Как найти стандартное отклонение в столбце В RDD в PySpark
У меня есть RDD, и я хочу найти standard deviation в данных, которые являются одним из столбцов RDD. Мой текущий код:
def extract(line):
# line[11] is the column in which I want to find standard deviation
return (line[1],line[2],line[5],line[6],line[8],line[10],line[11])
inputfile1 = sc.textFile('file1.csv').zipWithIndex().filter(lambda (line,rownum): rownum>=0).map(lambda (line, rownum): line)
data = (inputfile1
.map(lambda line: line.split(";"))
.filter(lambda line: len(line) >1 )
.map(extract)) # Map to tuples
data является RDD, в котором я последний столбец (столбец 6) имеет значения, среди которых я хочу найти standard deviation. Как мне его найти?
UPDATE : мой текущий код:
def extract(line):
# last column is numeric but in string format
return ((float(line[-1])))
input = sc.textFile('file1.csv').zipWithIndex().filter(lambda (line,rownum): rownum>=0).map(lambda (line, rownum): line)
Data = (input
.map(lambda line: line.split(";"))
.filter(lambda line: len(line) >1 )
.map(extract)) # Map to tuples
row = Row("val")
df = Data.map(row).toDF()
df.map(lambda r: r.x).stdev()
Когда я запускаю это, я получаю ошибку как: AttributeError: x в df.map(lambda r: r.x).stdev(). Примечание: некоторые значения в моих данных отрицательны
1 ответ:
В Spark
Преобразовать в RDD и использовать метод
stdev:from pyspark.sql import Row import numpy as np row = Row("x") df = sc.parallelize([row(float(x)) for x in np.random.randn(100)]).toDF() df.rdd.map(lambda r: r.x).stdev()Используйте следующую формулу (здесь версия Scala):
from pyspark.sql.functions import avg, pow, col, sqrt, lit sd = sqrt( avg(col("x") * col("x")) - pow(avg(col("x")), lit(2))).alias("stdev") df.select(sd)Улей УДФ:
df.registerTempTable("df") sqlContext.sql("SELECT stddev(x) AS sd FROM df")Spark 1.6.0 вводит
stddev,stddev_sampи ещеstddev_popфункции.
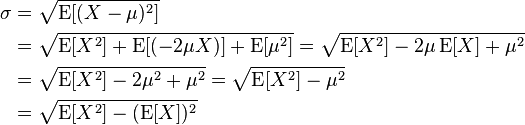
Comments