Как работает HashPartitioner?
Я прочитал в документации HashPartitioner. К сожалению, ничего особенного не было объяснено, кроме вызовов API. Я исхожу из предположения, что HashPartitioner разбивает распределенный набор на основе хэша ключей. Например, если мои данные как
(1,1), (1,2), (1,3), (2,1), (2,2), (2,3)
таким образом, разделитель поместил бы это в разные разделы с одинаковыми ключами, попадающими в один и тот же раздел. Однако я не понимаю значение аргумента конструктора
new HashPartitoner(numPartitions) //What does numPartitions do?
для приведенного выше набора данных, как бы результаты отличались, если бы я сделал
new HashPartitoner(1)
new HashPartitoner(2)
new HashPartitoner(10)
так как HashPartitioner работать на самом деле?
3 ответов:
ну, давайте сделаем ваш набор данных немного более интересным:
val rdd = sc.parallelize(for { x <- 1 to 3 y <- 1 to 2 } yield (x, None), 8)у нас есть шесть элементов:
rdd.countLong = 6нет разметки:
rdd.partitionerOption[org.apache.spark.Partitioner] = Noneи восемь разделов:
rdd.partitions.lengthInt = 8теперь давайте определим небольшой помощник для подсчета количества элементов в разделе:
import org.apache.spark.rdd.RDD def countByPartition(rdd: RDD[(Int, None.type)]) = { rdd.mapPartitions(iter => Iterator(iter.length)) }поскольку у нас нет разделителя, наш набор данных равномерно распределяется между разделами (Разделение По Умолчанию Схема на Искра):
countByPartition(rdd).collect()Array[Int] = Array(0, 1, 1, 1, 0, 1, 1, 1)
теперь давайте переделаем наш набор данных:
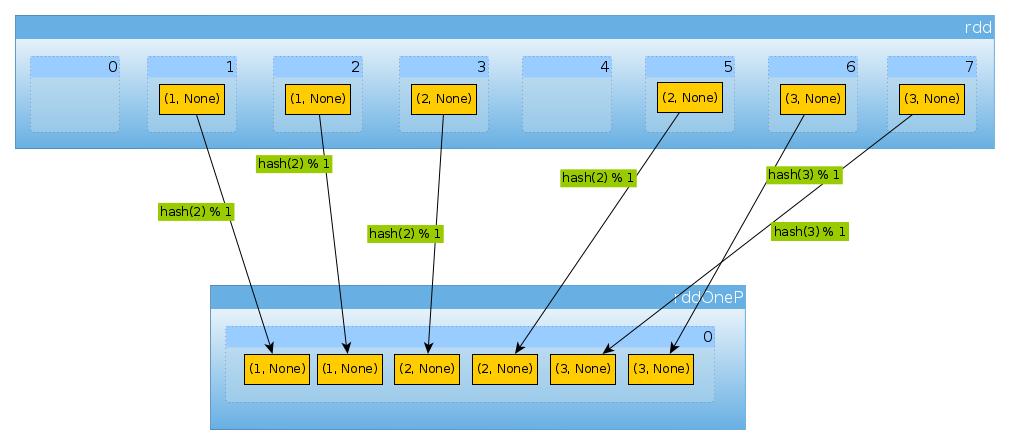
import org.apache.spark.HashPartitioner val rddOneP = rdd.partitionBy(new HashPartitioner(1))так как параметр передан в
HashPartitionerопределяет количество разделов, которые мы ожидаем один раздел:rddOneP.partitions.lengthInt = 1так как у нас есть только один раздел, он содержит все элементы:
countByPartition(rddOneP).collectArray[Int] = Array(6)
обратите внимание, что порядок значений после перетасовка является недетерминированной.
