Понимание списка во вложенном списке?
у меня есть этот вложенный список:
l = [['40', '20', '10', '30'], ['20', '20', '20', '20', '20', '30', '20'], ['30', '20', '30', '50', '10', '30', '20', '20', '20'], ['100', '100'], ['100', '100', '100', '100', '100'], ['100', '100', '100', '100']]
, что я хочу сделать, это преобразовать каждый элемент в списке, чтобы плавать. Мое решение таково:
newList = []
for x in l:
for y in x:
newList.append(float(y))
но можно ли это сделать с помощью вложенного списка понимания, не так ли?
что я сделал:
[float(y) for y in x for x in l]
но тогда результат-куча 100 с суммой 2400.
любое решение, объяснение будет высоко ценится. Спасибо!
12 ответов:
вот как бы вы сделали это с вложенным списком понимания:
[[float(y) for y in x] for x in l]это даст вам список списков, подобный тому, с чего вы начали, за исключением поплавков вместо строк. Если вы хотите один плоский список, то вы должны использовать
[float(y) for x in l for y in x].
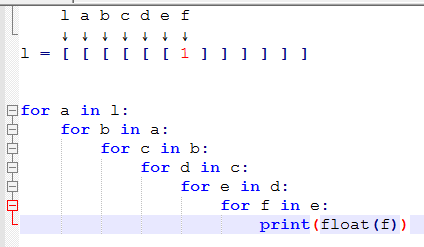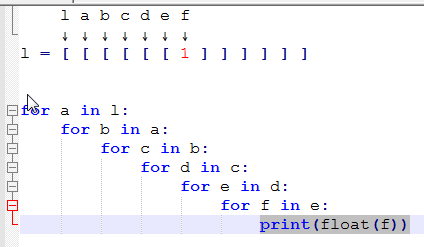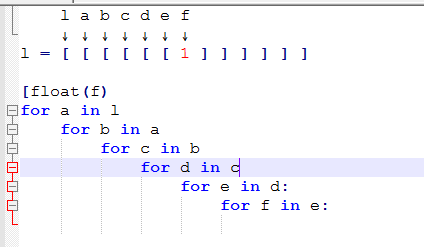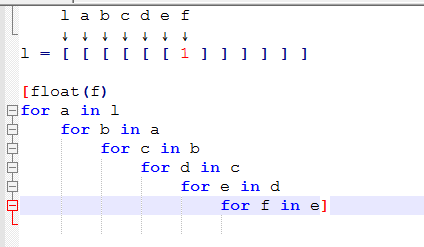
вот как работает понимание вложенного списка:
l a b c d e f ↓ ↓ ↓ ↓ ↓ ↓ ↓ In [1]: l = [ [ [ [ [ [ 1 ] ] ] ] ] ] In [2]: for a in l: ...: for b in a: ...: for c in b: ...: for d in c: ...: for e in d: ...: for f in e: ...: print(float(f)) ...: 1.0 In [3]: [float(f) for a in l ...: for b in a ...: for c in b ...: for d in c ...: for e in d ...: for f in e] Out[3]: [1.0] #Which can be written in single line as In [4]: [float(f) for a in l for b in a for c in b for d in c for e in d for f in e] Out[4]: [1.0]
>>> l = [['40', '20', '10', '30'], ['20', '20', '20', '20', '20', '30', '20'], ['30', '20', '30', '50', '10', '30', '20', '20', '20'], ['100', '100'], ['100', '100', '100', '100', '100'], ['100', '100', '100', '100']] >>> new_list = [float(x) for xs in l for x in xs] >>> new_list [40.0, 20.0, 10.0, 30.0, 20.0, 20.0, 20.0, 20.0, 20.0, 30.0, 20.0, 30.0, 20.0, 30.0, 50.0, 10.0, 30.0, 20.0, 20.0, 20.0, 100.0, 100.0, 100.0, 100.0, 100.0, 100.0, 100.0, 100.0, 100.0, 100.0, 100.0]
Не уверен, что ваш желаемый результат, но если вы используете понимание списка, порядок следует за порядком вложенных циклов, которые у вас есть в обратном порядке. Так что я получил то, что я думаю, что вы хотите с:
[float(y) for x in l for y in x]принцип: используйте тот же порядок, который вы использовали бы при написании его как вложенные циклы for.
