Метод Симпсона для интеграции вещественных функций с CUDA
Я пытаюсь кодировать интеграцию по методу Симпсона в CUDA.
Это формула для Правила Симпсона
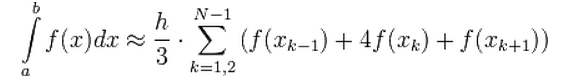
Где x_k = a + k*h.
Вот мой код
__device__ void initThreadBounds(int *n_start, int *n_end, int n,
int totalBlocks, int blockWidth)
{
int threadId = blockWidth * blockIdx.x + threadIdx.x;
int nextThreadId = threadId + 1;
int threads = blockWidth * totalBlocks;
*n_start = (threadId * n)/ threads;
*n_end = (nextThreadId * n)/ threads;
}
__device__ float reg_func (float x)
{
return x;
}
typedef float (*p_func) (float);
__device__ p_func integrale_f = reg_func;
__device__ void integralSimpsonMethod(int totalBlocks, int totalThreads,
double a, double b, int n, float p_function(float), float* result)
{
*result = 0;
float h = (b - a)/n;
//*result = p_function(a)+p_function(a + h * n);
//parallel
int idx_start;
int idx_end;
initThreadBounds(&idx_start, &idx_end, n-1, totalBlocks, totalThreads);
//parallel_ends
for (int i = idx_start; i < idx_end; i+=2) {
*result += ( p_function(a + h*(i-1)) +
4 * p_function(a + h*(i)) +
p_function(a + h*(i+1)) ) * h/3;
}
}
__global__ void integralSimpson(int totalBlocks, int totalThreads, float* result)
{
float res = 0;
integralSimpsonMethod(totalBlocks, totalThreads, 0, 10, 1000, integrale_f, &res);
result[(blockIdx.x*totalThreads + threadIdx.x)] = res;
//printf ("Simpson methodn");
}
__host__ void inttest()
{
const int blocksNum = 32;
const int threadNum = 32;
float *device_resultf;
float host_resultf[threadNum*blocksNum]={0};
cudaMalloc((void**) &device_resultf, sizeof(float)*threadNum*blocksNum);
integralSimpson<<<blocksNum, threadNum>>>(blocksNum, threadNum, device_resultf);
cudaThreadSynchronize();
cudaMemcpy(host_resultf, device_resultf, sizeof(float) *threadNum*blocksNum,
cudaMemcpyDeviceToHost);
float sum = 0;
for (int i = 0; i != blocksNum*threadNum; ++i) {
sum += host_resultf[i];
// printf ("result in %i cell = %f n", i, host_resultf[i]);
}
printf ("sum = %f n", sum);
cudaFree(device_resultf);
}
int main(int argc, char* argv[])
{
inttest();
int i;
scanf ("%d",&i);
}
Проблема в том, что он работает неправильно, когда
n меньше 100000. Для интеграла от 0 до 10 результат равен ~99, но когда n = 100000 или больше, он работает нормально, и результат равен ~50. Что случилось, ребята?
2 ответов:
Основная проблема здесь заключается в том, что вы не понимаете свой собственный алгоритм.
Ваша функция
integralSimpsonMethod()сконструирована таким образом, что каждый поток дискретизирует не менее 3 квадратурных точек на подинтервал в интегральной области. Поэтому, если вы выберете n таким образом, что это будет меньше, чем в четыре раза число потоков в вызове ядра, неизбежно, что каждый подинтервал будет перекрываться и результирующий Интеграл будет неверным. Вы должны убедиться, что код проверяет и масштабирует поток count или n, чтобы они не создавали перекрытия при вычислении интеграла.Если вы делаете это для чего-то другого, кроме самоидентификации, то я рекомендую вам посмотреть составную версию правила Симпсона. Это гораздо лучше подходит для параллельной реализации и будет значительно эффективнее, если реализовано правильно.
Я бы предложил подход к интеграции Симпсона с использованием тяги CUDA. Вам в основном нужно пять шагов:
- генерировать квадратурные веса Симпсона;
- генерировать точки выборки функции;
- генерировать значения функций;
- вычислить элементарное произведение между квадратурными весами и значениями функций;
- суммируйте вышеперечисленные продукты.
