13 ответов:
этот фрагмент работает в конкретной ситуации, когда у вас есть логическое значение: он отвечает "сколько существует не-Ns?".
SELECT LEN(REPLACE(col, 'N', ''))Если в другой ситуации вы действительно пытались подсчитать вхождения определенного символа (например, 'Y') в любой заданной строке, используйте это:
SELECT LEN(col) - LEN(REPLACE(col, 'Y', ''))
Это дало мне точные результаты каждый раз...
это в поле мои полосы... Желтый,Желтый,Желтый,Желтый,Желтый,Желтый,Черный,Желтый,Желтый,Красный,Желтый,Желтый,Желтый, Черный
- 11 желтых
- 2 Черный
- 1 красный
SELECT (LEN(Stripes) - LEN(REPLACE(Stripes, 'Red', ''))) / LEN('Red') FROM t_Contacts
DECLARE @StringToFind VARCHAR(100) = "Text To Count" SELECT (LEN([Field To Search]) - LEN(REPLACE([Field To Search],@StringToFind,'')))/COALESCE(NULLIF(LEN(@StringToFind), 0), 1) --protect division from zero FROM [Table To Search]
самый простой способ-использовать функцию Oracle:
SELECT REGEXP_COUNT(COLUMN_NAME,'CONDITION') FROM TABLE_NAME
попробуй такое
declare @v varchar(250) = 'test.a,1 ;hheuw-20;' -- LF ; select len(replace(@v,';','11'))-len(@v)
Попробуйте Это. Это определяет нет. вхождения одного символа, а также вхождения подстроки в основной строке.
SELECT COUNT(DECODE(SUBSTR(UPPER(:main_string),rownum,LENGTH(:search_char)),UPPER(:search_char),1)) search_char_count FROM DUAL connect by rownum <= length(:main_string);
Если вы хотите подсчитать количество экземпляров строк с более чем одним символом, вы можете либо использовать предыдущее решение с регулярным выражением, либо это решение использует STRING_SPLIT, который, я считаю, был представлен в SQL Server 2016. Также вам понадобится уровень совместимости 130 и выше.
ALTER DATABASE [database_name] SET COMPATIBILITY_LEVEL = 130.
--some data DECLARE @table TABLE (col varchar(500)) INSERT INTO @table SELECT 'whaCHAR(10)teverCHAR(10)whateverCHAR(10)' INSERT INTO @table SELECT 'whaCHAR(10)teverwhateverCHAR(10)' INSERT INTO @table SELECT 'whaCHAR(10)teverCHAR(10)whateverCHAR(10)~' --string to find DECLARE @string varchar(100) = 'CHAR(10)' --select SELECT col , (SELECT COUNT(*) - 1 FROM STRING_SPLIT (REPLACE(REPLACE(col, '~', ''), 'CHAR(10)', '~'), '~')) AS 'NumberOfBreaks' FROM @table
второй ответ, предоставленный nickf, очень умный. Однако он работает только для длины символа целевой подстроки 1 и игнорирует пробелы. В частности, в моих данных было два ведущих пробела, которые SQL услужливо удаляет (я этого не знал), когда все символы на правой стороне удаляются. Что означало, что
" Джон Смит"
генерируется 12 с помощью метода Nickf, в то время как:
" Джо Блоггс, Джон Смит"
генерируется 10, и
"Джо Блогс, Джон Смит, Джон Смит"
сгенерирован 20.
поэтому я немного изменил решение следующим образом, который работает для меня:
Select (len(replace(Sales_Reps,' ',''))- len(replace((replace(Sales_Reps, ' ','')),'JohnSmith','')))/9 as Count_JSЯ уверен, что кто-то может придумать лучшего способа сделать это!
