Как сделать экспоненциальную и логарифмическую кривую в Python? Я нашел только полиномиальную подгонку
У меня есть набор данных, и я хочу сравнить, какая линия лучше всех это описал (полиномы различных порядков, экспоненциальные или логарифмические).
Я использую Python и Numpy и для полиномиальной подгонки есть функция polyfit(). Но я не нашел таких функций для экспоненциальной и логарифмической подгонки.
есть ли? Или как решить ее иначе?
4 ответов:
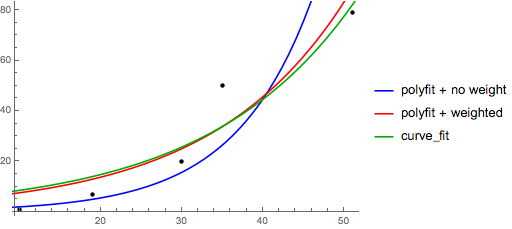
для установки y = A + B log x, просто подходит y против (log x).
>>> x = numpy.array([1, 7, 20, 50, 79]) >>> y = numpy.array([10, 19, 30, 35, 51]) >>> numpy.polyfit(numpy.log(x), y, 1) array([ 8.46295607, 6.61867463]) # y ≈ 8.46 log(x) + 6.62
для установки y = AeBx, возьмите логарифм с обеих сторон дает log y = log A + Bx. Так что fit (log y) в отношении x.
обратите внимание, что фитинг (log y) как бы линейно подчеркнет малые значения y, вызывая большое отклонение для больших y. Это потому что
polyfit(линейная регрессия) работает путем минимизации ∑я (ΔY)2= ∑я (Yя -Ŷя)2. Когда Yя = log yя, остатки ΔYя = Δ (log yя) ≈ Δyя //yя|. Так что даже еслиpolyfitделает очень плохое решение для больших y, - разделить на|/y|" фактор компенсирует это, вызываяpolyfitблаговолит к малым значениям.это может быть облегчено путем придания каждой записи" веса", пропорционального y.
polyfitподдерживает взвешенные наименьшие квадраты черезwключевое слово аргумент.>>> x = numpy.array([10, 19, 30, 35, 51]) >>> y = numpy.array([1, 7, 20, 50, 79]) >>> numpy.polyfit(x, numpy.log(y), 1) array([ 0.10502711, -0.40116352]) # y ≈ exp(-0.401) * exp(0.105 * x) = 0.670 * exp(0.105 * x) # (^ biased towards small values) >>> numpy.polyfit(x, numpy.log(y), 1, w=numpy.sqrt(y)) array([ 0.06009446, 1.41648096]) # y ≈ exp(1.42) * exp(0.0601 * x) = 4.12 * exp(0.0601 * x) # (^ not so biased)обратите внимание, что Excel, LibreOffice и большинство научных калькуляторов обычно используют невзвешенную (смещенную) формулу для линий экспоненциальной регрессии / тренда. если вы хотите, чтобы ваши результаты были совместимы с этими платформами, не включать веса, даже если это обеспечивает лучшие результаты.
теперь, если вы можете использовать scipy, вы можете использовать
scipy.optimize.curve_fitчтобы соответствовать любой модели без преобразований.на y = A + B log x результат такой же, как и метод преобразования:
>>> x = numpy.array([1, 7, 20, 50, 79]) >>> y = numpy.array([10, 19, 30, 35, 51]) >>> scipy.optimize.curve_fit(lambda t,a,b: a+b*numpy.log(t), x, y) (array([ 6.61867467, 8.46295606]), array([[ 28.15948002, -7.89609542], [ -7.89609542, 2.9857172 ]])) # y ≈ 6.62 + 8.46 log(x)на y = AeBx, однако, мы можем получить лучшую подгонку, так как он вычисляет Δ(log y) напрямую. Но нам нужно предоставить инициализировать догадку так
curve_fitможет достигать желаемого локального минимума.>>> x = numpy.array([10, 19, 30, 35, 51]) >>> y = numpy.array([1, 7, 20, 50, 79]) >>> scipy.optimize.curve_fit(lambda t,a,b: a*numpy.exp(b*t), x, y) (array([ 5.60728326e-21, 9.99993501e-01]), array([[ 4.14809412e-27, -1.45078961e-08], [ -1.45078961e-08, 5.07411462e+10]])) # oops, definitely wrong. >>> scipy.optimize.curve_fit(lambda t,a,b: a*numpy.exp(b*t), x, y, p0=(4, 0.1)) (array([ 4.88003249, 0.05531256]), array([[ 1.01261314e+01, -4.31940132e-02], [ -4.31940132e-02, 1.91188656e-04]])) # y ≈ 4.88 exp(0.0553 x). much better.
