Как обрабатывать (Google Forms - электронная таблица) "флажки" ответов в SPSS
Я анализирую электронный опрос, который я сделал с помощью Google Forms, и у меня есть следующая проблема.
На один из вопросов можно получить несколько ответов в виде флажков, как показано на рисунке ниже. Вопрос на греческом языке, поэтому я добавил Некоторые Choice1, Choice2, Choice3 и т.д. Рядом с каждым ответом, чтобы облегчить мой вопрос.

В моих данных, когда кто-то выбрал, скажем Choice1 и Choice2,
У меня будет ответ, который является конкатенацией строки, которые он проверял, были разделены запятыми.
В этом случае это будет:
Choice1, Choice2
Если кто-то другой проверил Choice1, Choice2 и Choice4
его ответ в моих данных будет:
Choice1, Choice2, Choice4
Проблема в том, что SPSS не имеет способа разделения подстрок (разделенных запятыми) и понимания того, какие варианты выбора есть у каждого случая. Или, может быть, есть способ, но я его не знаю:)
Когда я, для например, сделайте простой частотный анализ для этого вопроса он производит таблицу, которая воспринимает
Choice1, Choice2
Как совершенно отличный случай от
Choice1, Choice2, Choice4
В идеале я хотел бы каким-то образом сказать SPSS, чтобы она считала частоту каждого уникального выбора (Choice1, Choice2, Choice3 и т. д.), а не каждую уникальную комбинацию этих вариантов.
Разве это возможно? И если это так, не могли бы вы указать мне на документацию, которую я нужно учиться, чтобы это произошло?
Thx много!
3 ответов:
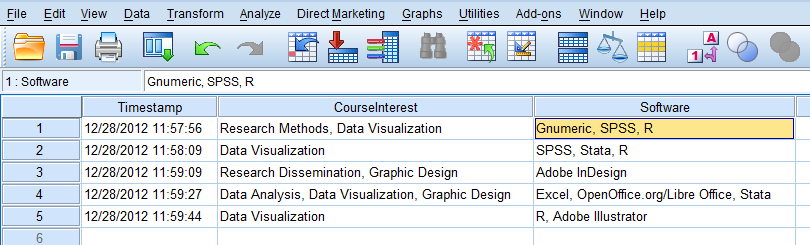
Представьте, что вы работаете со следующими данными, которые представляют собой CSV-файл, загруженный из вашей онлайн-формы. Скопируйте и вставьте текст ниже и сохраните его в текстовый файл с именем "CourseInterestSurvey.CSV".
Timestamp,Which courses are you interested in?,What software do you use? 12/28/2012 11:57:56,"Research Methods, Data Visualization","Gnumeric, SPSS, R" 12/28/2012 11:58:09,Data Visualization,"SPSS, Stata, R" 12/28/2012 11:59:09,"Research Dissemination, Graphic Design",Adobe InDesign 12/28/2012 11:59:27,"Data Analysis, Data Visualization, Graphic Design","Excel, OpenOffice.org/Libre Office, Stata" 12/28/2012 11:59:44,Data Visualization,"R, Adobe Illustrator"Считайте его в SPSS, используя следующий синтаксис:
GET DATA /TYPE=TXT /FILE="path\to\CourseInterestSurvey.CSV" /DELCASE=LINE /DELIMITERS="," /QUALIFIER='"' /ARRANGEMENT=DELIMITED /FIRSTCASE=2 /IMPORTCASE=ALL /VARIABLES= Timestamp A19 CourseInterest A49 Software A41. CACHE. EXECUTE. DATASET NAME DataSet2 WINDOW=FRONT. LIST.В настоящее время он выглядит так, как показано на рисунке ниже-три колонки (одна временная метка и две с нужными нам данными):
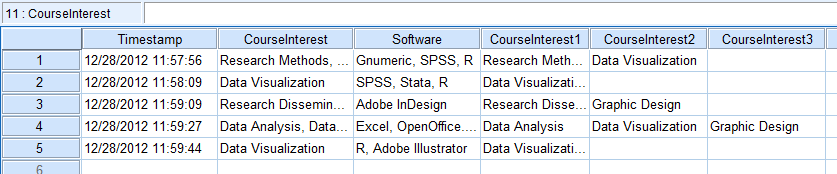
Работая с некоторым синтаксисом из здесь , мы можем разделить ячейки следующим образом:
* We know the string does not excede 50 characters. * We got that information while we were reading our data in. STRING #temp(a50). * We're going to work on the "CourseInterest" variable. COMPUTE #temp=CourseInterest. * We're going to create 3 new variables with the prefix "CourseInterest". * You should modify this according to the actual number of options your data has * and the maximum length of one of the strings in your data. VECTOR CourseInterest(3, a25). * Here's where the actual variable creation takes place. LOOP #i = 1 TO 3. . COMPUTE #index=index(#temp,","). . DO IF #index GT 0. . COMPUTE CourseInterest(#i)=LTRIM(substr(#temp,1, #index-1)). . COMPUTE #temp=substr(#temp, #index+1). . ELSE. . COMPUTE CourseInterest(#i)=LTRIM(#temp). . COMPUTE #temp=''. . END IF. END LOOP IF #index EQ 0. LIST.Результат:
Это относится только к одному столбцу за раз, и я недостаточно знаком, чтобы изменить его для работы с несколькими столбцами. Однако, если вы переключитесь на R, у меня уже есть некоторые готовые функции , помогающие справиться именно с такими ситуациями.
К сожалению, нет простого "встроенного" способа достичь этого,но это, безусловно, достижимо с формулами электронных таблиц или сценарием Google Apps.
Используя формулы, предполагая, что ваш вопрос с флажком попадает в столбец D, это приведет к" нормализованному " списку:
=ArrayFormula(TRANSPOSE(SPLIT(CONCAENATE(D2:D&",");",")))И вы можете превратить его в список из двух столбцов и запросить, чтобы вернуть таблицу частот:
=ArrayFormula(QUERY(TRANSPOSE(SPLIT(CONCATENATE(D2:D&",");","))&{"",""};"select Col1, count(Col2) group by Col1 label Col1 'Item', count(Col2) 'Frequency'";0))Если ваша локаль использует запятую в качестве десятичного разделителя, замените
{"",""}с{""\""}.
Легко разделить поля на отдельные переменные, как описано выше. Теперь определите эти переменные как набор множественных ответов (Analyze > Tables > Multiple Response Set), и вы можете проанализировать их с помощью процедур CTABLES или MULT REPONSE и построить график с помощью построителя диаграмм
Comments