Как найти неиспользуемый / мертвый код в проектах java
какие инструменты вы используете для поиска неиспользуемого / мертвого кода в больших проектах java? Наш продукт находится в разработке в течение нескольких лет, и это становится очень трудно вручную обнаружить код, который больше не используется. Однако мы стараемся удалить как можно больше неиспользуемого кода.
предложения по общим стратегиям / методам (кроме конкретных инструментов) также приветствуются.
Edit: обратите внимание, что мы уже используем инструменты покрытия кода (Clover, IntelliJ), но это мало помогает. Мертвый код по-прежнему имеет модульные тесты и отображается как покрытый. Я думаю, что идеальный инструмент будет идентифицировать кластеры кода, которые имеют очень мало другого кода в зависимости от него, что позволяет проводить ручную проверку документов.
21 ответов:
Я бы прибрал запущенную систему для хранения журналов использования кода, а затем начал проверять код, который не используется в течение нескольких месяцев или лет.
например, если вас интересуют неиспользуемые классы, все классы могут быть инструментированы для регистрации при создании экземпляров. И тогда небольшой скрипт может сравнить эти журналы с полным списком классов, чтобы найти неиспользуемые классы.
конечно, если вы идете на уровне метода, вы должны иметь в виду производительность. Для например, методы могут регистрировать только их первое использование. Я не знаю, как это лучше всего сделать на Java. Мы сделали это в Smalltalk, который является динамическим языком и, таким образом, позволяет изменять код во время выполнения. Мы измеряем все методы с помощью вызова журнала и удаляем код журнала после того, как метод был зарегистрирован в первый раз, таким образом, через некоторое время больше не происходит штрафов за производительность. Возможно, аналогичная вещь может быть сделана в Java со статическими булевыми флагами...
плагин Eclipse, который работает достаточно хорошо, это Детектор Неиспользуемого Кода.
он обрабатывает весь проект или конкретный файл и показывает различные неиспользуемые/мертвые методы кода, а также предлагает изменения видимости (т. е. открытый метод, который может быть защищен или закрыт).
CodePro недавно был выпущен Google с проектом Eclipse. Это бесплатно и очень эффективно. Плагин имеет 'Найти Мертвый Код ' функция с одной / многими точками входа. Работает довольно хорошо.
Я удивлен ProGuard здесь не упоминалось. Это один из самых зрелых продуктов вокруг.
ProGuard Это бесплатный Java класс файл shrinker, оптимизатор, обфускатор, и преверификатор. Он обнаруживает и удаляет неиспользуемые классы, поля, методы и атрибуты. Он оптимизирует байт-код и удаляет неиспользуемые инструкции. Он переименовывает остальные классы, поля и методы используя короткие бессмысленные имена. Наконец, он предварительно проверяет обработанный код для Java 6 или для Java Micro Edition.
некоторые виды использования ProGuard являются:
- создание более компактного кода, для небольших архивов кода, более быстрой передачи по сети, более быстрой загрузки и меньшей памяти следы.
- что делает программы и библиотеки сложнее перепроектировать.
- перечисление мертвого кода, поэтому его можно удалить из исходного кода.
- ретаргетинг и предварительная проверка существующих файлов классов для Java 6 или выше, чтобы в полной мере использовать их более быструю загрузку класса.
одна вещь, которую я, как известно, делаю в Eclipse, в одном классе, - это изменить все свои методы на частные, а затем посмотреть, какие жалобы я получаю. Для методов, которые используются, это вызовет ошибки, и я возвращаю их на самый низкий уровень доступа, который я могу. Для неиспользуемых методов это вызовет предупреждения о неиспользуемых методах, которые затем могут быть удалены. И в качестве бонуса, вы часто найти некоторые общие методы, которые могут и должны быть частными.
но это очень руководство.