так как я немного опоздал здесь, но я хотел бы поделиться тем, как на самом деле список понимание работает особенно вложенный список понимание :
New_list= [[float(y) for x in l]на самом деле то же, что :
New_list=[] for x in l: New_list.append(x)а теперь вложенный список понимания:
[[float(y) for y in x] for x in l]это то же самое, что ;
new_list=[] for x in l: sub_list=[] for y in x: sub_list.append(float(y)) new_list.append(sub_list) print(new_list)выход:
[[40.0, 20.0, 10.0, 30.0], [20.0, 20.0, 20.0, 20.0, 20.0, 30.0, 20.0], [30.0, 20.0, 30.0, 50.0, 10.0, 30.0, 20.0, 20.0, 20.0], [100.0, 100.0], [100.0, 100.0, 100.0, 100.0, 100.0], [100.0, 100.0, 100.0, 100.0]]
у меня была аналогичная проблема для решения, поэтому я столкнулся с этим вопросом. Я сделал сравнение производительности Эндрю Кларка и ответа Нараяна, которым я хотел бы поделиться.
основное различие между двумя ответами заключается в том, как они перебирают внутренние списки. Один из них использует встроенный карта, в то время как другой, используя список понимания. функция Map имеет небольшое преимущество в производительности для ее эквивалентного понимания списка, если она не требует использования лямбда. Так что в контексте этого вопроса
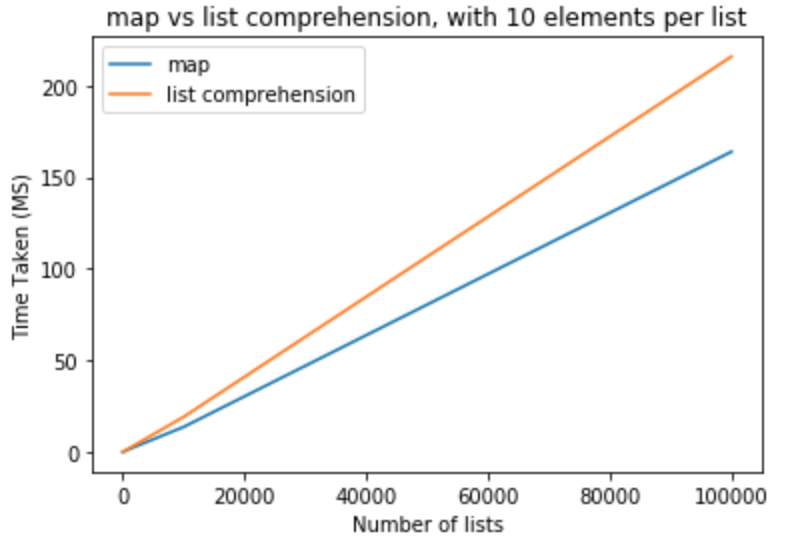
mapдолжен работать немного лучше, чем понимание списка.позволяет сделать тест производительности, чтобы увидеть, если это на самом деле правда. Я использовал Python версии 3.5.0 для выполнения всех этих тестов. В первом наборе тестов я хотел бы сохранить элементы в списке, чтобы быть 10 и варьировать количество списков с 10-100,000
>>> python -m timeit "[list(map(float,k)) for k in [list(range(0,10))]*10]" >>> 100000 loops, best of 3: 15.2 usec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,10))]*10]" >>> 10000 loops, best of 3: 19.6 usec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,10))]*100]" >>> 100000 loops, best of 3: 15.2 usec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,10))]*100]" >>> 10000 loops, best of 3: 19.6 usec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,10))]*1000]" >>> 1000 loops, best of 3: 1.43 msec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,10))]*1000]" >>> 100 loops, best of 3: 1.91 msec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,10))]*10000]" >>> 