Как преобразовать строку в нижний регистр в Bash?
есть ли способ в Баш чтобы преобразовать строку в строку нижнего регистра?
например, если у меня есть:
a="Hi all"
Я хочу преобразовать его в:
"hi all"
19 ответов:
существуют различные способы:
POSIX standard
tr
$ echo "$a" | tr '[:upper:]' '[:lower:]' hi allAWK
$ echo "$a" | awk '{print tolower()}' hi allNon-POSIX
вы можете столкнуться с проблемами переносимости следующие примеры:
Баш 4.0
$ echo "${a,,}" hi allsed
$ echo "$a" | sed -e 's/\(.*\)/\L/' hi all # this also works: $ sed -e 's/\(.*\)/\L/' <<< "$a" hi allPerl
$ echo "$a" | perl -ne 'print lc' hi allБаш
lc(){ case "" in [A-Z]) n=$(printf "%d" "'") n=$((n+32)) printf \$(printf "%o" "$n") ;; *) printf "%s" "" ;; esac } word="I Love Bash" for((i=0;i<${#word};i++)) do ch="${word:$i:1}" lc "$ch" done
В Bash 4:
в нижнем регистре
$ string="A FEW WORDS" $ echo "${string,}" a FEW WORDS $ echo "${string,,}" a few words $ echo "${string,,[AEIUO]}" a FeW WoRDS $ string="A Few Words" $ declare -l string $ string=$string; echo "$string" a few wordsв верхний регистр
$ string="a few words" $ echo "${string^}" A few words $ echo "${string^^}" A FEW WORDS $ echo "${string^^[aeiou]}" A fEw wOrds $ string="A Few Words" $ declare -u string $ string=$string; echo "$string" A FEW WORDSToggle (недокументированный, но при необходимости настраивается во время компиляции)
$ string="A Few Words" $ echo "${string~~}" a fEW wORDS $ string="A FEW WORDS" $ echo "${string~}" a FEW WORDS $ string="a few words" $ echo "${string~}" A few wordsCapitalize (недокументированный, но при необходимости настраивается во время компиляции)
$ string="a few words" $ declare -c string $ string=$string $ echo "$string" A few wordsTitle case:
$ string="a few words" $ string=($string) $ string="${string[@]^}" $ echo "$string" A Few Words $ declare -c string $ string=(a few words) $ echo "${string[@]}" A Few Words $ string="a FeW WOrdS" $ string=${string,,} $ string=${string~} $ echo "$string" A few wordsчтобы отключить a
я знаю, что это старый пост, но я сделал этот ответ для другого сайта, поэтому я думал, что опубликую его здесь:
верхний -> нижний: используйте python:
b=`echo "print '$a'.lower()" | python`Или Ruby:
b=`echo "print '$a'.downcase" | ruby`или Perl (наверное, мой любимый):
b=`perl -e "print lc('$a');"`или PHP:
b=`php -r "print strtolower('$a');"`Или Awk:
b=`echo "$a" | awk '{ print tolower() }'`Или Sed:
b=`echo "$a" | sed 's/./\L&/g'`Или Bash 4:
b=${a,,}или NodeJS, если у вас есть (и немного орешки...):
b=`echo "console.log('$a'.toLowerCase());" | node`вы также можете использовать
dd(но я бы не стал!):b=`echo "$a" | dd conv=lcase 2> /dev/null`снизу -> верхней:
использовать python:
b=`echo "print '$a'.upper()" | python`Или Ruby:
b=`echo "print '$a'.upcase" | ruby`или Perl (наверное, мой любимый):
b=`perl -e "print uc('$a');"`или PHP:
b=`php -r "print strtoupper('$a');"`Или Awk:
b=`echo "$a" | awk '{ print toupper() }'`Или Sed:
b=`echo "$a" | sed 's/./\U&/g'`Или Bash 4:
b=${a^^}или NodeJS, если у вас есть (и немного чокнутые...):
b=`echo "console.log('$a'.toUpperCase());" | node`вы также можете использовать
dd(но я бы не стал!):b=`echo "$a" | dd conv=ucase 2> /dev/null`также, Когда вы говорите "shell" я предполагаю, что вы имеете в виду
bashно если вы можете использоватьzshэто так же просто, какb=$a:lдля нижнего регистра и
b=$a:uв верхнем регистре.