то же самое, если мы используем
HashPartitioner(2)val rddTwoP = rdd.partitionBy(new HashPartitioner(2))мы получим 2 раздела:
rddTwoP.partitions.lengthInt = 2С
rddразделяется по ключевым данным больше не будет распределяться равномерно:countByPartition(rddTwoP).collect()Array[Int] = Array(2, 4)потому что с имеют три ключа и только два разных значения
hashCodemodnumPartitionsздесь нет ничего неожиданного:(1 to 3).map((k: Int) => (k, k.hashCode, k.hashCode % 2))scala.collection.immutable.IndexedSeq[(Int, Int, Int)] = Vector((1,1,1), (2,2,0), (3,3,1))просто для подтверждения выше:
rddTwoP.mapPartitions(iter => Iterator(iter.map(_._1).toSet)).collect()Array[scala.collection.immutable.Set[Int]] = Array(Set(2), Set(1, 3))
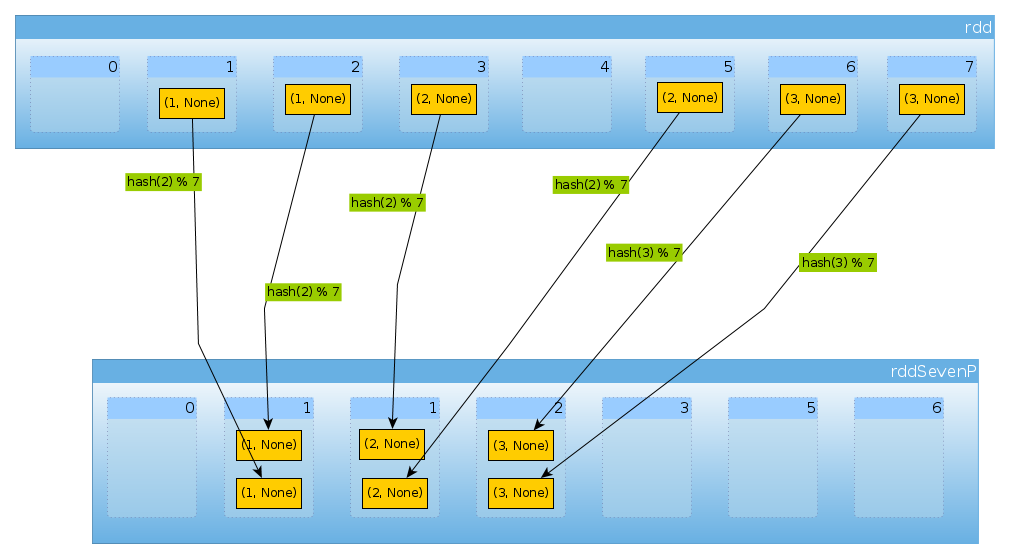
наконец-то с
HashPartitioner(7)мы получаем семь разделов, три непустых с 2 элементами каждый:val rddSevenP = rdd.partitionBy(new HashPartitioner(7)) rddSevenP.partitions.lengthInt = 7countByPartition(rddTenP).collect()Array[Int] = Array(0, 2, 2, 2, 0, 0, 0)
резюме и примечания
HashPartitionerпринимает один аргумент, который определяет количество разделовзначения присваиваются разделам с помощью
hashof ключи.hashфункция может отличаться в зависимости от языка (Scala RDD может использоватьhashCode,DataSetsиспользуйте MurmurHash 3, PySpark,portable_hash).в простом случае, как это, где ключ является малым целым числом, вы можете предположить, что
hash- это идентификатор (i = hash(i)).Scala API использует
nonNegativeModчтобы определить раздел на основе вычисленного хэша,если распределение ключей не является однородным, вы можете в конечном итоге в ситуации, когда часть вашего кластера простаивает
ключи должны быть hashable. Вы можете проверить мой ответ для список в качестве ключа для reduceByKey PySpark чтобы прочитать о конкретных проблемах PySpark. Еще одна возможная проблема выделена документация HashPartitioner:
массивы Java имеют хэш-коды, основанные на идентификаторах массивов, а не на их содержимом, поэтому попытка разбить RDD [Array[]] или RDD [(Array[],_)] использование HashPartitioner приведет к неожиданному или неправильному результату.
в Python 3, Вы должны убедиться, что хеширование-это последовательное. Смотрите что означает исключение: случайность хэша строки должна быть отключена через PYTHONHASHSEED в pyspark?
hash partitioner не является ни инъективным, ни сюръективным. Различные ключи могут быть назначены один раздел и некоторые разделы могут оставаться пустыми.
обратите внимание, что в настоящее время методы на основе хэша не работают в Scala в сочетании с REPL определенными классами case (равенство классов в Apache Spark).
HashPartitioner(или любой другойPartitioner) тасует данные. Если секционирование не используется повторно между несколькими операциями, это не уменьшает количество данных, которые нужно перетасовать.

RDD распределяется это означает, что он разделен на некоторое количество частей. Каждый из этих разделов потенциально находится на разных машинах. Хэш-разделения с арумент
numPartitionsвыбирает на каком разделе разместить пару(key, value)в следующую сторону:
- создает
numPartitionsразделы.- мест
(key, value)в разделе с номеромHash(key) % numPartitions
The
HashPartitioner.getPartitionметод принимает ключ как его аргумент и возвращает индекс раздела, к которому принадлежит ключ. Разделитель должен знать, что такое допустимые индексы, поэтому он возвращает числа в правильном диапазоне. Количество разделов указывается черезnumPartitionsаргумент конструктора.реализация возвращает примерно
key.hashCode() % numPartitions. Смотрите разметки.скала для более подробной информации.
Comments