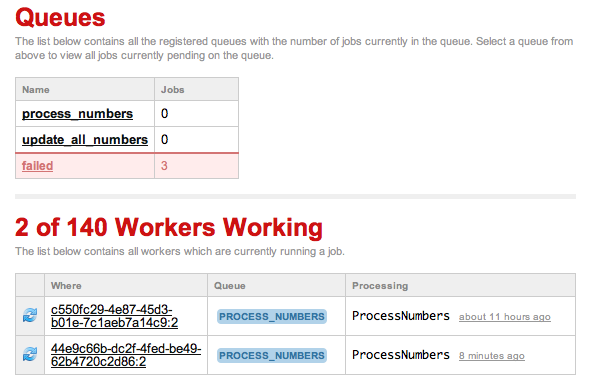
Я не уверен, почему они не четкие или как вручную удалить их.
Я на Heroku, используя Resque с Redis-To-Go и HireFire для автоматического масштабирования рабочих.
15 ответов:
ни одно из этих решений не работало для меня, я бы все равно увидел это в redis-web:
0 out of 10 Workers Workingнаконец, это сработало для меня, чтобы очистить все рабочие:
Resque.workers.each {|w| w.unregister_worker}
в консоли:
queue_name = "process_numbers" Resque.redis.del "queue:#{queue_name}"в противном случае вы можете попробовать подделать их, как делается, чтобы удалить их, с:
Resque::Worker.working.each {|w| w.done_working}EDIT
многие люди поддерживают этот ответ, и я чувствую, что важно, чтобы люди попробовали решение hagope, которое отменяет регистрацию работников из очереди, тогда как приведенный выше код удаляет очереди. Если вы счастливы подделать их, то круто.
у вас, вероятно, установлен resque gem, поэтому вы можете открыть консоль и получить текущие рабочие
Resque.workersон возвращает список работников
#=> [#<Worker infusion.local:40194-0:JAVA_DYNAMIC_QUEUES,index_migrator,converter,extractor>]выберите работника и
prune_dead_workers, например, первымResque.workers.first.prune_dead_workers
добавляя к ответу hagope, я хотел иметь возможность только отменить регистрацию рабочих, которые работали в течение определенного времени. Приведенный ниже код отменяет регистрацию только тех работников, которые работают более 300 секунд (5 минут).
Resque.workers.each {|w| w.unregister_worker if w.processing['run_at'] && Time.now - w.processing['run_at'].to_time > 300}У меня есть текущая коллекция связанных с Resque задач рейка, которые я также добавил Это:https://gist.github.com/ewherrmann/8809350
выполните эту команду везде, где вы запустили команду для запуска сервера
$ ps -e -o pid,command | grep [r]esqueвы должны увидеть нечто вроде этого:
92102 resque: Processing ProcessNumbers since 1253142769обратите внимание на PID (идентификатор процесса) в моем примере это 92102
затем вы можете выйти из процесса 1 из 2 способов.
изящно использовать
QUIT 92102принудительно использовать
TERM 92102* я не уверен синтаксис это либо
QUIT 92102илиQUIT -92102Дайте мне знать, если у вас возникли проблемы.
Я только что сделал:
% rails c production irb(main):001:0>Resque.workersполучил список работников.
irb(main):002:0>Resque.remove_worker(Resque.workers[n].id)... где n-нулевой индекс нежелательного работника.
У меня была аналогичная проблема, что Redis сохранил БД на диск, который включал недопустимые (не работающие) рабочие. Каждый раз, когда Redis/resque был запущен, они появлялись.
исправить это с помощью:
Resque::Worker.working.each {|w| w.done_working} Resque.redis.save # Save the DB to disk without ANY workersубедитесь, что вы перезапустили Redis и ваших работников Resque.
вот как вы можете очистить их от Redis по имени хоста. Это происходит со мной, когда я списываю сервер, и рабочие не выходят изящно.
Resque.workers.each { |w| w.unregister_worker if w.id.start_with?(hostname) }
Я столкнулся с этой проблемой и начал путь реализации многих предложений здесь. Однако я обнаружил, что основной причиной, которая создавала эту проблему, было то, что я был используя драгоценный камень redis-rb 3.3.0. Понижение рейтинга до redis-rb 3.2.2 не позволило этим работникам застрять в первую очередь.
начал работать над https://github.com/shaiguitar/resque_stuck_queue/ недавно. Это не решение о том, как исправить застрявших работников, но оно решает проблему зависания/застревания resque, поэтому я решил, что это может быть полезно для людей в этой теме. Из ридми:
" Если resque не запускает задания в течение определенного периода времени, он запустит предварительно определенный обработчик по вашему выбору. Вы можете использовать это, чтобы отправить по электронной почте, пейджер обязанность, добавить больше resque работников, перезапустить resque, отправить вам текст...все, что тебе подходит."
использовался в производстве и работает довольно хорошо для меня до сих пор.
Я застрял / устаревшие resque рабочие здесь тоже, или я должен сказать "работа", потому что работник на самом деле все еще там и работает нормально, это раздвоенный процесс, который застрял.
Я выбрал жестокое решение убийства раздвоенного процесса "обработка", так как более 5 минут, через скрипт bash, затем рабочий просто порождает следующий в очереди, и все продолжается
посмотрите на мой скрипт здесь:https://gist.github.com/jobwat/5712437
я очистил их от redis-cli напрямую. К счастью redistogo.com позволяет получить доступ из окружающей среды за пределами heroku. Получить идентификатор мертвого работника из списка. Мой был
55ba6f3b-9287-4f81-987a-4e8ae7f51210:2выполните эту команду непосредственно в redis.
del "resque:worker:55ba6f3b-9287-4f81-987a-4e8ae7f51210:2:*"вы можете контролировать redis db, чтобы увидеть, что он делает за кулисами.
redis xxx.redistogo.com> MONITOR OK 1380274567.540613 "MONITOR" 1380274568.345198 "incrby" "resque:stat:processed" "1" 1380274568.346898 "incrby" "resque:stat:processed:c65c8e2b-555a-4a57-aaa6-477b27d6452d:2:*" "1" 1380274568.346920 "del" "resque:worker:c65c8e2b-555a-4a57-aaa6-477b27d6452d:2:*" 1380274568.348803 "smembers" "resque:queues"последняя строка удаляет работника.
Если вы используете более новые версии Resque, вам нужно будет использовать следующую команду, поскольку внутренние API изменились...
Resque::WorkerRegistry.working.each {|work| Resque::WorkerRegistry.remove(work.id)}
это позволяет избежать проблемы, пока у вас есть версия resque новее 1.26.0:
resque: env QUEUE=foo TERM_CHILD=1 bundle exec rake resque:workимейте в виду, что это не позволяет завершить текущее задание.
вы также можете использовать следующую команду, чтобы остановить все
rescueработникsudo kill -9 `ps aux | grep resque | grep -v grep | cut -c 10-16`
Comments