7 ответов:
ToUpperиспользует текущий язык и региональные параметры.ToUpperInvariantиспользует инвариант культуры.каноническим примером является Турция, где верхний регистр "я" не является "я".
пример кода, показывающий разницу:
using System; using System.Drawing; using System.Globalization; using System.Threading; using System.Windows.Forms; public class Test { [STAThread] static void Main() { string invariant = "iii".ToUpperInvariant(); CultureInfo turkey = new CultureInfo("tr-TR"); Thread.CurrentThread.CurrentCulture = turkey; string cultured = "iii".ToUpper(); Font bigFont = new Font("Arial", 40); Form f = new Form { Controls = { new Label { Text = invariant, Location = new Point(20, 20), Font = bigFont, AutoSize = true}, new Label { Text = cultured, Location = new Point(20, 100), Font = bigFont, AutoSize = true } } }; Application.Run(f); } }для получения дополнительной информации на турецком языке, смотрите это Турция тест блог пост.
Я бы не удивился, услышав, что существуют различные другие проблемы капитализации вокруг elided символов и т. д. Это всего лишь один пример, который я знаю с самого начала моя голова... отчасти потому, что он укусил меня много лет назад на Java, где я был верхним корпусом строки и сравнивал ее с "почтой". Это не так хорошо работает в Турции...
ответ Джона идеален. Я просто хотел добавить, что
ToUpperInvariantэто то же самое, что вызовToUpper(CultureInfo.InvariantCulture).это делает пример Джона немного проще:
using System; using System.Drawing; using System.Globalization; using System.Threading; using System.Windows.Forms; public class Test { [STAThread] static void Main() { string invariant = "iii".ToUpper(CultureInfo.InvariantCulture); string cultured = "iii".ToUpper(new CultureInfo("tr-TR")); Application.Run(new Form { Font = new Font("Times New Roman", 40), Controls = { new Label { Text = invariant, Location = new Point(20, 20), AutoSize = true }, new Label { Text = cultured, Location = new Point(20, 100), AutoSize = true }, } }); } }Я тоже New Times Roman потому что это более крутой шрифт.
Я тоже поставил
Form' sFontсвойство вместо двухLabelэлементы управления, потому чтоFontсвойство передается по наследству.и я уменьшил несколько других строк только потому, что мне нравится компактный (например, не рабочий код.
Я не имел ничего лучше, чтобы сделать в данный момент.
начните с MSDN
http://msdn.microsoft.com/en-us/library/system.string.toupperinvariant.aspx
метод ToUpperInvariant эквивалентный ToUpper(Свойство CultureInfo.Инвариантная культура)
просто потому, что капитал Я и "Я" на английском языке, не всегда делает это так.
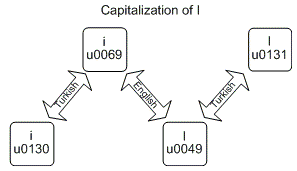
String.ToUpperиString.ToLowerможет дать различные результаты, учитывая различные культуры. Самый известный пример:турецкий, для которого преобразование строчного латинского " i "в верхний регистр, не приводит к заглавной латинской" I", но в турецком"I".
Что касается меня, то это сбивало с толку даже с приведенной выше картинкой (источник), Я написал программу (см. исходный код ниже), чтобы увидеть точный вывод для турецкого языка пример:
# Lowercase letters Character | UpperInvariant | UpperTurkish | LowerInvariant | LowerTurkish English i - i (\u0069) | I (\u0049) | I (\u0130) | i (\u0069) | i (\u0069) Turkish i - ı (\u0131) | ı (\u0131) | I (\u0049) | ı (\u0131) | ı (\u0131) # Uppercase letters Character | UpperInvariant | UpperTurkish | LowerInvariant | LowerTurkish English i - I (\u0049) | I (\u0049) | I (\u0049) | i (\u0069) | ı (\u0131) Turkish i - I (\u0130) | I (\u0130) | I (\u0130) | I (\u0130) | i (\u0069)Как видите:
- прописные буквы нижнего регистра и строчные буквы верхнего регистра дают разные результаты для инвариантной культуры и турецкой культуры.