вы также можете попробовать это
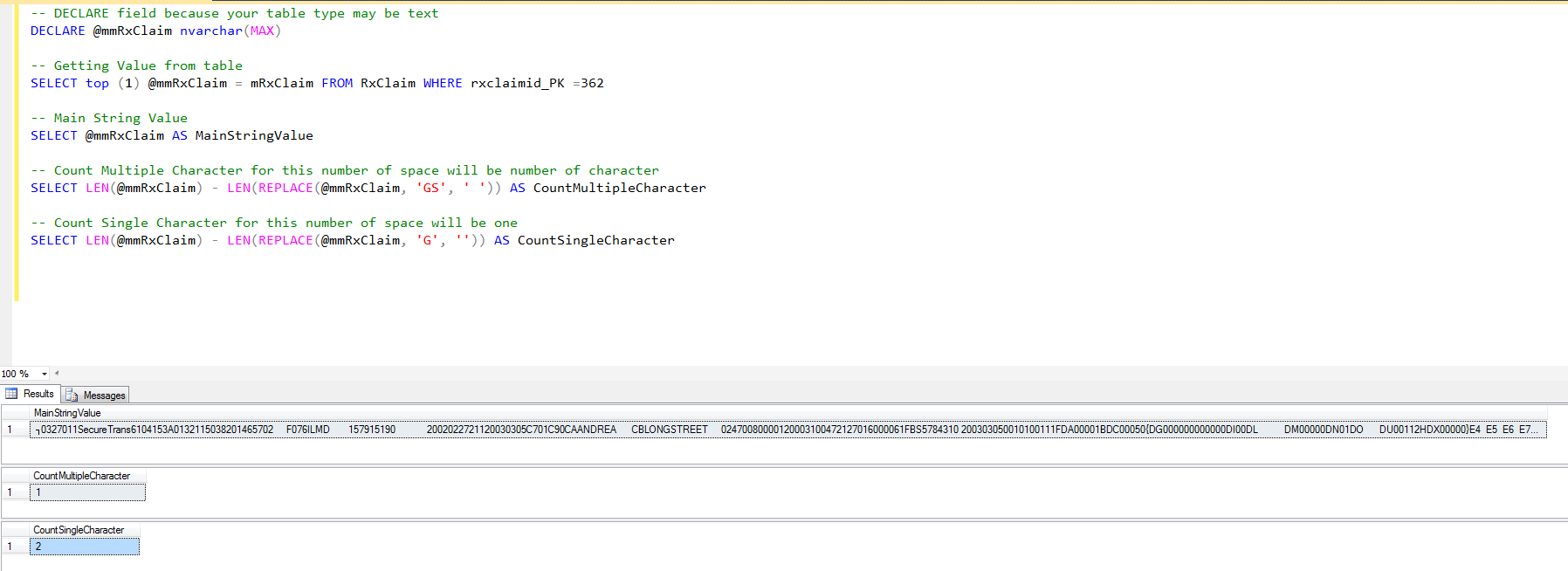
-- DECLARE field because your table type may be text DECLARE @mmRxClaim nvarchar(MAX) -- Getting Value from table SELECT top (1) @mmRxClaim = mRxClaim FROM RxClaim WHERE rxclaimid_PK =362 -- Main String Value SELECT @mmRxClaim AS MainStringValue -- Count Multiple Character for this number of space will be number of character SELECT LEN(@mmRxClaim) - LEN(REPLACE(@mmRxClaim, 'GS', ' ')) AS CountMultipleCharacter -- Count Single Character for this number of space will be one SELECT LEN(@mmRxClaim) - LEN(REPLACE(@mmRxClaim, 'G', '')) AS CountSingleCharacterвыход:
вот, что я использовал в Oracle SQL, чтобы увидеть, если кто-то проходил правильно отформатированный номер телефона:
WHERE REPLACE(TRANSLATE('555-555-1212','0123456789-','00000000000'),'0','') IS NULL AND LENGTH(REPLACE(TRANSLATE('555-555-1212','0123456789','0000000000'),'0','')) = 2первая часть проверяет, имеет ли номер телефона только цифры и дефис, а вторая часть проверяет, что номер телефона имеет только два дефиса.
например, чтобы вычислить количество экземпляров символа (a) в столбце SQL - > имя-это имя столбца "(и в doblequote пусто я заменяю a на nocharecter @")
select len (name) - len(replace(name,'a',")) from TESTING
выберите len ('YYNYNYYNNNYYNY') - len(заменить ('YYNYNYYNNNYYNY', 'y',"))
Comments