100 loops, best of 3: 13.6 msec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,10))]*10000]" >>> 10 loops, best of 3: 19.1 msec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,10))]*100000]" >>> 10 loops, best of 3: 164 msec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,10))]*100000]" >>> 10 loops, best of 3: 216 msec per loop
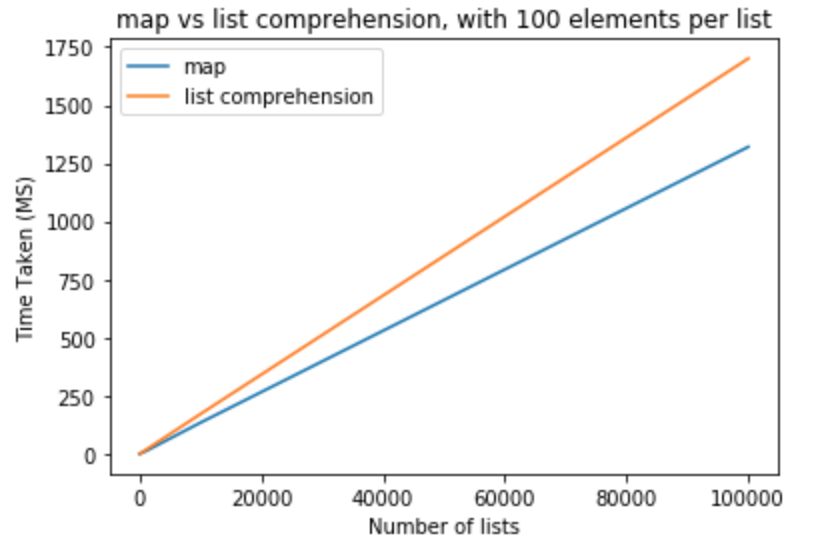
в следующем наборе тесты я хотел бы поднять количество элементов в списках до 100.
>>> python -m timeit "[list(map(float,k)) for k in [list(range(0,100))]*10]" >>> 10000 loops, best of 3: 110 usec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,100))]*10]" >>> 10000 loops, best of 3: 151 usec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,100))]*100]" >>> 1000 loops, best of 3: 1.11 msec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,100))]*100]" >>> 1000 loops, best of 3: 1.5 msec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,100))]*1000]" >>> 100 loops, best of 3: 11.2 msec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,100))]*1000]" >>> 100 loops, best of 3: 16.7 msec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,100))]*10000]" >>> 10 loops, best of 3: 134 msec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,100))]*10000]" >>> 10 loops, best of 3: 171 msec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,100))]*100000]" >>> 10 loops, best of 3: 1.32 sec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,100))]*100000]" >>> 10 loops, best of 3: 1.7 sec per loop
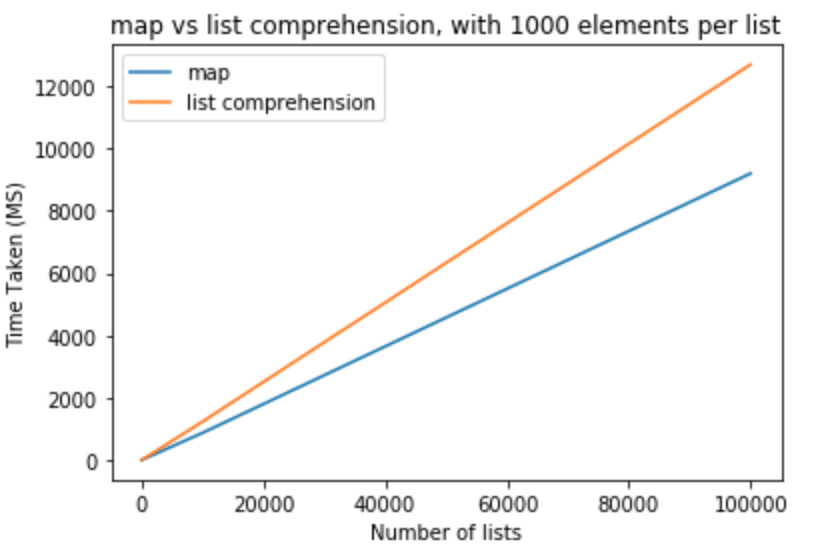
позволяет сделать смелый шаг и изменить количество элементов в списках должны быть 1000
>>> python -m timeit "[list(map(float,k)) for k in [list(range(0,1000))]*10]" >>> 1000 loops, best of 3: 800 usec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,1000))]*10]" >>> 1000 loops, best of 3: 1.16 msec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,1000))]*100]" >>> 100 loops, best of 3: 8.26 msec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,1000))]*100]" >>> 100 loops, best of 3: 11.7 msec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,1000))]*1000]" >>> 10 loops, best of 3: 83.8 msec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,1000))]*1000]" >>> 10 loops, best of 3: 118 