Mongodb объясняет для структуры агрегации
есть ли функция объяснения для структуры агрегации в MongoDB? Я не вижу его в документации.
Если нет, есть ли другой способ проверить, как запрос выполняется в рамках агрегации?
Я знаю, что с find вы просто делаете
db.collection.find().explain()
но с помощью структуры агрегации я получаю ошибку
db.collection.aggregate(
{ $project : { "Tags._id" : 1 }},
{ $unwind : "$Tags" },
{ $match: {$or: [{"Tags._id":"tag1"},{"Tags._id":"tag2"}]}},
{
$group:
{
_id : { id: "$_id"},
"count": { $sum:1 }
}
},
{ $sort: {"count":-1}}
).explain()
3 ответов:
начиная с версии MongoDB 3.0, просто измените порядок от
collection.aggregate(...).explain()до
collection.explain().aggregate(...)даст вам желаемые результаты (документация здесь).
для более старых версий >= 2.6, вы должны использовать
explainопция для агрегации операций конвейера
explain:truedb.collection.aggregate([ { $project : { "Tags._id" : 1 }}, { $unwind : "$Tags" }, { $match: {$or: [{"Tags._id":"tag1"},{"Tags._id":"tag2"}]}}, { $group: { _id : "$_id", count: { $sum:1 } }}, {$sort: {"count":-1}} ], { explain:true } )важным соображением в рамках агрегации является то, что индекс может быть только используется для извлечения исходных данных для конвейера (например, использование
$match,$sort,$geonearв начале конвейера) , а также последующие$lookupи$graphLookupэтапах. После того, как данные были извлечены в конвейер агрегации для обработки (например, проходя через этапы, такие как$project,$unwindи$group) дальнейшие манипуляции будут в памяти (возможно, с использованием временных файлов, если установить).оптимизация трубопроводов
в общем, вы можно оптимизировать конвейеры агрегации с помощью:
- запуск конвейера с
$matchэтап для ограничения обработки соответствующих документов.- обеспечение первоначальных
$match/$sortэтапы поддерживаются эффективный индекс.- ранняя фильтрация данных с помощью
$match,$limitи$skip.- минимизация ненужных этапов и манипуляций с документами (возможно, пересмотр схемы, если сложная агрегация гимнастика обязательна).
- использование новых операторов агрегации, если вы обновили свой сервер MongoDB. Например, MongoDB 3.4 добавил много новые этапы агрегации и выражений включая поддержку работы с массивами, строками, и фасеток.
есть также ряд Оптимизация Конвейера Агрегации это автоматически происходит в зависимости от вашей версии сервера MongoDB. Например, смежные этапы могут быть объединены и / или переупорядочены для улучшения исполнения без влияния на выходные результаты.
ограничения
как и в MongoDB 3.4, структура агрегации
explainопция предоставляет информацию о том, как обрабатывается конвейер, но не поддерживает тот же уровень детализации, что иexecutionStatsрежимfind()запрос. Если вы сосредоточены на оптимизации начального выполнения запроса, вам, вероятно, будет полезно просмотреть эквивалентfind().explain()запросexecutionStatsилиallPlansExecutionмногословие.есть несколько соответствующих запросов функций для просмотра / upvote в MongoDB issue tracker относительно более подробной статистики выполнения, чтобы помочь оптимизировать конвейеры агрегации / профиля:
- SERVER-19758: добавить" executionStats "и" allPlansExecution " объяснить режимы агрегации объяснить
- SERVER-21784: отслеживание статистики выполнения для каждого этапа конвейера агрегации и выставление через объяснить
- SERVER-22622: улучшение $lookup объяснить, чтобы указать план запроса на" от " коллекции
начиная с версии 2.6.x mongodb позволяет пользователям делать объясните с помощью aggregation framework.
все, что вам нужно сделать, это добавить explain : true
db.records.aggregate( [ ...your pipeline...], { explain: true } )благодаря Рафе, я знаю, что это можно было сделать даже в 2.4, но только через
runCommand(). Но теперь вы также можете использовать aggregate.
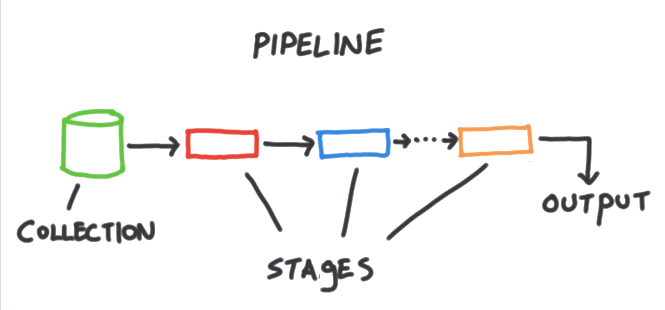
структура агрегации представляет собой набор инструментов аналитики в
MongoDBЭто позволяет нам запускать различные типы отчетов или анализа документов в одной или нескольких коллекциях. Основано на идее трубопровода. Мы принимаем ввод отMongoDBсбор и передача документов из этой коллекции через один или несколько этапов, каждый из которых выполняет различные операции на его входах. Каждый этап принимает в качестве входных данных все, что этап до него производится как выход. А входы и выходы для всех этапов-это поток документов. Каждый этап имеет определенную работу, которую он выполняет. Он ожидает определенную форму документа и производит определенный вывод, который сам по себе является потоком документов. В конце трубопровода мы получаем доступ к выходу.
