Как перебирать строки в фрейме данных в панд?
у меня есть DataFrame от Панды:
import pandas as pd
inp = [{'c1':10, 'c2':100}, {'c1':11,'c2':110}, {'c1':12,'c2':120}]
df = pd.DataFrame(inp)
print df
выход:
c1 c2
0 10 100
1 11 110
2 12 120
теперь я хочу перебрать строки этого кадра. Для каждой строки Я хочу иметь доступ к ее элементам (значения в ячейках) по имени столбцов. Например:
for row in df.rows:
print row['c1'], row['c2']
можно ли это сделать у панд?
Я нашел это аналогичный вопрос. Но это не дает мне ответа, в котором я нуждаюсь. Например, там предлагается: использование:
for date, row in df.T.iteritems():
или
for row in df.iterrows():
но я не понимаю, что такое row объект есть и как я могу с ним работать.
14 ответов:
iterrows это генератор, который дает как индекс, так и строку
for index, row in df.iterrows(): print row['c1'], row['c2'] Output: 10 100 11 110 12 120
для перебора строки DataFrame в pandas можно использовать:
for index, row in df.iterrows(): print row["c1"], row["c2"]for row in df.itertuples(index=True, name='Pandas'): print getattr(row, "c1"), getattr(row, "c2")
itertuples()должен быть быстрее, чемiterrows()но имейте в виду, по документам (панды 0.21.1 на данный момент):
iterrows:
dtypeможет не совпадать из строки в строку строкипотому что iterrows возвращает ряд для каждой строки, это не сохраняет dtypes в строках (dtypes сохраняются в Столбцах для фреймов данных).
iterrows: не изменять строки
вы должны никогда не изменяйте то,что вы повторяете. Это не гарантирует работу во всех случаях. В зависимости от типов данных, итератор возвращает копию, а не смотреть, и письма к нему не будет иметь никакого эффекта.
использовать таблицы данных.применить() вместо:
new_df = df.apply(lambda x: x * 2)itertuples:
имена столбцов будут переименованы в позиционные имена, если они являются недопустимыми идентификаторами Python, повторяются или начинаются с подчеркивания. При большом количестве столбцов (>255) возвращаются обычные кортежи.
пока
iterrows()это хороший вариант, иногдаitertuples()может быть намного быстрее:df = pd.DataFrame({'a': randn(1000), 'b': randn(1000),'N': randint(100, 1000, (1000)), 'x': 'x'}) %timeit [row.a * 2 for idx, row in df.iterrows()] # => 10 loops, best of 3: 50.3 ms per loop %timeit [row[1] * 2 for row in df.itertuples()] # => 1000 loops, best of 3: 541 µs per loop
вы также можете использовать
df.apply()для итерации по строкам и доступа к нескольким столбцам для функции.def valuation_formula(x, y): return x * y * 0.5 df['price'] = df.apply(lambda row: valuation_formula(row['x'], row['y']), axis=1)
вы можете использовать df.функция iloc выглядит следующим образом:
for i in range(0, len(df)): print df.iloc[i]['c1'], df.iloc[i]['c2']
искал как перебирать по строкам и столбцам и заканчивалось вот так:
for i, row in df.iterrows(): for j, column in row.iteritems(): print(column)
использовать itertuples(). Это быстрее, чем iterrows():
for row in df.itertuples(): print "c1 :",row.c1,"c2 :",row.c2
в цикле все строки
dataframeвы можете использовать:for x in range(len(date_example.index)): print date_example['Date'].iloc[x]
вы можете написать свой собственный итератор, реализующий
namedtuplefrom collections import namedtuple def myiter(d, cols=None): if cols is None: v = d.values.tolist() cols = d.columns.values.tolist() else: j = [d.columns.get_loc(c) for c in cols] v = d.values[:, j].tolist() n = namedtuple('MyTuple', cols) for line in iter(v): yield n(*line)это прямо сопоставимо с
pd.DataFrame.itertuples. Я стремлюсь выполнять ту же задачу с большей эффективностью.
