создание диаграмм рассеяния matplotlib из фреймов данных в панд Python
каков наилучший способ сделать серию диаграмм рассеяния с помощью matplotlib С pandas фрейм данных в Python?
например, если у меня есть фрейм данных df что имеет некоторые столбцы интереса, я нахожу себя обычно преобразования все в массивы:
import matplotlib.pylab as plt
# df is a DataFrame: fetch col1 and col2
# and drop na rows if any of the columns are NA
mydata = df[["col1", "col2"]].dropna(how="any")
# Now plot with matplotlib
vals = mydata.values
plt.scatter(vals[:, 0], vals[:, 1])
проблема с преобразованием всего в массив перед построением графика заключается в том, что он заставляет вас вырваться из фреймов данных.
рассмотрим эти два варианта использования, когда имеется полный фрейм данных имеет важное значение для построения графика:
например, что делать, если вы хотите теперь посмотреть на все значения
col3для соответствующих значений, которые вы построили в вызовеscatter, и цвет каждой точки (или размер) это значение? Вам придется вернуться, вытащить не на значенияcol1,col2и проверить, что их соответствующие значения.
есть ли способ построить график при сохранении фрейма данных? Для пример:
mydata = df.dropna(how="any", subset=["col1", "col2"])
# plot a scatter of col1 by col2, with sizes according to col3
scatter(mydata(["col1", "col2"]), s=mydata["col3"])
аналогично, представьте, что вы хотите фильтровать или окрашивать каждую точку по-разному в зависимости от значений некоторых из ее столбцов. Например, что делать, если вы хотите автоматически построить метки точек, которые соответствуют определенному срезу на
col1, col2рядом с ними (где метки хранятся в другом столбце df), или цвет этих точек по-разному, как люди делают с кадрами данных в R. Для пример:
mydata = df.dropna(how="any", subset=["col1", "col2"])
myscatter = scatter(mydata[["col1", "col2"]], s=1)
# Plot in red, with smaller size, all the points that
# have a col2 value greater than 0.5
myscatter.replot(mydata["col2"] > 0.5, color="red", s=0.5)
как это можно сделать?
EDIT ответить crewbum:
вы говорите, что лучший способ-построить каждое условие (например,subset_a,subset_b) отдельно. Что делать, если у вас есть много условий, например, вы хотите разделить рассеиватели на 4 типа точек или даже больше, построив каждый из них в разной форме/цвете. Как вы можете элегантно применить условие a, b, c и т. д. и убедитесь, что вы затем сюжет "остальное" (вещи ни в одном из этих условий) как последний шаг?
аналогично в вашем примере, где вы строитеcol1,col2 зависимости col3, что делать, если есть значения NA, которые нарушают связь между col1,col2,col3? Например, если вы хотите построить все col2 ценности, основанные на их col3 значения, но некоторые строки имеют значение NA в любом col1 или col3, вынуждает вас использовать dropna первый. Так что вы бы сделали:
mydata = df.dropna(how="any", subset=["col1", "col2", "col3")
тогда вы можете построить с помощью mydata как вы показать -- построение разброса между col1,col2 использовать значение col3. Но mydata будут отсутствовать некоторые пункты, которые имеют значения для col1,col2, но на col3, и те еще должны быть построены... Итак, как бы вы в основном построили "остальные" данные, т. е. точки, которые не в отфильтрованном наборе mydata?
2 ответов:
попробуйте передать столбцы
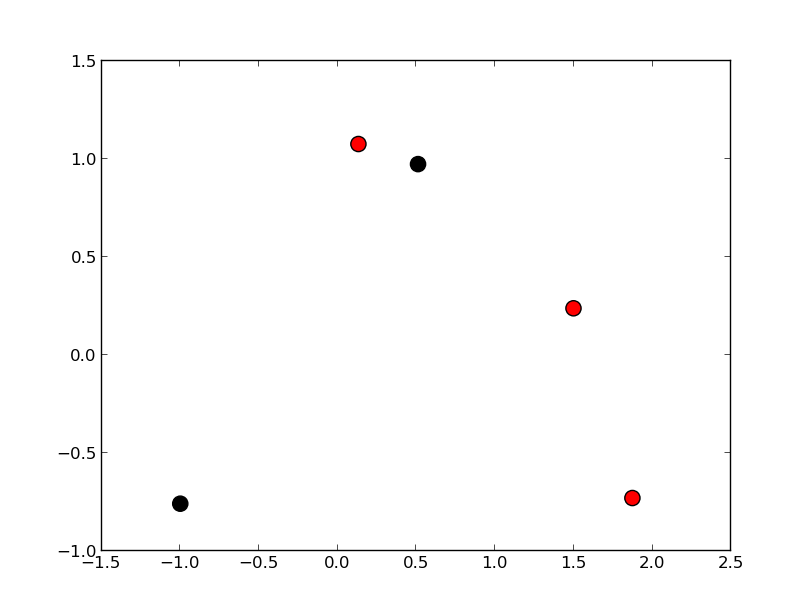
DataFrameнепосредственно в matplotlib, как в примерах ниже, вместо извлечения их в виде массивов numpy.df = pd.DataFrame(np.random.randn(10,2), columns=['col1','col2']) df['col3'] = np.arange(len(df))**2 * 100 + 100 In [5]: df Out[5]: col1 col2 col3 0 -1.000075 -0.759910 100 1 0.510382 0.972615 200 2 1.872067 -0.731010 500 3 0.131612 1.075142 1000 4 1.497820 0.237024 1700варьировать размер точки рассеяния на основе другого столбца
plt.scatter(df.col1, df.col2, s=df.col3) # OR (with pandas 0.13 and up) df.plot(kind='scatter', x='col1', y='col2', s=df.col3)
изменить цвет точки рассеяния на основе другого столбца
colors = np.where(df.col3 > 300, 'r', 'k') plt.scatter(df.col1, df.col2, s=120, c=colors) # OR (with pandas 0.13 and up) df.plot(kind='scatter', x='col1', y='col2', s=120, c=colors)
Scatter plot с легендой
тем не менее, самый простой способ, который я нашел, чтобы создать точечную диаграмму с легенда, чтобы позвонить
plt.scatterодин раз для каждого типа.cond = df.col3 > 300 subset_a = df[cond].dropna() subset_b = df[~cond].dropna() plt.scatter(subset_a.col1, subset_a.col2, s=120, c='b', label='col3 > 300') plt.scatter(subset_b.col1, subset_b.col2, s=60, c='r', label='col3 <= 300') plt.legend()
обновление
из того, что я могу сказать, matplotlib просто пропускает точки с координатами NA x/y или настройками стиля NA (например, цвет/размер). Чтобы найти точки, пропущенные из-за NA, попробуйте
isnullспособ:df[df.col3.isnull()]чтобы разделить список точек на множество типов, взгляните на включает в себя
select, который является векторизованным if-then-else реализация и принимает необязательное значение по умолчанию. Например:df['subset'] = np.select([df.col3 < 150, df.col3 < 400, df.col3 < 600], [0, 1, 2], -1) for color, label in zip('bgrm', [0, 1, 2, -1]): subset = df[df.subset == label] plt.scatter(subset.col1, subset.col2, s=120, c=color, label=str(label)) plt.legend()



мало что можно добавить к великому ответу Гаррета, но у панд также есть
scatterметод. Используя это, это так же просто, какdf = pd.DataFrame(np.random.randn(10,2), columns=['col1','col2']) df['col3'] = np.arange(len(df))**2 * 100 + 100 df.plot.scatter('col1', 'col2', df['col3'])

Comments