С помощью GNU
sed:sed 's/.*/\L&/'пример:
$ foo="Some STRIng"; $ foo=$(echo "$foo" | sed 's/.*/\L&/') $ echo "$foo" some string
для стандартной оболочки (без башизмов), используя только встроенные:
uppers=ABCDEFGHIJKLMNOPQRSTUVWXYZ lowers=abcdefghijklmnopqrstuvwxyz lc(){ #usage: lc "SOME STRING" -> "some string" i=0 while ([ $i -lt ${#1} ]) do CUR=${1:$i:1} case $uppers in *$CUR*)CUR=${uppers%$CUR*};OUTPUT="${OUTPUT}${lowers:${#CUR}:1}";; *)OUTPUT="${OUTPUT}$CUR";; esac i=$((i+1)) done echo "${OUTPUT}" }и для верхнего регистра:
uc(){ #usage: uc "some string" -> "SOME STRING" i=0 while ([ $i -lt ${#1} ]) do CUR=${1:$i:1} case $lowers in *$CUR*)CUR=${lowers%$CUR*};OUTPUT="${OUTPUT}${uppers:${#CUR}:1}";; *)OUTPUT="${OUTPUT}$CUR";; esac i=$((i+1)) done echo "${OUTPUT}" }
Pre Bash 4.0
Bash опустите регистр строки и назначьте переменной
VARIABLE=$(echo "$VARIABLE" | tr '[:upper:]' '[:lower:]') echo "$VARIABLE"
регулярные выражения
Я хотел бы взять на себя ответственность за команду, которую я хочу поделиться, но правда в том, что я получил ее для собственного использования от http://commandlinefu.com. это имеет то преимущество, что если вы
cdв любой каталог в вашей собственной домашней папке, то есть он будет изменять все файлы и папки в нижнем регистре рекурсивно, пожалуйста, используйте с осторожностью. Это блестящее исправление командной строки и особенно полезно для тех множества альбомов, которые вы сохранили на своем компьютере водить.find . -depth -exec rename 's/(.*)\/([^\/]*)/\/\L/' {} \;вы можете указать каталог вместо точки(.) после поиска, который обозначает текущий каталог или полный путь.
Я надеюсь, что это решение окажется полезным одна вещь, которую эта команда не делает, это заменить пробелы подчеркиванием - ну, в другой раз, возможно.
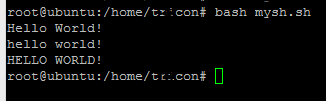
вы можете попробовать это
s="Hello World!" echo $s # Hello World! a=${s,,} echo $a # hello world! b=${s^^} echo $b # HELLO WORLD!
ref : http://wiki.workassis.com/shell-script-convert-text-to-lowercase-and-uppercase/
при использовании v4, это запеченные-в. Если нет, то вот простой, широко применяется решение. Другие ответы (и комментарии) на эту тему были весьма полезны при создании кода ниже.
# Like echo, but converts to lowercase echolcase () { tr [:upper:] [:lower:] <<< "${*}" } # Takes one arg by reference (var name) and makes it lowercase lcase () { eval ""=\'$(echo ${!1//\'/"'\''"} | tr [:upper:] [:lower:] )\' }Примечания:
- делаем:
a="Hi All"и затем:lcase aбудет делать то же самое, что:a=$( echolcase "Hi All" )- в функции lcase, используя
${!1//\'/"'\''"}вместо${!1}позволяет это работать, даже если строка имеет двойные кавычки.
для версий Bash более ранних, чем 4.0, эта версия должна быть самой быстрой (так как это не fork / exec любой команды):
function string.monolithic.tolower { local __word= local __len=${#__word} local __char local __octal local __decimal local __result for (( i=0; i<__len; i++ )) do __char=${__word:$i:1} case "$__char" in [A-Z] ) printf -v __decimal '%d' "'$__char" printf -v __octal '%03o' $(( $__decimal ^ 0x20 )) printf -v __char \$__octal ;; esac __result+="$__char" done REPLY="$__result" }ответ технозавра был потенциал тоже, хотя он работал должным образом для Ми.
несмотря на то, насколько стар этот вопрос и похож на это ответ технозавра. Мне было трудно найти решение, которое было переносимым на большинстве платформ (которые я использую), а также более старые версии bash. Я также был разочарован массивами, функциями и использованием отпечатков, эхо-сигналов и временных файлов для извлечения тривиальных переменных. Это работает очень хорошо для меня до сих пор я думал, что поделюсь. Мои основные среды тестирования:
- GNU bash, версия 4.1.2 (1)-release (x86_64-redhat-linux-gnu)
- GNU bash, версия 3.2.57 (1)-release (sparc-sun-solaris2.10)
lcs="abcdefghijklmnopqrstuvwxyz" ucs="ABCDEFGHIJKLMNOPQRSTUVWXYZ" input="Change Me To All Capitals" for (( i=0; i<"${#input}"; i++ )) ; do : for (( j=0; j<"${#lcs}"; j++ )) ; do : if [[ "${input:$i:1}" == "${lcs:$j:1}" ]] ; then input="${input/${input:$i:1}/${ucs:$j:1}}" fi done doneпростой C-стиль для петли для перебора строк. На строку ниже, если вы не видели ничего подобного раньше вот где я этому научился. В этом случае строка проверяет, существует ли символ ${input:$i:1} (нижний регистр) во input и если да, то заменяет его заданным символом ${ucs:$j: 1} (верхний регистр) и сохраняет его обратно во вход.
