Как получить индексы N максимальных значений в массиве NumPy?
NumPy предлагает способ получить индекс максимального значения массива через np.argmax.
Я хотел бы аналогичную вещь, но возвращая индексы N максимальных значений.
например, если у меня есть массив, [1, 3, 2, 4, 5],function(array, n=3) вернутся [4, 3, 1].
15 ответов:
самое простое что я смог придумать это:
In [1]: import numpy as np In [2]: arr = np.array([1, 3, 2, 4, 5]) In [3]: arr.argsort()[-3:][::-1] Out[3]: array([4, 3, 1])Это включает в себя полный вид массива. Интересно, если
numpyпредоставляет встроенный способ сделать частичные сортировки; до сих пор я не смог найти.Если это решение окажется слишком медленным (особенно для малых
n), возможно, стоит посмотреть на кодирование чего-то в на Cython.
новые версии NumPy (1.8 и выше) имеют функцию под названием
argpartitionдля этого. Чтобы получить индексы четырех крупнейших элементов, сделайте>>> a = np.array([9, 4, 4, 3, 3, 9, 0, 4, 6, 0]) >>> a array([9, 4, 4, 3, 3, 9, 0, 4, 6, 0]) >>> ind = np.argpartition(a, -4)[-4:] >>> ind array([1, 5, 8, 0]) >>> a[ind] array([4, 9, 6, 9])в отличие от
argsort, эта функция работает в линейном времени в худшем случае, но возвращаемые индексы не сортируются, как видно из результата оценкиa[ind]. Если вам это тоже нужно, отсортируйте их впоследствии:>>> ind[np.argsort(a[ind])] array([1, 8, 5, 0])чтобы получить вершину -k элементы в отсортированном порядке таким образом O (n + k log k) времени.
использование:
>>> import heapq >>> import numpy >>> a = numpy.array([1, 3, 2, 4, 5]) >>> heapq.nlargest(3, range(len(a)), a.take) [4, 3, 1]для обычных списков Python:
>>> a = [1, 3, 2, 4, 5] >>> heapq.nlargest(3, range(len(a)), a.__getitem__) [4, 3, 1]если вы используете Python 2, Используйте
xrangeвместоrange.источник: heapq - алгоритм очереди кучи
Если вы работаете с многомерным массивом, то вам нужно будет сгладить и распутать индексы:
def largest_indices(ary, n): """Returns the n largest indices from a numpy array.""" flat = ary.flatten() indices = np.argpartition(flat, -n)[-n:] indices = indices[np.argsort(-flat[indices])] return np.unravel_index(indices, ary.shape)например:
>>> xs = np.sin(np.arange(9)).reshape((3, 3)) >>> xs array([[ 0. , 0.84147098, 0.90929743], [ 0.14112001, -0.7568025 , -0.95892427], [-0.2794155 , 0.6569866 , 0.98935825]]) >>> largest_indices(xs, 3) (array([2, 0, 0]), array([2, 2, 1])) >>> xs[largest_indices(xs, 3)] array([ 0.98935825, 0.90929743, 0.84147098])
если вы не заботитесь о ордер из K-го по величине элементов вы можете использовать
argpartition, который должен работать лучше, чем полная сортировка черезargsort.K = 4 # We want the indices of the four largest values a = np.array([0, 8, 0, 4, 5, 8, 8, 0, 4, 2]) np.argpartition(a,-K)[-K:] array([4, 1, 5, 6])кредиты идут в этот вопрос.
я провел несколько тестов, и это выглядит как
argpartitionпревосходитargsortпо мере увеличения размера массива и значения K.
для многомерных массивов можно использовать
axisключевое слово для применения секционирования вдоль ожидаемой оси.# For a 2D array indices = np.argpartition(arr, -N, axis=1)[:, -N:]и для захвата предметов:
x = arr.shape[0] arr[np.repeat(np.arange(x), N), indices.ravel()].reshape(x, N)но обратите внимание, что это не вернет отсортированного результата. В этом случае вы можете использовать
np.argsort()вдоль намеченной оси:indices = np.argsort(arr, axis=1)[:, -N:] # Result x = arr.shape[0] arr[np.repeat(np.arange(x), N), indices.ravel()].reshape(x, N)вот пример:
In [42]: a = np.random.randint(0, 20, (10, 10)) In [44]: a Out[44]: array([[ 7, 11, 12, 0, 2, 3, 4, 10, 6, 10], [16, 16, 4, 3, 18, 5, 10, 4, 14, 9], [ 2, 9, 15, 12, 18, 3, 13, 11, 5, 10], [14, 0, 9, 11, 1, 4, 9, 19, 18, 12], [ 0, 10, 5, 15, 9, 18, 5, 2, 16, 19], [14, 19, 3, 11, 13, 11, 13, 11, 1, 14], [ 7, 15, 18, 6, 5, 13, 1, 7, 9, 19], [11, 17, 11, 16, 14, 3, 16, 1, 12, 19], [ 2, 4, 14, 8, 6, 9, 14, 9, 1, 5], [ 1, 10, 15, 0, 1, 9, 18, 2, 2, 12]]) In [45]: np.argpartition(a, np.argmin(a, axis=0))[:, 1:] # 1 is because the first item is the minimum one. Out[45]: array([[4, 5, 6, 8, 0, 7, 9, 1, 2], [2, 7, 5, 9, 6, 8, 1, 0, 4], [5, 8, 1, 9, 7, 3, 6, 2, 4], [4, 5, 2, 6, 3, 9, 0, 8, 7], [7, 2, 6, 4, 1, 3, 8, 5, 9], [2, 3, 5, 7, 6, 4, 0, 9, 1], [4, 3, 0, 7, 8, 5, 1, 2, 9], [5, 2, 0, 8, 4, 6, 3, 1, 9], [0, 1, 9, 4, 3, 7, 5, 2, 6], [0, 4, 7, 8, 5, 1, 9, 2, 6]]) In [46]: np.argpartition(a, np.argmin(a, axis=0))[:, -3:] Out[46]: array([[9, 1, 2], [1, 0, 4], [6, 2, 4], [0, 8, 7], [8, 5, 9], [0, 9, 1], [1, 2, 9], [3, 1, 9], [5, 2, 6], [9, 2, 6]]) In [89]: a[np.repeat(np.arange(x), 3), ind.ravel()].reshape(x, 3) Out[89]: array([[10, 11, 12], [16, 16, 18], [13, 15, 18], [14, 18, 19], [16, 18, 19], [14, 14, 19], [15, 18, 19], [16, 17, 19], [ 9, 14, 14], [12, 15, 18]])
Это будет быстрее, чем полная сортировка в зависимости от размера исходного массива и размер вашего выбора:
>>> A = np.random.randint(0,10,10) >>> A array([5, 1, 5, 5, 2, 3, 2, 4, 1, 0]) >>> B = np.zeros(3, int) >>> for i in xrange(3): ... idx = np.argmax(A) ... B[i]=idx; A[idx]=0 #something smaller than A.min() ... >>> B array([0, 2, 3])Это, конечно, включает в себя вмешательство в исходный массив. Который вы можете исправить (если это необходимо), сделав копию или заменив исходные значения. ...какой бы выгоднее для вашего случая.
