Насколько эффективна блокировка разблокированного мьютекса? Какова стоимость мьютекса?
на языке низкого уровня (C, C++ или что-то еще): у меня есть выбор между тем, чтобы иметь кучу мьютексов (например, то, что дает мне pthread или что предоставляет собственная системная библиотека) или один для объекта.
насколько эффективно блокировать мьютекс? Т. е. сколько существует инструкций ассемблера и сколько времени они занимают (в случае разблокировки мьютекса)?
сколько стоит мьютекс? Это проблема, чтобы иметь действительно a много мьютексы? Или я могу просто бросить столько переменных мьютекса в моем коде, сколько у меня есть int переменные и это действительно не имеет значения?
(Я не уверен, сколько различий есть между различными аппаратными средствами. Если есть, я также хотел бы знать о них. Но в основном меня интересует общее оборудование.)
дело в том, что, используя много мьютексов, каждый из которых охватывает только часть объекта вместо одного мьютекса для всего объекта, я мог бы защитить много блоки. И мне интересно, как далеко я должен идти по этому поводу. Т. е. должен ли я попытаться защитить любой возможный блок действительно насколько это возможно, независимо от того, насколько сложнее и насколько больше мьютексов это означает?
4 ответов:
У меня есть выбор между тем, чтобы иметь кучу мьютексов или один для объекта.
Если у вас много потоков и доступ к объекту происходит часто, то несколько блокировок увеличат параллелизм. За счет ремонтопригодности, так как больше блокировок означает больше отладки блокировки.
насколько эффективно блокировать мьютекс? Т. е. сколько существует инструкций ассемблера и сколько времени они занимают (в дело в том, что мьютекс разблокирован)?
точные инструкции ассемблера являются наименьшими накладными расходами мьютекс -когерентность памяти/кэша гарантии являются основные расходы. И реже берется тот или иной замок - лучше.
мьютекс состоит из двух основных частей (упрощение): (1) флаг, указывающий, заблокирован ли мьютекс или нет и (2) очередь ожидания.
изменение флага-это всего лишь несколько инструкций и обычно делается без системного вызова. Если мьютекс заблокирован, syscall добавит вызывающий поток в очередь ожидания и запустит ожидание. Разблокировка, если очередь ожидания пуста, дешева, но в противном случае требуется syscall, чтобы разбудить один из процессов ожидания. (На некоторых системах дешевые / быстрые системные вызовы используются для реализации мьютексов, они становятся медленными (обычными) системными вызовами только в случае конкуренции.)
блокировка разблокированного мьютекса действительно дешевая. Разблокировка мьютекса без конкуренции дешево тоже.
сколько стоит мьютекс? Это проблема, чтобы иметь действительно много мьютексов? Или я могу просто бросить столько переменных мьютекса в моем коде, сколько у меня есть переменные int, и это действительно не имеет значения?
вы можете добавить в свой код столько переменных мьютекса, сколько захотите. Вы ограничены только объемом памяти, который может выделить приложение.
резюме. Блокировки пользовательского пространства (и мьютексы в частности) дешевы и не подвергаются никакому воздействию предел системы. Но слишком многие из них заклинания кошмар для отладки. Простая таблица:
- меньше блокировок означает больше конфликтов (медленные системные вызовы, остановки процессора) и меньший параллелизм
- меньше блокировок означает меньше проблем отладки многопоточных проблем.
- больше блокировок означает меньше споров и более высокий параллелизм
- больше замков означает больше шансов столкнуться с неразрешимыми тупиками.
сбалансированная схема блокировки для приложение должно быть найдено и поддержано, как правило, балансируя #2 и #3.
(*) проблема с менее часто блокируемыми мьютексами заключается в том, что если у вас слишком много блокировок в вашем приложении, это приводит к тому, что большая часть межпроцессорного/основного трафика очищает память мьютекса от кэша данных других процессоров, чтобы гарантировать когерентность кэша. Промывки кэша похожи на легкие прерывания и обрабатываются процессорами прозрачно , но они вводят так называемые глохнет (поиск "стойло").
и киоски-это то, что заставляет код блокировки работать медленно, часто без каких-либо видимых признаков того, почему приложение работает медленно. (Некоторые arch предоставляют статистику трафика между процессорами/ядрами, некоторые нет.)