мы начали использовать Найти Ошибки чтобы помочь определить некоторые из фанков в целевой среде нашей кодовой базы для рефакторинга. Я бы также рассмотрел структура 101 чтобы определить места в архитектуре вашей кодовой базы, которые слишком сложны, поэтому вы знаете, где находятся настоящие болота.
теоретически, вы не можете детерминированно найти неиспользуемый код. Есть математическое доказательство этого (ну, это частный случай более общей теоремы). Если вам интересно, посмотрите на проблему остановки.
Это может проявляться в Java-коде по-разному:
- загрузка классов на основе пользовательского ввода, конфигурационные файлы, записи базы данных и т. д.;
- загрузки внешнего кода;
- передача деревьев объектов третьим лицам библиотеки;
- etc.
Это, как говорится, я использую IntelliJ идея в качестве интегрированной среды разработки выбор и он имеет обширный инструментарий для анализа зависимостей между модулями findign, неиспользуемые методы, неиспользуемые элементы, неиспользуемые классы и т. д. Его довольно умный тоже как частный метод, который не называется помечен неиспользуемым, но публичный метод требует более обширного анализа.
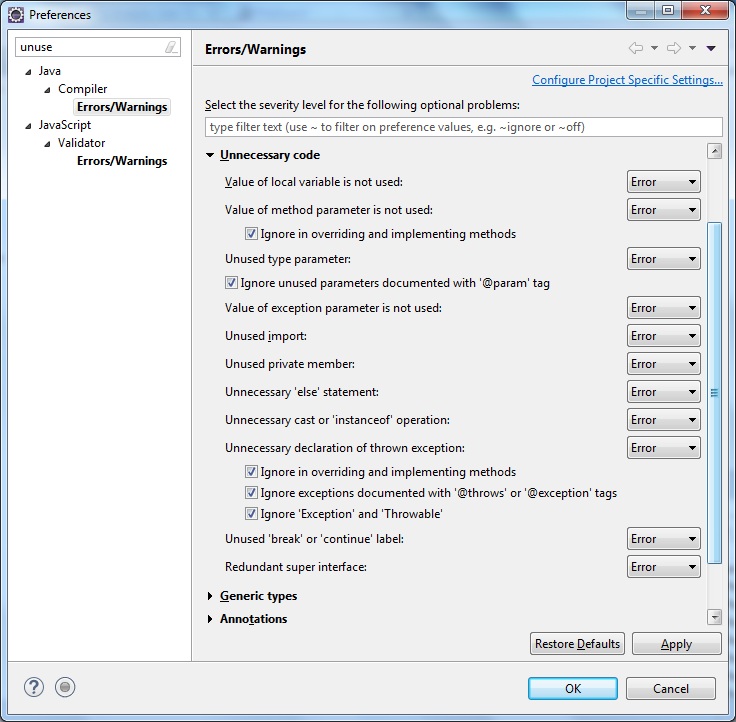
В Eclipse Goto Windows > Настройки > Java > Компилятор > Ошибки / Предупреждения
и изменить все из них на ошибки. Исправьте все ошибки. Это самый простой способ. Красота в том, что это позволит вам очистить код, как вы пишете.Скриншот Eclipse Код:
IntelliJ имеет инструменты анализа кода для обнаружения неиспользуемого кода. Вы должны попытаться сделать как можно больше полей / методов / классов как можно более непубличными, и это покажет больше неиспользуемых методов/полей / классов
Я бы также попытался найти дубликат кода как способ уменьшения объема кода.
мое последнее предложение-попытаться найти открытый исходный код, который при использовании упростит ваш код.
The Structure101 точки зрения фрагмент даст список (и график зависимости) любых "сирот" или "сирота группы " классов или пакетов, не имеющих зависимостей от "основного" кластера.
DCD не является плагином для некоторых IDE, но может быть запущен из ant или автономно. Это выглядит как статический инструмент и он может делать то, что PMD и FindBugs не могут. Я попробую это сделать.
