Наиболее недоиспользуемая визуализация данных [закрыто]
ответы:
- не очень часто используется в
практиковать. - быть понятным без многого
предыстории обсуждения. - применимо в много общего положения.
- включить воспроизводимый код для создания
пример (предпочтительно в R). Связанное изображение будет
милый.
15 ответов:
Я согласен с другими плакатами: книги туфте фантастичны и хорошо стоит читать.
во-первых, я бы указал вам на очень хороший учебник по ggplot2 и ggobi от "глядя на данные" в начале этого года. Кроме того, я бы просто выделил одну визуализацию из R и два графических пакета (которые не так широко используются как базовая графика, решетка или ggplot):
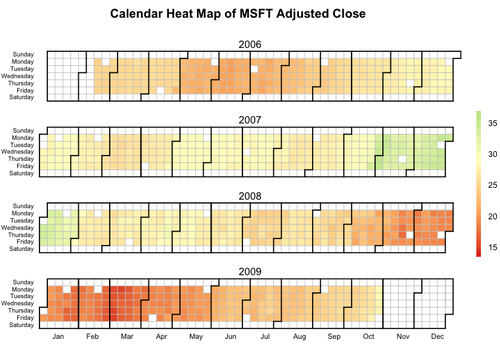
Тепловые Карты
Мне очень нравится визуализации, которые могут обрабатывать многомерные данные, особенно данные временных рядов. тепловые карты может быть полезно для этого. Один действительно аккуратный был показан Дэвид Смит на блоге революций. Вот код ggplot любезно предоставленный Хэдли:
stock <- "MSFT" start.date <- "2006-01-12" end.date <- Sys.Date() quote <- paste("http://ichart.finance.yahoo.com/table.csv?s=", stock, "&a=", substr(start.date,6,7), "&b=", substr(start.date, 9, 10), "&c=", substr(start.date, 1,4), "&d=", substr(end.date,6,7), "&e=", substr(end.date, 9, 10), "&f=", substr(end.date, 1,4), "&g=d&ignore=.csv", sep="") stock.data <- read.csv(quote, as.is=TRUE) stock.data <- transform(stock.data, week = as.POSIXlt(Date)$yday %/% 7 + 1, wday = as.POSIXlt(Date)$wday, year = as.POSIXlt(Date)$year + 1900) library(ggplot2) ggplot(stock.data, aes(week, wday, fill = Adj.Close)) + geom_tile(colour = "white") + scale_fill_gradientn(colours = c("#D61818","#FFAE63","#FFFFBD","#B5E384")) + facet_wrap(~ year, ncol = 1)который в конечном итоге выглядит примерно так:
RGL: интерактивная 3D графика
еще один пакет, который стоит усилий, чтобы узнать это RGL, что легко обеспечивает возможность создания интерактивной 3D-графики. Есть много примеров в интернете для этого (в том числе в документации rgl).
у R-Wiki есть хороший пример о том, как построить 3D точечные графики с помощью rgl.
GGobi
еще один пакет, который стоит знать, это rggobi. Есть книга Спрингера на эту тему и много отличная документация / примеры в интернете, в том числе на "в" конечно.