вы также можете поместить набор данных в любую функцию, которую вам нравится использовать
curve_fitСscipy.optimize. Например, если вы хотите, чтобы соответствовать экспоненциальной функции (с документация):import numpy as np import matplotlib.pyplot as plt from scipy.optimize import curve_fit def func(x, a, b, c): return a * np.exp(-b * x) + c x = np.linspace(0,4,50) y = func(x, 2.5, 1.3, 0.5) yn = y + 0.2*np.random.normal(size=len(x)) popt, pcov = curve_fit(func, x, yn)и тогда, если вы хотите построить сюжет, вы могли бы сделать:
plt.figure() plt.plot(x, yn, 'ko', label="Original Noised Data") plt.plot(x, func(x, *popt), 'r-', label="Fitted Curve") plt.legend() plt.show()(Примечание:
*передpoptкогда вы заговор будет расширять условия вa,bиcэтоfuncждет.)
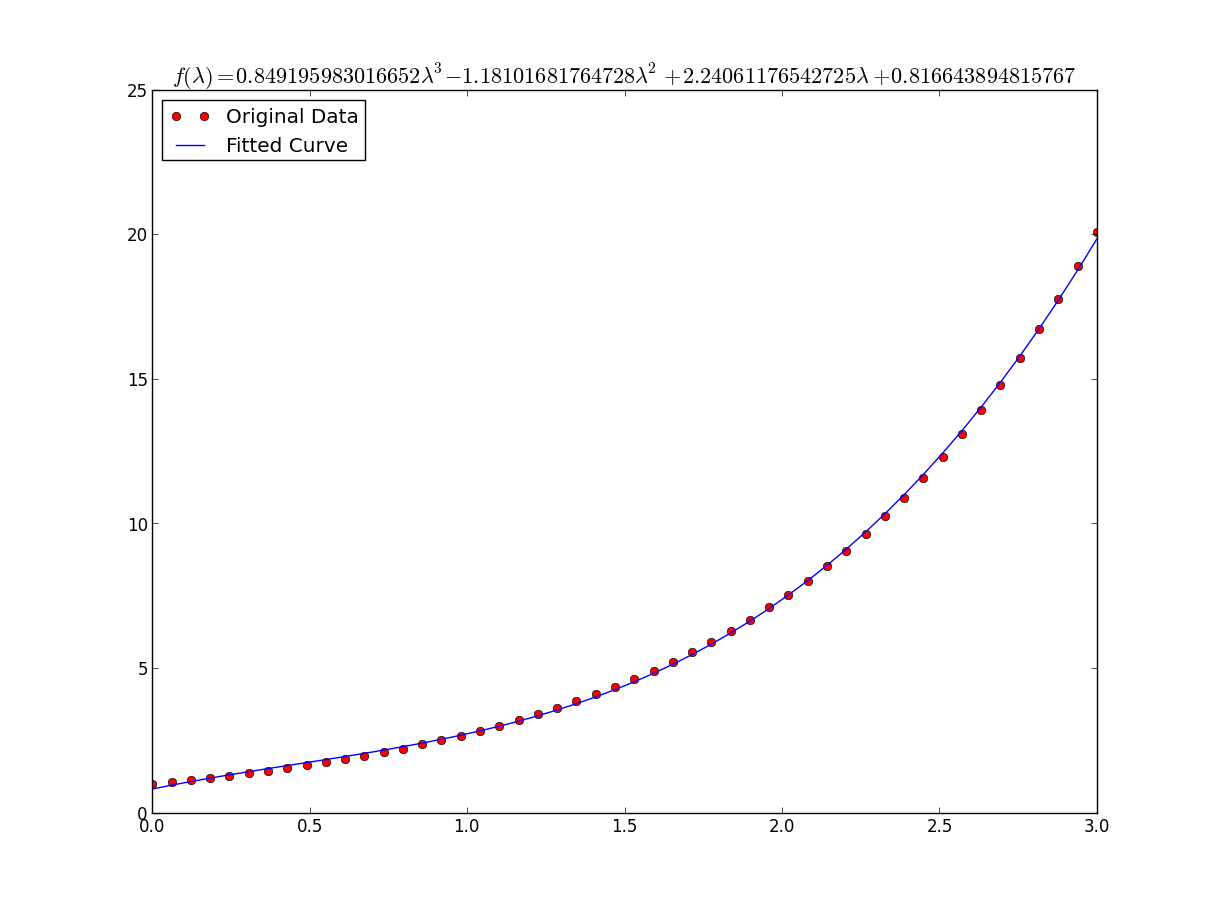
У меня были некоторые проблемы с этим, так что позвольте мне быть очень явным, чтобы нубы, как я могу понять.