bottleneckимеет функцию частичной сортировки, если затраты на сортировку всего массива только для получения N наибольших значений слишком велики.Я ничего не знаю об этом модуле; я просто погуглил
numpy partial sort.
использование:
from operator import itemgetter from heapq import nlargest result = nlargest(N, enumerate(your_list), itemgetter(1))теперь
resultсписок будет содержать N ОК (index,value), гдеvalueмаксимизируется.
использование:
def max_indices(arr, k): ''' Returns the indices of the k first largest elements of arr (in descending order in values) ''' assert k <= arr.size, 'k should be smaller or equal to the array size' arr_ = arr.astype(float) # make a copy of arr max_idxs = [] for _ in range(k): max_element = np.max(arr_) if np.isinf(max_element): break else: idx = np.where(arr_ == max_element) max_idxs.append(idx) arr_[idx] = -np.inf return max_idxsОн также работает с 2D массивов. Например,
In [0]: A = np.array([[ 0.51845014, 0.72528114], [ 0.88421561, 0.18798661], [ 0.89832036, 0.19448609], [ 0.89832036, 0.19448609]]) In [1]: max_indices(A, 8) Out[1]: [(array([2, 3], dtype=int64), array([0, 0], dtype=int64)), (array([1], dtype=int64), array([0], dtype=int64)), (array([0], dtype=int64), array([1], dtype=int64)), (array([0], dtype=int64), array([0], dtype=int64)), (array([2, 3], dtype=int64), array([1, 1], dtype=int64)), (array([1], dtype=int64), array([1], dtype=int64))] In [2]: A[max_indices(A, 8)[0]][0] Out[2]: array([ 0.89832036])
метод
np.argpartitionвозвращает только k самых больших индексов, выполняет локальную сортировку и быстрее, чемnp.argsort(выполнение полной сортировки), когда массив достаточно большой. Но возвращаемые индексы не в порядке возрастания/убывания. Скажем на примере:
мы видим, что если вы хотите строгий порядок возрастания верхних индексов k,
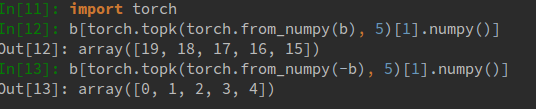
np.argpartitionне вернется то, что вы хотите.помимо выполнения сортировки вручную после НП.argpartition, мое решение-использовать PyTorch,
torch.topk, инструмент для построения нейронных сетей, обеспечивающий numpy-подобные API с поддержкой ЦП и GPU. Это так же быстро, как NumPy с MKL, и предлагает ускорение GPU, если вам нужны большие вычисления матрицы/вектора.строгий восходящий / нисходящий верхний код индексов k будет:
отметим, что
torch.topkпринимает тензор Факела и возвращает оба верхних значения k и верхние индексы k в типеtorch.Tensor. Аналогично с np, torch.topk также принимает аргумент оси, так что вы можете обрабатывать многомерные массивы/тензоры.

Я нашел его наиболее интуитивно понятным в использовании
np.unique.идея состоит в том, что уникальный метод возвращает индексы входных значений. Затем из максимального уникального значения и индексов можно воссоздать положение исходных значений.
multi_max = [1,1,2,2,4,0,0,4] uniques, idx = np.unique(multi_max, return_inverse=True) print np.squeeze(np.argwhere(idx == np.argmax(uniques))) >> [4 7]
Я думаю, что самый эффективный способ времени-это вручную перебирать массив и сохранять минимальную кучу k-размера, как уже упоминали другие люди.
и я также придумал подход грубой силы:
top_k_index_list = [ ] for i in range(k): top_k_index_list.append(np.argmax(my_array)) my_array[top_k_index_list[-1]] = -float('inf')установите для самого большого элемента большое отрицательное значение после использования argmax для получения его индекса. И тогда следующий вызов argmax вернет второй по величине элемент. И вы можете записать исходное значение этих элементов и восстановить их, если хотите.
следующий очень простой способ увидеть максимальные элементы и свои положения. Здесь
axisэто домен;axis= 0 означает максимальное число столбцов иaxis= 1 означает максимальное число строк для 2D-случая. А для высших измерений это зависит от вас.M = np.random.random((3, 4)) print(M) print(M.max(axis=1), M.argmax(axis=1))
Comments