Кластеризация по дате (по расстоянию) в Ruby
У меня есть огромный журнал с действиями, выполняемыми пользователями (например, модерирование контента).
Я хотел бы найти "массовые" действия, то есть действия, которые слишком плотны (пользователь, вероятно, сделал эти действия, не думая об этом слишком много :) ).
Это привело бы к кластеризации действий по дате (в линейном пространстве) и к маркировке слишком плотных кластеров.
Я не эксперт в алгоритмах и методах кластеризации, но я думаю, что K-означает кластеризацию это не поможет, так как я не знаю количества кластеров.
Кроме того, в идеале, я также хотел бы "тонко настроить" алгоритм.
Что бы вы посоветовали?
P.S. Вот некоторые ресурсы, которые я нашел (в Ruby):
2 ответов:
Взгляните на кластеризацию на основе плотности. Например, DBSCAN и оптика.
Это звучит именно так, как вы хотите.
K-means, вероятно, будет хорошо работать, если вы заинтересованы ваприорном известном количестве кластеров. Поскольку вы этого не делаете, вы можете прочитать об алгоритме LBG, который основан на k-средних и используется при сжатии данных для векторной квантовки. Это в основном итерационный k-means, который расщепляет центроиды после того, как они сходятся, и продолжает расщеплять, пока вы не достигнете приемлемого количества кластеров.
С другой стороны, поскольку ваши данные одномерны, вы могли бы сделать что-то совершенно другое.
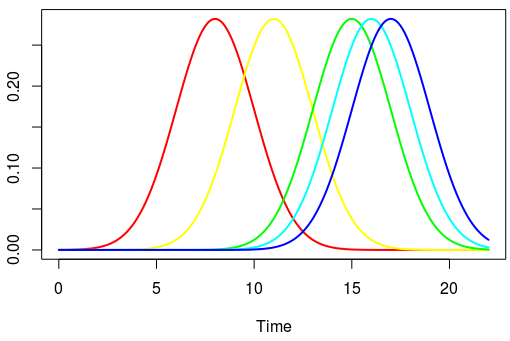
Предположим, что у вас есть действия, которые произошли в 5 точках времени: (8, 11, 15, 16, 17). Построим гауссово для каждого из этих действий с μ, равным времени и σ = 3.
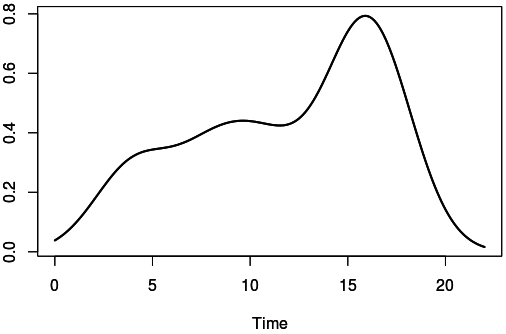
Теперь давайте посмотрим, как выглядит сумма значений этих гауссиан.
Он показывает плотность действий с пиком около 16.
Основываясь на этом наблюдении, я предлагаю следующее простое алгоритм.
Заметим, что для каждого действия требуется обновить только небольшой участок вектора, так как значения Гаусса очень быстро сходятся к нулю.
- создайте вектор нулей для интересующего временного диапазона.
- для каждого действия вычислите Гаусса и добавьте его к вектору.
- сканируйте вектор, ища значения, которые больше максимального значения в векторе, умноженного на α.
Вы можете настроить алгоритм, настроив значения из
- α ∈ [0,1], что указывает на то, насколько существенным должен быть отмечен пик активности,
- σ, что влияет на расстояние действий, которые считаются близкими друг к другу, и
- периоды времени на элемент вектора (минуты, секунды и т. д.).
Обратите внимание, что алгоритм является линейным с точки зрения количества действий. Кроме того, это не должно быть трудно распараллелить: разделить ваши данные по нескольким процессам суммирования Гауссианов, а затем суммировать сгенерированные векторы.
Comments