предположим, что у нас есть файл данных или что-то подобное
# -*- coding: utf-8 -*- import matplotlib.pyplot as plt from scipy.optimize import curve_fit import numpy as np import sympy as sym """ Generate some data, let's imagine that you already have this. """ x = np.linspace(0, 3, 50) y = np.exp(x) """ Plot your data """ plt.plot(x, y, 'ro',label="Original Data") """ brutal force to avoid errors """ x = np.array(x, dtype=float) #transform your data in a numpy array of floats y = np.array(y, dtype=float) #so the curve_fit can work """ create a function to fit with your data. a, b, c and d are the coefficients that curve_fit will calculate for you. In this part you need to guess and/or use mathematical knowledge to find a function that resembles your data """ def func(x, a, b, c, d): return a*x**3 + b*x**2 +c*x + d """ make the curve_fit """ popt, pcov = curve_fit(func, x, y) """ The result is: popt[0] = a , popt[1] = b, popt[2] = c and popt[3] = d of the function, so f(x) = popt[0]*x**3 + popt[1]*x**2 + popt[2]*x + popt[3]. """ print "a = %s , b = %s, c = %s, d = %s" % (popt[0], popt[1], popt[2], popt[3]) """ Use sympy to generate the latex sintax of the function """ xs = sym.Symbol('\lambda') tex = sym.latex(func(xs,*popt)).replace('$', '') plt.title(r'$f(\lambda)= %s$' %(tex),fontsize=16) """ Print the coefficients and plot the funcion. """ plt.plot(x, func(x, *popt), label="Fitted Curve") #same as line above \/ #plt.plot(x, popt[0]*x**3 + popt[1]*x**2 + popt[2]*x + popt[3], label="Fitted Curve") plt.legend(loc='upper left') plt.show()результат: a = 0.849195983017, b = -1.18101681765, c = 2.24061176543, d = 0.816643894816
Ну, я думаю, вы всегда можете использовать:
np.log --> natural log np.log10 --> base 10 np.log2 --> base 2
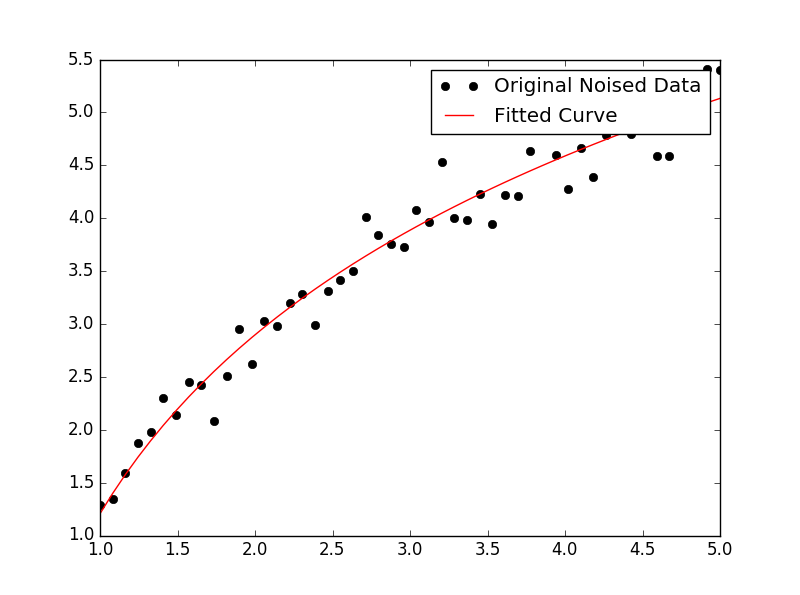
немного изменив ответ IanVS:
import numpy as np import matplotlib.pyplot as plt from scipy.optimize import curve_fit def func(x, a, b, c): #return a * np.exp(-b * x) + c return a * np.log(b * x) + c x = np.linspace(1,5,50) # changed boundary conditions to avoid division by 0 y = func(x, 2.5, 1.3, 0.5) yn = y + 0.2*np.random.normal(size=len(x)) popt, pcov = curve_fit(func, x, yn) plt.figure() plt.plot(x, yn, 'ko', label="Original Noised Data") plt.plot(x, func(x, *popt), 'r-', label="Fitted Curve") plt.legend() plt.show()это приводит к следующим графиком:
Comments