Использование логического индексирования для многозначных строк и столбцов в Pandas
Вопросы в конце, вжирным шрифтом . Но сначала давайте установим некоторые данные:
import numpy as np
import pandas as pd
from itertools import product
np.random.seed(1)
team_names = ['Yankees', 'Mets', 'Dodgers']
jersey_numbers = [35, 71, 84]
game_numbers = [1, 2]
observer_names = ['Bill', 'John', 'Ralph']
observation_types = ['Speed', 'Strength']
row_indices = list(product(team_names, jersey_numbers, game_numbers, observer_names, observation_types))
observation_values = np.random.randn(len(row_indices))
tns, jns, gns, ons, ots = zip(*row_indices)
data = pd.DataFrame({'team': tns, 'jersey': jns, 'game': gns, 'observer': ons, 'obstype': ots, 'value': observation_values})
data = data.set_index(['team', 'jersey', 'game', 'observer', 'obstype'])
data = data.unstack(['observer', 'obstype'])
data.columns = data.columns.droplevel(0)
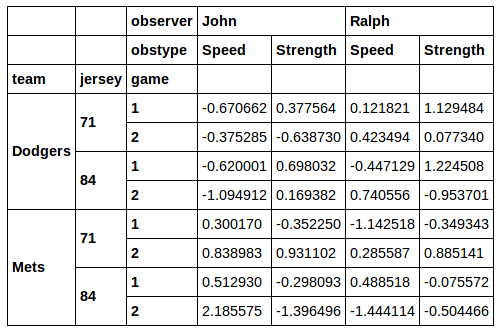
Это дает:
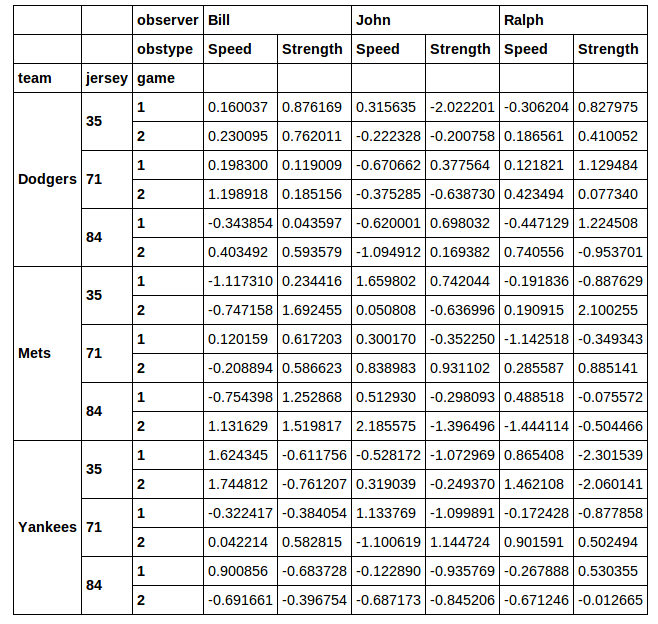
Я хочу выделить подмножество этого фрейма данных для последующего анализа. Допустим, я хочу вырезать строки, в которых число
jersey равно 71. Мне не очень нравится идея использовать xs для этого. Когда вы делаете поперечное сечение через xs, вы теряете столбец, который вы выбрали. Если я побегу: data.xs(71, axis=0, level='jersey')
Затем я возвращаю правильные строки, но теряю Колонка jersey.
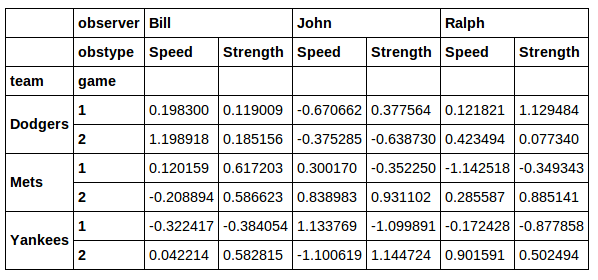
Кроме того, xs не кажется отличным решением для случая, когда мне нужно несколько разных значений из столбца jersey. Я думаю, что гораздо более хорошее решение-это то, которое найдено здесь :
data[[j in [71, 84] for t, j, g in data.index]]
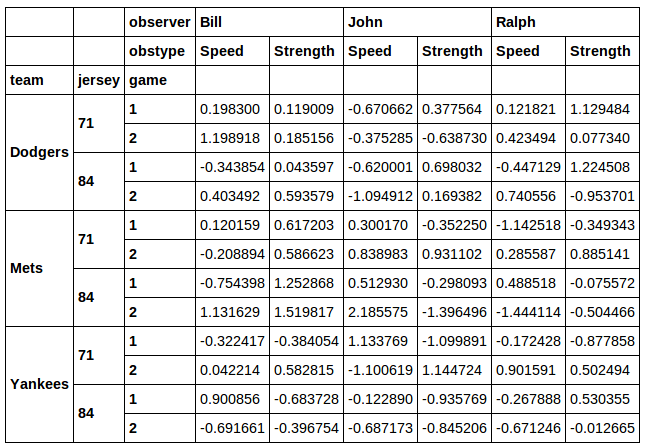
Можно даже отфильтровать комбинацию свитеров и команд:
data[[j in [71, 84] and t in ['Dodgers', 'Mets'] for t, j, g in data.index]]
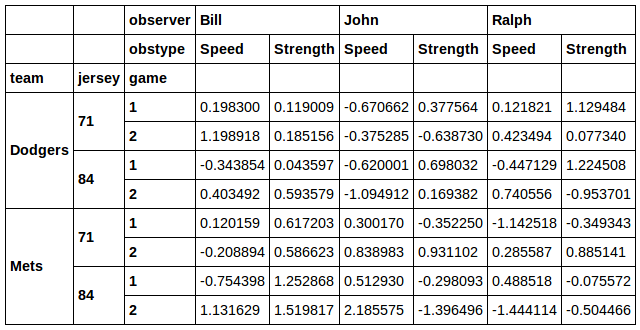
Здорово!