input="${input/${input:$i:1}/${ucs:$j:1}}"
многие ответы с использованием внешних программ, которые на самом деле не используют
Bash.если вы знаете, что у вас будет Bash4, вы действительно должны просто использовать
${VAR,,}нотации (это легко и круто). Для Bash до 4 (мой Mac все еще использует Bash 3.2, например). Я использовал исправленную версию ответа @ghostdog74 для создания более портативной версии.один вы можете позвонить
lowercase 'my STRING'и получить версию в нижнем регистре. Я читал комментарии о настройке результата на var, но это не очень портативный вBash, так как мы не можем возвращать строки. Печать это лучшее решение. Легко захватить с чем-то вродеvar="$(lowercase $str)".как это работает
как это работает, получая целочисленное представление ASCII каждого символа с
printfа тоadding 32еслиupper-to->lowerилиsubtracting 32еслиlower-to->upper. Тогда используйтеprintfснова преобразовывать число обратно в char. От'A' -to-> 'a'у нас есть разница в 32 пеструшки.используя
printfобъяснить:$ printf "%d\n" "'a" 97 $ printf "%d\n" "'A" 65
97 - 65 = 32и это рабочая версия с примерами.
Обратите внимание на комментарии в коде, так как они объясняют много вещей:#!/bin/bash # lowerupper.sh # Prints the lowercase version of a char lowercaseChar(){ case "" in [A-Z]) n=$(printf "%d" "'") n=$((n+32)) printf \$(printf "%o" "$n") ;; *) printf "%s" "" ;; esac } # Prints the lowercase version of a sequence of strings lowercase() { word="$@" for((i=0;i<${#word};i++)); do ch="${word:$i:1}" lowercaseChar "$ch" done } # Prints the uppercase version of a char uppercaseChar(){ case "" in [a-z]) n=$(printf "%d" "'") n=$((n-32)) printf \$(printf "%o" "$n") ;; *) printf "%s" "" ;; esac } # Prints the uppercase version of a sequence of strings uppercase() { word="$@" for((i=0;i<${#word};i++)); do ch="${word:$i:1}" uppercaseChar "$ch" done } # The functions will not add a new line, so use echo or # append it if you want a new line after printing # Printing stuff directly lowercase "I AM the Walrus!"$'\n' uppercase "I AM the Walrus!"$'\n' echo "----------" # Printing a var str="A StRing WITH mixed sTUFF!" lowercase "$str"$'\n' uppercase "$str"$'\n' echo "----------" # Not quoting the var should also work, # since we use "$@" inside the functions lowercase $str$'\n' uppercase $str$'\n' echo "----------" # Assigning to a var myLowerVar="$(lowercase $str)" myUpperVar="$(uppercase $str)" echo "myLowerVar: $myLowerVar" echo "myUpperVar: $myUpperVar" echo "----------" # You can even do stuff like if [[ 'option 2' = "$(lowercase 'OPTION 2')" ]]; then echo "Fine! All the same!" else echo "Ops! Not the same!" fi exit 0и результаты после выполнения этого:
$ ./lowerupper.sh i am the walrus! I AM THE WALRUS! ---------- a string with mixed stuff! A STRING WITH MIXED STUFF! ---------- a string with mixed stuff! A STRING WITH MIXED STUFF! ---------- myLowerVar: a string with mixed stuff! myUpperVar: A STRING WITH MIXED STUFF! ---------- Fine! All the same!это должно работать только для символов ASCII, хотя.
для меня это нормально, так как я знаю, что я только передам ему ASCII-символы.
Я я использую это для некоторых вариантов CLI без учета регистра, например.
преобразование дело делается только для алфавитов. Так что, это должно работать аккуратно.
Я сосредоточен на преобразовании алфавитов между a-z из верхнего регистра в нижний регистр. Любые другие символы должны быть напечатаны в stdout, как это...