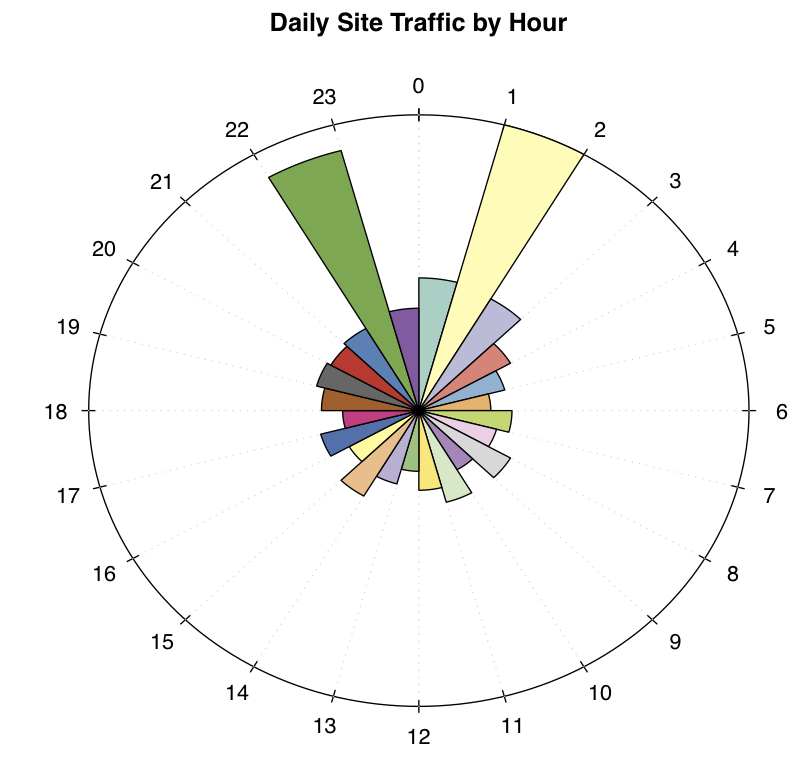
графики, использующие полярные координаты, конечно, недостаточно используются-некоторые сказали бы с хорошей причиной. Я думаю, что ситуации, которые оправдывают их использование, не являются общими; я также думаю, что когда эти ситуации возникают, полярные графики могут выявить закономерности в данных, которые линейные графики не могут.
Я думаю, это потому, что иногда ваши данные по сути Полярный, а не линейный--например, он цикличен (X-координаты, представляющие время в течение 24-часового дня в течение нескольких дней), или данные ранее были нанесены на карту полярного пространства объектов.
вот пример. Этот график показывает средний объем трафика веб-сайта по часам. Обратите внимание на два всплеска в 10 вечера и в 1 час ночи. Для сетевых инженеров сайта это важно; также важно, что они происходят рядом друг с другом (просто два часов друг от друга). Но если вы строите одни и те же данные в традиционной системе координат, этот шаблон будет полностью скрыт-строится линейно, эти два пика будут 20 часы друг от друга, что они и есть, хотя они также находятся всего в двух часах друг от друга в последовательные дни. Полярная диаграмма выше показывает это экономным и интуитивно понятным способом (легенда не нужна).
есть два способа (о которых я знаю) для создания таких участков с помощью R (я создал участок выше w/ R). Один из них-это кодирование собственной функции в базовых или сеточных графических системах. Они другой способ, который проще, это использовать круговой пакет. Функция, которую вы будете использовать это'Роза.diag':
data = c(35, 78, 34, 25, 21, 17, 22, 19, 25, 18, 25, 21, 16, 20, 26, 19, 24, 18, 23, 25, 24, 25, 71, 27) three_palettes = c(brewer.pal(12, "Set3"), brewer.pal(8, "Accent"), brewer.pal(9, "Set1")) rose.diag(data, bins=24, main="Daily Site Traffic by Hour", col=three_palettes)
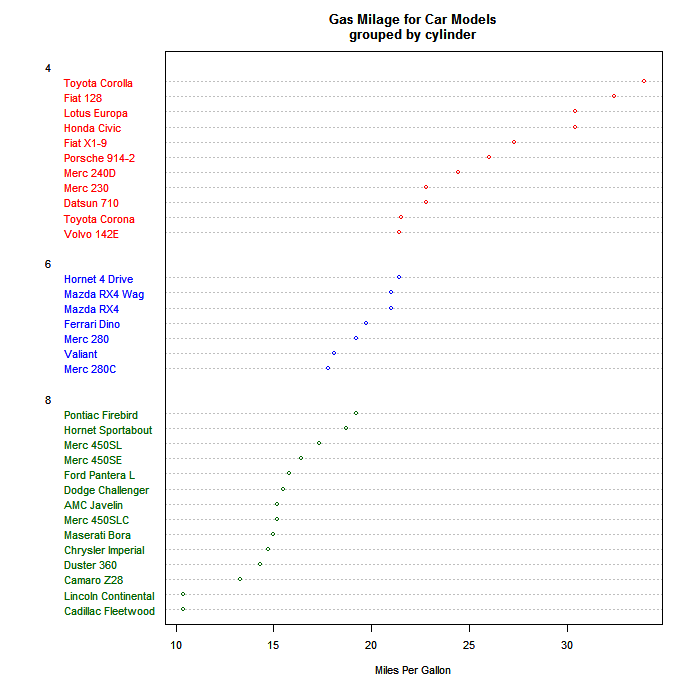
Мне очень нравится dotplots и найти, когда я рекомендую их другим для соответствующих проблем данных они неизменно удивлены и рады. Они, кажется, не очень полезны, и я не могу понять, почему.
