Как реализовать систему тегов
мне было интересно, как лучше всего реализовать систему тегов, как тот, который используется на SO. Я думал об этом, но я не могу придумать хороший масштабируемое решение.
Я думал о том, чтобы иметь базовое 3-х табличное решение: иметь tags таблица, an articles и tag_to_articles таблица.
- это наилучшее решение этой проблемы, или есть альтернативы? Используя этот метод таблица будет получить чрезвычайно большой во времени, и для поиска это не слишком эффективно, я полагаю. С другой стороны, это не так важно, что запрос выполняется быстро.
7 ответов:
Я считаю, что вы найдете интересным это сообщение в блоге:Теги: схемы баз данных
проблема: вы хотите иметь схему базы данных, где вы можете пометить закладка (или сообщение в блоге или что-то еще) с таким количеством тегов, как вы хотите. Затем вы хотите запустить запросы, чтобы ограничить закладки объединение или пересечение тегов. Вы также хотите исключить (скажем: минус) некоторые теги из результатов поиска.
" MySQLicious" решение
в этом решении схема имеет только одну таблицу, она денормализована. Этот тип называется "MySQLicious solution", потому что MySQLicious импортирует del.icio.us данные в таблицу с этой структурой.
пересечение (и) Запрос на "search+webservice+semweb":
SELECT * FROM `delicious` WHERE tags LIKE "%search%" AND tags LIKE "%webservice%" AND tags LIKE "%semweb%"Союз (или) Запрос на "search|webservice / semweb":
SELECT * FROM `delicious` WHERE tags LIKE "%search%" OR tags LIKE "%webservice%" OR tags LIKE "%semweb%"минус Запрос для "search+webservice-semweb"
SELECT * FROM `delicious` WHERE tags LIKE "%search%" AND tags LIKE "%webservice%" AND tags NOT LIKE "%semweb%"
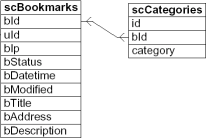
решение "Scuttle"
Scuttle организует свои данные в двух таблицах. Эта таблица " scCategories "является таблицей"tag "и имеет внешний ключ к таблице"bookmark".
пересечение (и) Запрос на "bookmark+webservice+semweb":
SELECT b.* FROM scBookmarks b, scCategories c WHERE c.bId = b.bId AND (c.category IN ('bookmark', 'webservice', 'semweb')) GROUP BY b.bId HAVING COUNT( b.bId )=3во-первых, все комбинации закладок-тегов ищутся, где находится тег "закладка", "вебсервис" или "semweb" (С. категория В ('закладки', 'веб-сервис', 'semweb')), то просто закладки, которые получили все три теги искали учитываются (имея граф(род.ставка)=3).
Союз (или) Запрос на "bookmark / webservice / semweb": Просто оставьте предложение HAVING, и у вас есть союз:
SELECT b.* FROM scBookmarks b, scCategories c WHERE c.bId = b.bId AND (c.category IN ('bookmark', 'webservice', 'semweb')) GROUP BY b.bIdМинус (Исключение) Запрос на "bookmark+webservice-semweb", то есть: bookmark и webservice а не семантический веб.
SELECT b. * FROM scBookmarks b, scCategories c WHERE b.bId = c.bId AND (c.category IN ('bookmark', 'webservice')) AND b.bId NOT IN (SELECT b.bId FROM scBookmarks b, scCategories c WHERE b.bId = c.bId AND c.category = 'semweb') GROUP BY b.bId HAVING COUNT( b.bId ) =2оставляя счет наличия приводит к запросу для "bookmark / webservice-semweb".
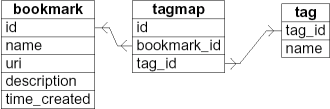
решение"Toxi"
Toxi придумал структуру из трех таблиц. Через таблицу "tagmap" закладки и теги связаны n-к-M. Каждый тег может использоваться вместе с различными закладками и наоборот. Эта DB-схема также используется wordpress. Запросы совершенно такие же, как и в "сорвать" решение.
пересечение (и) Запрос на "bookmark+webservice+semweb"
SELECT b.* FROM tagmap bt, bookmark b, tag t WHERE bt.tag_id = t.tag_id AND (t.name IN ('bookmark', 'webservice', 'semweb')) AND b.id = bt.bookmark_id GROUP BY b.id HAVING COUNT( b.id )=3Союз (или) Запрос на "bookmark / webservice / semweb"
SELECT b.* FROM tagmap bt, bookmark b, tag t WHERE bt.tag_id = t.tag_id AND (t.name IN ('bookmark', 'webservice', 'semweb')) AND b.id = bt.bookmark_id GROUP BY b.idМинус (Исключение) Запрос для "bookmark+webservice-semweb", то есть: bookmark и webservice, а не semweb.