преобразует весь текст в path / to/file / filename в диапазоне a-z в A-Z
для преобразования нижнего регистра в верхний регистр
cat path/to/file/filename | tr 'a-z' 'A-Z'для преобразования из верхнего регистра в нижний регистр
cat path/to/file/filename | tr 'A-Z' 'a-z'для например,
имя файла:
my name is xyzпреобразуется к виду:
MY NAME IS XYZПример 2:
echo "my name is 123 karthik" | tr 'a-z' 'A-Z' # Output: # MY NAME IS 123 KARTHIKПример 3:
echo "my name is 123 &&^&& #@$#@%%& kAR2~thik" | tr 'a-z' 'A-Z' # Output: # MY NAME IS 123 &&^&& #@0@%%& KAR2~THIK
для хранения преобразованной строки в переменную. Следующие работал для меня -
$SOURCE_NAMEto$TARGET_NAMETARGET_NAME="`echo $SOURCE_NAME | tr '[:upper:]' '[:lower:]'`"
это гораздо более быстрый вариант подход JaredTS486 который использует собственные возможности Bash (включая версии Bash
Я рассчитал 1000 итераций этого подхода для небольшой строки (25 символов) и большей строки (445 символов), как для строчных, так и для прописных преобразований. Поскольку тестовые строки преимущественно строчные, преобразования в строчные обычно выполняются быстрее, чем в прописные.
Я сравнил мой подход с несколькими другими ответами на этой странице, которые совместимы с Bash 3.2. Мой подход гораздо более эффективен, чем большинство подходов, описанных здесь, и даже быстрее, чем
trв нескольких случаях.вот результаты синхронизации для 1000 итераций 25 символов:
- 0.46 s для моего подхода к строчному регистру; 0.96 s для верхнего регистра
- 1.16 s для Orwellophile это в нижнем регистре; 1.59 s для прописные буквы
- 3,67 С для
trв нижнем регистре; 3.81 s для верхнего регистра- 11.12 s для подход ghostdog74 в нижнем регистре; 31.41 s для верхнего регистра
- 26.25 s для подход технозавра в нижнем регистре; 26.21 s для верхнего регистра
- 25.06 s для подход JaredTS486 в нижнем регистре; 27.04 s для верхнего регистра
результаты синхронизации для 1000 итераций 445 символов (состоящий из стихотворения "Малиновка" Уиттера Биннера):
- 2s для моего подхода в нижнем регистре; 12s для верхнего регистра
- 4s для
trв нижнем регистре; 4s для верхнего регистра- 20s для Orwellophile это в нижнем регистре; 29s для верхнего регистра
- 75s для ghostdog74 это подход к строчному регистру; 669 для верхнего регистра. Интересно отметить, насколько драматична разница в производительности между тестом с преобладающими совпадениями и тестом с преобладающие промахи
- 467s для подход технозавра в нижнем регистре; 449s для верхнего регистра
- 660-е годы для подход JaredTS486 в нижнем регистре; 660 для верхнего регистра. Интересно отметить, что этот подход генерировал непрерывные ошибки страницы (замена памяти) в Bash
устранение:
#!/bin/bash set -e set -u declare LCS="abcdefghijklmnopqrstuvwxyz" declare UCS="ABCDEFGHIJKLMNOPQRSTUVWXYZ" function lcase() { local TARGET="${1-}" local UCHAR='' local UOFFSET='' while [[ "${TARGET}" =~ ([A-Z]) ]] do UCHAR="${BASH_REMATCH[1]}" UOFFSET="${UCS%%${UCHAR}*}" TARGET="${TARGET//${UCHAR}/${LCS:${#UOFFSET}:1}}" done echo -n "${TARGET}" } function ucase() { local TARGET="${1-}" local LCHAR='' local LOFFSET='' while [[ "${TARGET}" =~ ([a-z]) ]] do LCHAR="${BASH_REMATCH[1]}" LOFFSET="${LCS%%${LCHAR}*}" TARGET="${TARGET//${LCHAR}/${UCS:${#LOFFSET}:1}}" done echo -n "${TARGET}" }подход прост: в то время как входная строка содержит все оставшиеся прописные буквы, найдите следующую, и замените все экземпляры этой буквы ее строчным вариантом. Повторяйте до тех пор, пока все заглавные буквы не будут заменены.
некоторые характеристики моего решения:
- использует только встроенные утилиты оболочки, что позволяет избежать накладных расходов на вызов внешних двоичных утилит в новом процессе
- избегает суб-оболочек, которые несут штрафы за производительность
- использует механизмы оболочки, которые скомпилированы и оптимизированы для повышения производительности, такие как глобальная замена строк в переменных, обрезка суффиксов переменных и поиск и сопоставление регулярных выражений. Эти механизмы намного быстрее, чем итерация вручную через строки
- циклы только количество раз, необходимое для количества уникальных совпадающих символов, которые будут преобразованы. Например, для преобразования строки, содержащей три разных символа верхнего регистра в Нижний, требуется всего 3 итерации цикла. Для предварительно настроенного алфавита ASCII максимальное число итераций цикла это 26
UCSиLCSможно дополнить дополнительными символами
Comments