- прописные буквы верхнего регистра и строчные буквы нижнего регистра не имеют никакого эффекта, независимо от того, что такое культура.
Culture.CultureInvariantоставляет турецкие символы как естьToUpperиToLowerявляются обратимыми, то есть строчные символы после заглавной буквы он возвращает его в исходную форму, если для обеих операций использовалась одна и та же культура.по данным MSDN, для Char.Топпер и чар.Тольяттинский и азербайджанский языки являются единственными пострадавшими культурами, потому что они единственные с односимвольными различиями. Для строк может быть затронуто больше культур.
исходный код консольного приложения, используемого для создания вывода:
using System; using System.Globalization; using System.Linq; using System.Text; namespace TurkishI { class Program { static void Main(string[] args) { var englishI = new UnicodeCharacter('\u0069', "English i"); var turkishI = new UnicodeCharacter('\u0131', "Turkish i"); Console.WriteLine("# Lowercase letters"); Console.WriteLine("Character | UpperInvariant | UpperTurkish | LowerInvariant | LowerTurkish"); WriteUpperToConsole(englishI); WriteLowerToConsole(turkishI); Console.WriteLine("\n# Uppercase letters"); var uppercaseEnglishI = new UnicodeCharacter('\u0049', "English i"); var uppercaseTurkishI = new UnicodeCharacter('\u0130', "Turkish i"); Console.WriteLine("Character | UpperInvariant | UpperTurkish | LowerInvariant | LowerTurkish"); WriteLowerToConsole(uppercaseEnglishI); WriteLowerToConsole(uppercaseTurkishI); Console.ReadKey(); } static void WriteUpperToConsole(UnicodeCharacter character) { Console.WriteLine("{0,-9} - {1,10} | {2,-14} | {3,-12} | {4,-14} | {5,-12}", character.Description, character, character.UpperInvariant, character.UpperTurkish, character.LowerInvariant, character.LowerTurkish ); } static void WriteLowerToConsole(UnicodeCharacter character) { Console.WriteLine("{0,-9} - {1,10} | {2,-14} | {3,-12} | {4,-14} | {5,-12}", character.Description, character, character.UpperInvariant, character.UpperTurkish, character.LowerInvariant, character.LowerTurkish ); } } class UnicodeCharacter { public static readonly CultureInfo TurkishCulture = new CultureInfo("tr-TR"); public char Character { get; } public string Description { get; } public UnicodeCharacter(char character) : this(character, string.Empty) { } public UnicodeCharacter(char character, string description) { if (description == null) { throw new ArgumentNullException(nameof(description)); } Character = character; Description = description; } public string EscapeSequence => ToUnicodeEscapeSequence(Character); public UnicodeCharacter LowerInvariant => new UnicodeCharacter(Char.ToLowerInvariant(Character)); public UnicodeCharacter UpperInvariant => new UnicodeCharacter(Char.ToUpperInvariant(Character)); public UnicodeCharacter LowerTurkish => new UnicodeCharacter(Char.ToLower(Character, TurkishCulture)); public UnicodeCharacter UpperTurkish => new UnicodeCharacter(Char.ToUpper(Character, TurkishCulture)); private static string ToUnicodeEscapeSequence(char character) { var bytes = Encoding.Unicode.GetBytes(new[] {character}); var prefix = bytes.Length == 4 ? @"\U" : @"\u"; var hex = BitConverter.ToString(bytes.Reverse().ToArray()).Replace("-", string.Empty); return $"{prefix}{hex}"; } public override string ToString() { return $"{Character} ({EscapeSequence})"; } } }
http://msdn.microsoft.com/en-us/library/system.string.toupperinvariant.aspx
документация Microsoft объясняет различия и дает примеры различных результатов.
ToUpperInvariant использует правила из инвариантного
Comments