msec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,1000))]*10000]" >>> 10 loops, best of 3: 868 msec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,1000))]*10000]" >>> 10 loops, best of 3: 1.23 sec per loop >>> python -m timeit "[list(map(float,k)) for k in [list(range(0,1000))]*100000]" >>> 10 loops, best of 3: 9.2 sec per loop >>> python -m timeit "[[float(y) for y in x] for x in [list(range(0,1000))]*100000]" >>> 10 loops, best of 3: 12.7 sec per loop
из этих тестов можно сделать вывод, что
mapимеет преимущество производительности по сравнению с пониманием списка в этом случае. Это также применимо, если вы пытаетесь привести к либоintилиstr. Для небольшого числа списков с меньшим количеством элементов в списке разница незначительна. Для больших списков с большим количеством элементов в списке можно было бы использоватьmapвместо понимания списка, но это полностью зависит от потребностей приложения.однако я лично считаю понимание списка более читаемым и идиоматичным, чем
map. Это де-факто стандарт в Python. Обычно люди более опытны и удобны(особенно новичок) в использовании список понимания чемmap.
Если вам не нравятся вложенные списки понимания, вы можете использовать карта
эта проблема может быть решена без использования цикла for.Для этого будет достаточно однострочного кода. Использование вложенной карты с функцией лямбда также работает здесь.
l = [['40', '20', '10', '30'], ['20', '20', '20', '20', '20', '30', '20'], ['30', '20', '30', '50', '10', '30', '20', '20', '20'], ['100', '100'], ['100', '100', '100', '100', '100'], ['100', '100', '100', '100']] map(lambda x:map(lambda y:float(y),x),l)и список вывода будет выглядеть следующим образом:
[[40.0, 20.0, 10.0, 30.0], [20.0, 20.0, 20.0, 20.0, 20.0, 30.0, 20.0], [30.0, 20.0, 30.0, 50.0, 10.0, 30.0, 20.0, 20.0, 20.0], [100.0, 100.0], [100.0, 100.0, 100.0, 100.0, 100.0], [100.0, 100.0, 100.0, 100.0]]
лучший способ сделать это, на мой взгляд, это использовать python
itertoolsпакета.>>>import itertools >>>l1 = [1,2,3] >>>l2 = [10,20,30] >>>[l*2 for l in itertools.chain(*[l1,l2])] [2, 4, 6, 20, 40, 60]
deck = [] for rank in ranks: for suit in suits: deck.append(('%s%s')%(rank, suit))Это может быть достигнуто с помощью понимания списка:
[deck.append((rank,suit)) for suit in suits for rank in ranks ]
Comments