для данного фрейма данных с моей функцией:
list(myiter(df)) [MyTuple(c1=10, c2=100), MyTuple(c1=11, c2=110), MyTuple(c1=12, c2=120)]или
pd.DataFrame.itertuples:list(df.itertuples(index=False)) [Pandas(c1=10, c2=100), Pandas(c1=11, c2=110), Pandas(c1=12, c2=120)]
комплексный тест
Мы тестируем доступность всех столбцов и их подмножество.def iterfullA(d): return list(myiter(d)) def iterfullB(d): return list(d.itertuples(index=False)) def itersubA(d): return list(myiter(d, ['col3', 'col4', 'col5', 'col6', 'col7'])) def itersubB(d): return list(d[['col3', 'col4', 'col5', 'col6', 'col7']].itertuples(index=False)) res = pd.DataFrame( index=[10, 30, 100, 300, 1000, 3000, 10000, 30000], columns='iterfullA iterfullB itersubA itersubB'.split(), dtype=float ) for i in res.index: d = pd.DataFrame(np.random.randint(10, size=(i, 10))).add_prefix('col') for j in res.columns: stmt = '{}(d)'.format(j) setp = 'from __main__ import d, {}'.format(j) res.at[i, j] = timeit(stmt, setp, number=100) res.groupby(res.columns.str[4:-1], axis=1).plot(loglog=True);
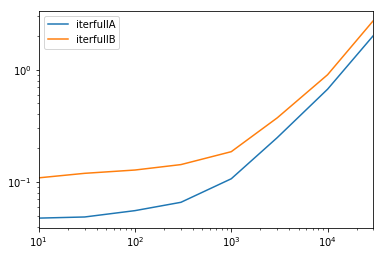
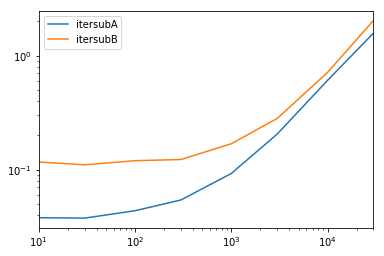
в цикле все строки
dataframeи использовать значения каждой строки удобно,namedtuplesможно преобразовать вndarrayы. Например:df = pd.DataFrame({'col1': [1, 2], 'col2': [0.1, 0.2]}, index=['a', 'b'])итерация по строкам:
for row in df.itertuples(index=False, name='Pandas'): print np.asarray(row)результаты:
[ 1. 0.1] [ 2. 0.2]обратите внимание, что если
index=True,индекс добавляется в качестве первого элемента кортежа, который может быть нежелательным для некоторых приложений.
добавление к ответам выше, иногда полезным шаблоном является:
# Borrowing @KutalmisB df example df = pd.DataFrame({'col1': [1, 2], 'col2': [0.1, 0.2]}, index=['a', 'b']) # The to_dict call results in a list of dicts # where each row_dict is a dictionary with k:v pairs of columns:value for that row for row_dict in df.to_dict(orient='records'): print(row_dict)что приводит к:
{'col1':1.0, 'col2':0.1} {'col1':2.0, 'col2':0.2}
зачем все усложнять?
простой.
import pandas as pd import numpy as np # Here is an example dataframe df_existing = pd.DataFrame(np.random.randint(0,100,size=(100, 4)), columns=list('ABCD')) for idx,row in df_existing.iterrows(): print row['A'],row['B'],row['C'],row['D']
вы также можете сделать
numpyиндексирование для еще большей скорости ИБП. На самом деле это не итерация, но работает намного лучше, чем итерация для некоторых приложений.subset = row['c1'][0:5] all = row['c1'][:]вы также можете привести его к массиву. Эти индексы / выборки должны действовать как массивы Numpy уже, но я столкнулся с проблемами и должен был бросить
np.asarray(all) imgs[:] = cv2.resize(imgs[:], (224,224) ) #resize every image in an hdf5 file
Comments