чтобы избежать проблемы, люди обычно прибегают к большому количеству замков, чтобы уменьшить вероятность конфликтов блокировки и избежать срыва. Именно по этой причине дешевое пользовательское пространство блокируется, не подвергаясь воздействию системы пределы, существует.
Это зависит от того, что вы на самом деле называете "мьютекс", режим ОС и т. д.
At минимум это стоимость операции с блокированной памятью. Это относительно тяжелая операция (по сравнению с другими примитивными командами ассемблера).
однако, это может быть гораздо выше. Если то, что вы называете "мьютексом", является объектом ядра (т. е. объектом, управляемым ОС) и выполняется в пользовательском режиме - каждая операция на нем приводит к транзакции режима ядра, которая очень тяжелый.
например, на процессоре Intel Core Duo, Windows XP. Блокируемая работа: занимает около 40 циклов процессора. Вызов режима ядра (т. е. системный вызов) - около 2000 циклов процессора.
Если это так - вы можете использовать критические секции. Это гибрид мьютекса ядра и блокированного доступа к памяти.
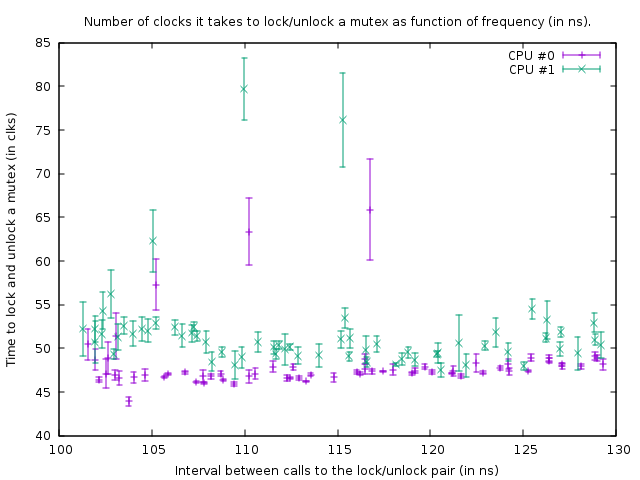
Я хотел бы знать то же самое, поэтому я измерил его. На моей коробке (AMD FX (tm)-8150 восьмиядерный процессор на 3,612361 ГГц), блокировка и разблокировка разблокированного мьютекса, который находится в своей собственной строке кэша и уже кэширован, занимает 47 часов (13 НС).
из-за синхронизации между двумя ядрами (я использовал CPU #0 и #1), Я мог только вызвать пару блокировки / разблокировки один раз каждые 102 НС на двух потоках, таким образом, один раз в 51 НС, из чего можно сделать вывод, что для восстановления после a требуется примерно 38 НС поток делает разблокировку, прежде чем следующий поток может заблокировать его снова.
программа, которую я использовал для исследования этого можно найти здесь: https://github.com/CarloWood/ai-statefultask-testsuite/blob/b69b112e2e91d35b56a39f41809d3e3de2f9e4b8/src/mutex_test.cxx
обратите внимание, что у него есть несколько жестко закодированных значений, специфичных для my box (xrange, yrange и RDTSC накладные расходы), поэтому вам, вероятно, придется поэкспериментировать с ним, прежде чем он будет работать для вас.
графика это производит в таком состоянии:
Это показывает результат тест выполняется на следующий код:
uint64_t do_Ndec(int thread, int loop_count) { uint64_t start; uint64_t end; int __d0; asm volatile ("rdtsc\n\tshl , %%rdx\n\tor %%rdx, %0" : "=a" (start) : : "%rdx"); mutex.lock(); mutex.unlock(); asm volatile ("rdtsc\n\tshl , %%rdx\n\tor %%rdx, %0" : "=a" (end) : : "%rdx"); asm volatile ("\n1:\n\tdecl %%ecx\n\tjnz 1b" : "=c" (__d0) : "c" (loop_count - thread) : "cc"); return end - start; }два вызова rdtsc измеряют количество часов, которое требуется для блокировки и разблокировки "мьютекса" (с накладными расходами 39 часов для вызовов rdtsc на моем поле). Третий asm-это цикл задержки. Размер петли задержки на 1 отсчет меньше для потока 1, чем для потока 0, поэтому поток 1 немного быстрее.