проект С. П. выглядит сейчас мертв. Теперь есть плагин PMD, но я его не использовал.
есть инструменты, которые профилируют код и предоставляют данные покрытия кода. Это позволяет увидеть (как выполняется код), сколько из них вызывается. Вы можете получить любой из этих инструментов, чтобы узнать, сколько сиротского кода у вас есть.
- FindBugs отлично подходит для такого рода вещей.
- PMD (Project Mess Detector) - это еще один инструмент, который можно использовать.
однако, ни один не может найти статические методы, которые не используются в рабочей области. Если кто-нибудь знает о таком инструменте, пожалуйста, дайте мне знать.
инструменты покрытия пользователей, такие как EMMA. Но это не статический инструмент (т. е. он требует фактически запустить приложение через регрессионное тестирование и через все возможные случаи ошибок, что, ну, невозможно :))
тем не менее, Эмма очень полезна.
инструменты покрытия кода, такие как Emma, Cobertura и Clover, будут измерять ваш код и записывать, какие его части вызываются при выполнении набора тестов. Это очень полезно, и должно быть неотъемлемой частью вашего процесса разработки. Это поможет вам определить, насколько хорошо ваш набор тестов охватывает ваш код.
однако это не то же самое, что идентификация реального мертвого кода. Он только идентифицирует код, который покрывается (или не покрывается) тестами. Это может дать вам ложные срабатывания (если ваши тесты не охватывают все сценарии), а также ложные негативы (если ваш тестовый код доступа, который фактически никогда не используется в реальном сценарии).
Я полагаю, что лучший способ действительно идентифицировать мертвый код - это использовать ваш код с помощью инструмента покрытия в живой рабочей среде и анализировать покрытие кода в течение длительного периода времени.
Если вы работаете в избыточной среде с балансировкой нагрузки (а если нет, то почему бы и нет?) тогда я полагаю, что это сделает имеет смысл использовать только один экземпляр приложения и настроить балансировщик нагрузки таким образом, чтобы случайная, но небольшая часть пользователей выполнялась на вашем инструментированном экземпляре. Если вы делаете это в течение длительного периода времени (чтобы убедиться, что вы охватили все сценарии использования в реальном мире - такие сезонные вариации), вы должны быть в состоянии точно видеть, какие области вашего кода доступны при использовании в реальном мире, а какие части действительно никогда не доступны и, следовательно, мертвый код.
Я никогда лично не видел, как это делается, и не знаю, как вышеупомянутые инструменты могут быть использованы для инструмента и анализа кода, который не вызывается через набор тестов - но я уверен, что они могут быть.
есть проект Java -Детектор Мертвого Кода (DCD). Для исходного кода это, кажется, не работает хорошо, но для .jar file-это действительно хорошо. Кроме того, вы можете фильтровать по классу и по методу.
Netbeans вот плагин для Netbeans детектор мертвого кода.
было бы лучше, если бы он мог связать и выделить неиспользуемый код. Вы можете проголосовать и прокомментировать здесь:ошибка 181458-найти неиспользуемые общедоступные классы, методы, поля
Eclipse может показать / выделить код, который не может быть достигнут. JUnit может показать вам покрытие кода, но вам понадобятся некоторые тесты и нужно решить, отсутствует ли соответствующий тест или код действительно не используется.
Я нашел инструмент Clover coverage, который кодирует инструменты и выделяет код, который используется, и который не используется. В отличие от Google CodePro Analytics, он также работает для веб-приложений (согласно моему опыту, и я могу ошибаться в Google CodePro).
единственный недостаток, который я заметил, заключается в том, что он не учитывает интерфейсы Java.
Я использую Doxygen для разработки карты вызова метода, чтобы найти методы, которые никогда не вызываются. На графике вы найдете острова кластеров методов без вызывающих объектов. Это не работает для библиотек, так как вам всегда нужно начинать с некоторой основной точки входа.
Comments