Итак, вопрос: как я могу сделать что-то подобное для выбора подмножества столбцов. для например, скажем, мне нужны только столбцы, представляющие данные от Ральфа. Как я могу сделать это без использования xs? Или что, если мне нужны только столбцы с observer in ['John', 'Ralph']? Опять же, я бы предпочел решение, которое сохраняет все уровни индексов строк и столбцов в результате...как и в приведенных выше примерах логического индексирования.
Я могу делать все, что захочу, и даже комбинировать выборки из индексов строк и столбцов. Но единственное решение, которое я нашел, включает в себя некоторые реальные гимнастика:
data[[j in [71, 84] and t in ['Dodgers', 'Mets'] for t, j, g in data.index]]
.T[[obs in ['John', 'Ralph'] for obs, obstype in data.columns]].T
И, таким образом, второй вопрос: есть ли более компактный способ сделать то, что я только что сделал выше?
4 ответов:
Как панд 0.18 (возможно и раньше) вы легко можете нарезать мульти-индексированных таблиц данных с помощью др.IndexSlice .
Для вашего конкретного вопроса Вы можете использовать следующее, Чтобы выбрать команду, Джерси и игру:
data.loc[pd.IndexSlice[:,[71, 84],:],:] #IndexSlice on the rowsIndexSlice нужно только достаточно информации об уровне, чтобы быть однозначным, так что вы можете удалить завершающий двоеточие:
data.loc[pd.IndexSlice[:,[71, 84]],:]Аналогично, вы можете индексировать Slice по столбцам:
data.loc[pd.IndexSlice[:,[71, 84]],pd.IndexSlice[['John', 'Ralph']]]Что дает вам окончательный фрейм данных в вашем вопросе.
Вот один подход, который использует немного более встроенный синтаксис чувства. Но он все равно чертовски неуклюж:
data.loc[ (data.index.get_level_values('jersey').isin([71, 84]) & data.index.get_level_values('team').isin(['Dodgers', 'Mets'])), data.columns.get_level_values('observer').isin(['John', 'Ralph']) ]Итак, сравнение:
def hackedsyntax(): return data[[j in [71, 84] and t in ['Dodgers', 'Mets'] for t, j, g in data.index]]\ .T[[obs in ['John', 'Ralph'] for obs, obstype in data.columns]].T def uglybuiltinsyntax(): return data.loc[ (data.index.get_level_values('jersey').isin([71, 84]) & data.index.get_level_values('team').isin(['Dodgers', 'Mets'])), data.columns.get_level_values('observer').isin(['John', 'Ralph']) ] %timeit hackedsyntax() %timeit uglybuiltinsyntax() hackedsyntax() - uglybuiltinsyntax()Результаты:
1000 loops, best of 3: 395 µs per loop 1000 loops, best of 3: 409 µs per loopВсе еще надеюсь, что есть более чистый или более канонический способ сделать это.
Примечание: начиная с Pandas v0. 20,
ixaccessor был устаревшим; используйтеlocилиilocвместо этого, если это уместно.Если я правильно понял вопрос, это довольно просто:
Чтобы получить колонку для Ральфа:
data.ix[:,"Ralph"]Чтобы получить его для двух из них, передайте в списке:
data.ix[:,["Ralph","John"]]Оператор іх оператор индексирования власти. Помните, что первый аргумент-это строки, а затем столбцы (в отличие от данных[..][..] то есть наоборот). Двоеточие действует как подстановочный знак, поэтому возвращает все строки в axis=0.
В общем, чтобы сделать поиск в Мультииндексе, вы должны пройти в кортеж. например
Но если вы просто передадите один элемент, он будет рассматривать это так, как если бы вы передали первый элемент кортежа, а затем подстановочный знак.data.[:,("Ralph","Speed")]Где это становится сложным, если вы хотите получить доступ к столбцам, которые не являются индексами уровня 0. Например, получить все столбцы для "скорости". Тогда вам нужно будет стать немного более творческим.. Используйте
get_level_valuesметод индекса / столбца в сочетании с булевым индексированием:Например, это получает Джерси 71 в строках, и
strengthв Столбцах:data.ix[data.index.get_level_values("jersey") == 71 , \ data.columns.get_level_values("obstype") == "Strength"]
Обратите внимание, что из того, что я понимаю,
selectмедленно. Но другой подход здесь был бы:
data.select(lambda col: col[0] in ['John', 'Ralph'], axis=1)Вы также можете связать это с выбором по строкам:
Большим недостатком здесь является то, что вы должны знать номер уровня индекса.data.select(lambda col: col[0] in ['John', 'Ralph'], axis=1) \ .select(lambda row: row[1] in [71, 84] and row[2] > 1, axis=0)
Comments