SELECT b. * FROM bookmark b, tagmap bt, tag t WHERE b.id = bt.bookmark_id AND bt.tag_id = t.tag_id AND (t.name IN ('Programming', 'Algorithms')) AND b.id NOT IN (SELECT b.id FROM bookmark b, tagmap bt, tag t WHERE b.id = bt.bookmark_id AND bt.tag_id = t.tag_id AND t.name = 'Python') GROUP BY b.id HAVING COUNT( b.id ) =2оставляя счет наличия приводит к запросу для "закладка / webservice-semweb".


ничего плохого в вашем решении с тремя таблицами.
другой вариант-ограничить количество тегов, которые могут быть применены к статье (например, 5 в SO), и добавить их непосредственно в таблицу статей.
нормализация БД имеет свои преимущества и недостатки, так же, как жесткая проводка вещей в одну таблицу имеет преимущества и недостатки.
ничто не говорит, что вы не можете сделать оба. Это противоречит парадигмам реляционной БД для повторения информации, но если цель-производительность возможно, вам придется сломать парадигмы.
предложенная реализация трех таблиц будет работать для пометки.
переполнение стека использует, однако, другая реализация. Они хранят теги в столбце varchar в таблице posts в виде обычного текста и используют полнотекстовое индексирование для извлечения сообщений, соответствующих тегам. Например
posts.tags = "algorithm system tagging best-practices". Я уверен, что Джефф упоминал об этом где-то, но я забыл, где.
предлагаемое решение является лучшим-если не единственным практически возможным - способом, который я могу придумать, чтобы решить отношения "многие ко многим" между тегами и статьями. Поэтому я голосую за " да, это все еще лучший.- Но меня интересуют любые альтернативы.
Я хотел бы предложить оптимизированный MySQLicious для лучшей производительности. До этого недостатки решения Toxi (3 табл.) были
если у вас есть миллионы вопросов, и он имеет 5 тегов в каждом, ТО будет 5 миллионов записей в таблице tagmap. Поэтому сначала мы должны отфильтровать 10 тысяч записей tagmap на основе поиска тегов, а затем снова отфильтровать соответствующие вопросы из этих 10 тысяч. Поэтому при фильтрации, если артикулярный идентификатор является простым числовым, то это нормально, но если это так вид UUID (32 varchar) затем отфильтровывается требует большего сравнения, хотя он индексируется.
мое решение:
всякий раз, когда создается новый тег, имейте счетчик++ (base 10) и преобразуйте этот счетчик в base64. Теперь каждое имя тега будет иметь код в base64. и передайте этот идентификатор в пользовательский интерфейс вместе с именем. Таким образом, у вас будет максимум два идентификатора char, пока у нас не будет 4095 тегов, созданных в нашей системе. Теперь объедините эти несколько тегов в каждый столбец тега таблицы вопросов. Добавить разделитель как ну и сделать его сортируют.
так таблица выглядит так
при запросе, запрос на ID вместо имени тега. Так как это сортировка,
andсостояние на теге будет более эффективным (LIKE '%|a|%|c|%|f|%).обратите внимание, что одного разделителя пространства недостаточно, и нам нужен двойной разделитель, чтобы различать теги, такие как
sqlиmysql, потому чтоLIKE "%sql%"вернутсяmysqlрезультаты так же. Должно бытьLIKE "%|sql|%"Я знаю, что поиск не индексируется, но все же вы могли бы проиндексировать другие столбцы, связанные со статьей, такой как author/dateTime else, приведет к полному сканированию таблицы.
наконец, с помощью этого решения не требуется внутреннее соединение, где миллионы записей должны сравниваться с 5 миллионами записей при условии соединения.

Если ваша база данных поддерживает индексируемые массивы (например, PostgreSQL), я бы рекомендовал полностью денормализованное решение - хранить теги в виде массива строк в одной таблице. Если нет, то вторичная таблица сопоставления объектов с тегами является лучшим решением. Если вам нужно хранить дополнительную информацию о тегах, вы можете использовать отдельную таблицу тегов, но нет смысла вводить второе соединение для каждого поиска тегов.
CREATE TABLE Tags ( tag VARHAR(...) NOT NULL, bid INT ... NOT NULL, PRIMARY KEY(tag, bid), INDEX(bid, tag) )Примечания:
- это лучше, чем TOXI в том, что он не проходит через дополнительную таблицу many:many, что затрудняет оптимизацию.
- конечно, мой подход может быть немного более громоздким (чем TOXI) из-за избыточных тегов, но это небольшой процент весь база данных, и улучшения производительности могут быть значительными.
- он очень масштабируемый.
- он не имеет (потому что он не нужен) a суррогат
AUTO_INCREMENTPK. Следовательно, это лучше, чем сорвать.- MySQLicious отстой, потому что он не может использовать индекс (
LIKEС ведущий wild card; ложные хиты на подстроках)- для MySQL обязательно используйте ENGINE=InnoDB для получения эффектов "кластеризации".
связанные обсуждения (для MySQL):
многие: многие оптимизации таблицы отображения
упорядоченные списки
Comments