в выше функция вызывается в плотном цикле размером 100,000. Несмотря на то, что функция немного быстрее для потока 1, оба цикла синхронизируются из-за вызова мьютекса. Это видно на графике из того факта, что количество часов, измеренных для пары блокировки/разблокировки, немного больше для потока 1, чтобы учесть более короткую задержку в цикле ниже его.
на приведенном выше графике нижняя правая точка является измерением с задержкой loop_count 150, а затем после точки внизу, слева, loop_count уменьшается на один каждый измерения. Когда он становится 77 функция вызывается каждые 102 НС в обоих потоках. Если впоследствии loop_count уменьшается еще больше, больше невозможно синхронизировать потоки, и мьютекс начинает фактически блокироваться большую часть времени, что приводит к увеличению количества часов, необходимых для блокировки/разблокировки. Также из-за этого увеличивается среднее время вызова функции; поэтому точки графика теперь снова поднимитесь и поверните направо.
из этого можно сделать вывод, что блокировка и разблокировка мьютекса каждые 50 НС не является проблемой на моем поле.
в целом мой вывод заключается в том, что ответ на вопрос OP заключается в том, что добавление большего количества мьютексов лучше, если это приводит к меньшему количеству споров.
попробуйте заблокировать мьютексы как можно короче. Единственная причина поставить их - скажем-вне цикла будет, если этот цикл петель быстрее, чем один раз каждые 100 нс (или скорее, количество потоков, которые хотят запустить этот цикл в то же время раз 50 НС) или когда 13 НС раз размер цикла больше задержки, чем задержка, которую вы получаете по спору.
EDIT: теперь я получил гораздо больше знаний по этому вопросу и начинаю сомневаться в выводе, который я представил здесь. Прежде всего, CPU 0 и 1 оказываются гиперпоточными; хотя AMD утверждает, что имеет 8 реальных ядер, есть, конечно, что-то очень подозрительное, потому что задержки между двумя другими ядрами намного больше (т. е. 0 и 1 образуют пару, как и 2 и 3, 4 и 5, и 6 и 7). Во-вторых, мьютекс std::реализован таким образом, что он немного блокирует спин, прежде чем фактически выполнять системные вызовы, когда он не может сразу получить блокировку на мьютексе (что, несомненно, будет чрезвычайно медленным). Таким образом, то, что я измерил здесь, является абсолютным самым идеальным местом, и на практике блокировка и разблокировка могут занять значительно больше времени на блокировку/разблокировку.
итог, мьютекс реализуется с помощью атомики. К синхронизация атомов между ядрами внутренняя шина должна быть заблокирована, что замораживает соответствующую строку кэша на несколько сотен тактов. В случае, если блокировка не может быть получена, системный вызов должен быть выполнен, чтобы перевести поток в спящий режим; это, очевидно, очень медленно. Обычно это не проблема, потому что этот поток должен спать в любом случае-но это может быть проблема с высокой конкуренцией, когда поток не может получить Блокировку в течение времени, когда он обычно вращается, и так делает системный вызов, но может взять замок вскоре после этого. Например, если несколько потоков фиксируют и разблокируют мьютекс в плотном цикле, и каждый держит блокировку в течение 1 микросекунды или около того, то они могут быть чрезвычайно замедлены тем фактом, что они постоянно засыпают и снова просыпаются.
стоимость будет варьироваться в зависимости от реализации, но вы должны иметь в виду две вещи:
- стоимость, скорее всего, будет минимальной, так как это довольно примитивная операция, и она будет максимально оптимизирована за счет ее шаблона использования (используется много).
- это не имеет значения, насколько это дорого, так как вы должны использовать его, если вы хотите безопасную многопоточную работу. Если вам это нужно, то вам это нужно.
на однопроцессорные системы, как правило, можно просто отключить прерывания достаточно долго, чтобы атомарно изменить данные. Многопроцессорные системы могут использовать test-and-set стратегии.
в обоих этих случаях инструкции относительно эффективны.
Что касается того, следует ли предоставлять один мьютекс для массивной структуры данных или иметь много мьютексов, по одному для каждого раздела, это балансировка.
, имея один мьютекс, у вас есть высокий риск раздора между несколькими потоками. Вы можете уменьшить этот риск, имея мьютекс на секцию, но вы не хотите попасть в ситуацию, когда поток должен заблокировать 180 мьютексов, чтобы выполнить свою работу :-)
Comments