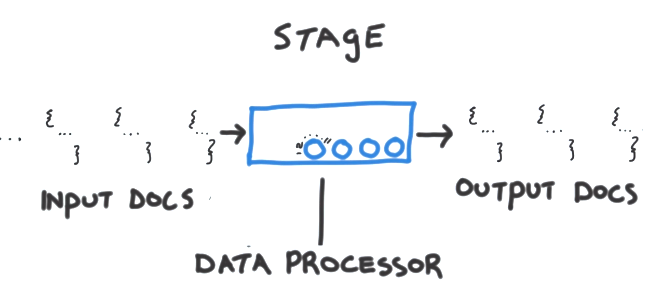
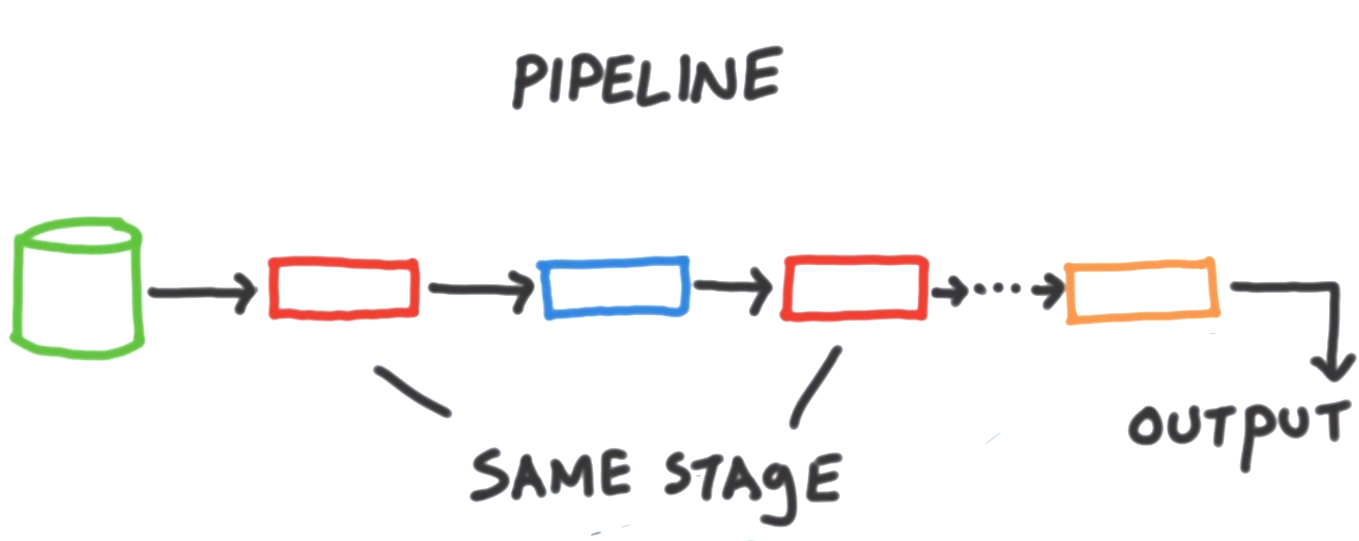
отдельный этап-это блок обработки данных. Каждый этап принимает в качестве входных данных поток документов по одному за раз, обрабатывает каждый документ по одному за раз. время и производит выходной поток документов. Опять же, по одному за раз. Каждый этап предоставляет набор ручек или перестраиваемых элементов, которые мы можем контролировать для параметризации этапа для выполнения любой задачи, которую мы заинтересованы в выполнении. Таким образом, этап выполняет общую задачу - задачу общего назначения некоторого вида и параметризует этап для конкретного набора документов, с которыми мы работаем. И именно то, что мы хотели бы на этом этапе сделать с этими документами. Эти переменные, как правило, принимают форму операторов то, что мы можем предоставить, будет изменять поля, выполнять арифметические операции, изменять форму документов или выполнять какую-то задачу накопления, а также проверять другие вещи. Часто бывает, что мы хотим включить один и тот же тип этапа несколько раз в одном конвейере.
например, мы можем выполнить начальный фильтр, чтобы нам не пришлось передавать всю коллекцию в наш конвейер. Но потом, после некоторых дополнительной обработки, фильтрации еще раз, используя другой набор критериев. Итак, чтобы резюмировать, конвейер работает с
MongoDBколлекция. Они состоят из этапов, каждый из которых выполняет различные задачи обработки данных на входе и производит документы в качестве выходных данных для передачи на следующий этап. И, наконец, в конце конвейера выводится, что мы можем сделать что-то в нашем приложении. Во многих случаях необходимо включать такую же сцену несколько раз в течение отдельный трубопровод.
Comments