Шаг #1 требует создания массива с многократно повторяющимися элементами, а именно:
1 4 2 4 2 4 ... 1для дела Симпсона. Это может быть достигнуто путем заимствования подхода Роберта Кровеллы в библиотеке тяги cuda repeat vector multiple times.Шаг #2 может быть выполнен с использованием couting_iterators и заимствованием подхода talonmies вназначение и использование counting_iterators в библиотеке тяги CUDA .
Шаг #3-это применение
thrust::transform.Шаги #4 и #5 могут быть выполнены вместе с помощью
thrust::inner_product.Этот подход может быть использован также для используйте, когда другиеправила квадратурного интегрирования представляют интерес.
Вот код
#include <thrust/iterator/counting_iterator.h> #include <thrust/iterator/transform_iterator.h> #include <thrust/iterator/permutation_iterator.h> #include <thrust/iterator/counting_iterator.h> #include <thrust/iterator/constant_iterator.h> #include <thrust/inner_product.h> #include <thrust/functional.h> #include <thrust/fill.h> #include <thrust/device_vector.h> #include <thrust/host_vector.h> // for printing #include <thrust/copy.h> #include <ostream> #define STRIDE 2 #define N 100 #define pi_f 3.14159265358979f // Greek pi in single precision struct sin_functor { __host__ __device__ float operator()(float x) const { return sin(2.f*pi_f*x); } }; template <typename Iterator> class strided_range { public: typedef typename thrust::iterator_difference<Iterator>::type difference_type; struct stride_functor : public thrust::unary_function<difference_type,difference_type> { difference_type stride; stride_functor(difference_type stride) : stride(stride) {} __host__ __device__ difference_type operator()(const difference_type& i) const { return stride * i; } }; typedef typename thrust::counting_iterator<difference_type> CountingIterator; typedef typename thrust::transform_iterator<stride_functor, CountingIterator> TransformIterator; typedef typename thrust::permutation_iterator<Iterator,TransformIterator> PermutationIterator; // type of the strided_range iterator typedef PermutationIterator iterator; // construct strided_range for the range [first,last) strided_range(Iterator first, Iterator last, difference_type stride) : first(first), last(last), stride(stride) {} iterator begin(void) const { return PermutationIterator(first, TransformIterator(CountingIterator(0), stride_functor(stride))); } iterator end(void) const { return begin() + ((last - first) + (stride - 1)) / stride; } protected: Iterator first; Iterator last; difference_type stride; }; int main(void) { // --- Generate the integration coefficients thrust::host_vector<float> h_coefficients(STRIDE); h_coefficients[0] = 4.f; h_coefficients[1] = 2.f; thrust::device_vector<float> d_coefficients(N); typedef thrust::device_vector<float>::iterator Iterator; strided_range<Iterator> pos1(d_coefficients.begin()+1, d_coefficients.end()-2, STRIDE); strided_range<Iterator> pos2(d_coefficients.begin()+2, d_coefficients.end()-1, STRIDE); thrust::fill(pos1.begin(), pos1.end(), h_coefficients[0]); thrust::fill(pos2.begin(), pos2.end(), h_coefficients[1]); d_coefficients[0] = 1.f; d_coefficients[N-1] = 1.f; // print the generated d_coefficients std::cout << "d_coefficients: "; thrust::copy(d_coefficients.begin(), d_coefficients.end(), std::ostream_iterator<float>(std::cout, " ")); std::cout << std::endl; // --- Generate sampling points float a = 0.f; float b = .5f; float Dx = (b-a)/(float)(N-1); thrust::device_vector<float> d_x(N); thrust::transform(thrust::make_counting_iterator(a/Dx), thrust::make_counting_iterator((b+1.f)/Dx), thrust::make_constant_iterator(Dx), d_x.begin(), thrust::multiplies<float>()); // --- Calculate function values thrust::device_vector<float> d_y(N); thrust::transform(d_x.begin(), d_x.end(), d_y.begin(), sin_functor()); // --- Calculate integral float integral = (Dx/3.f) * thrust::inner_product(d_y.begin(), d_y.begin() + N, d_coefficients.begin(), 0.0f); printf("The integral is = %f\n", integral); getchar(); return 0; }
Comments