вот пример из Quick-R:
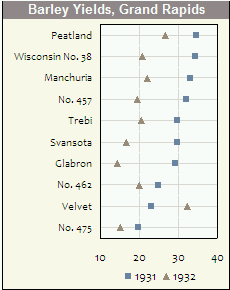
Я считаю, что Кливленд несет наибольшую ответственность за их разработку и обнародование, и пример в его книге (в которой ошибочные данные были легко обнаружены с помощью точечной диаграммы) является мощным аргументом для их использования. Обратите внимание, что приведенный выше пример ставит только одну точку на линию, тогда как их реальная сила приходит с вами, имеет несколько точек на каждой линии, с легендой, объясняющей, что есть что. Например, вы можете использовать разные символы или цвета для трех разных временных точек, а затем легко получить представление о временных шаблонах в разных категориях.
в следующем примере (сделано в Excel всех вещей!), вы можете четко видеть, какая категория могла пострадать от метки менять.
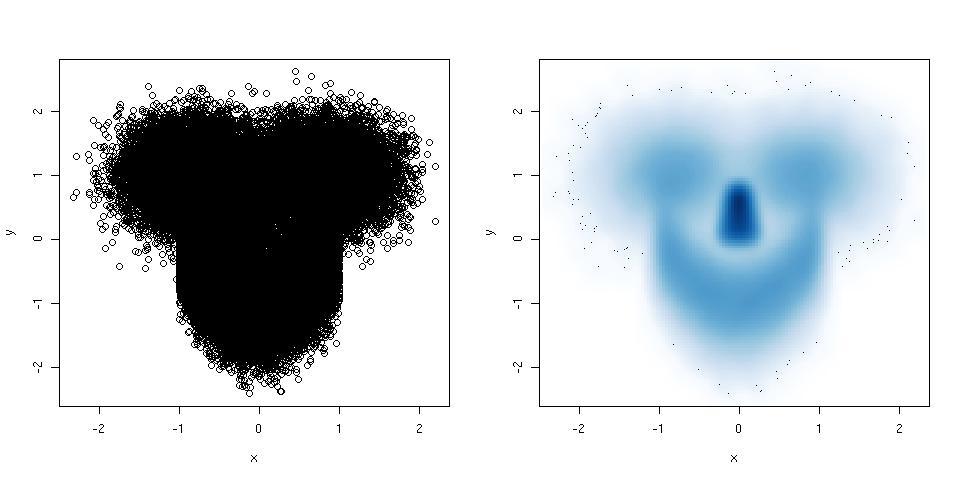
если ваш график рассеяния имеет так много точек, что он становится полным беспорядком, попробуйте сгладить график рассеяния. Вот пример:
library(mlbench) ## this package has a smiley function n <- 1e5 ## number of points p <- mlbench.smiley(n,sd1 = 0.4, sd2 = 0.4) ## make a smiley :-) x <- p$x[,1]; y <- p$x[,2] par(mfrow = c(1,2)) ## plot side by side plot(x,y) ## left plot, regular scatter plot smoothScatter(x,y) ## right plot, smoothed scatter plotThe
hexbinпакет (предложенный @Dirk Eddelbuettel) используется для той же цели, ноsmoothScatter()имеет то преимущество, что оно принадлежитgraphicsпакет, и таким образом часть стандартной установки Р.
Что касается sparkline и другой идеи Tufte, то YaleToolkit пакета CRAN функции
sparklineиsparklines.еще один пакет, который полезен для больших наборов данных является hexbin как это умно "бункеры" данные в ведра, чтобы иметь дело с наборами данных, которые могут быть слишком большими для наивных диаграмм рассеяния.
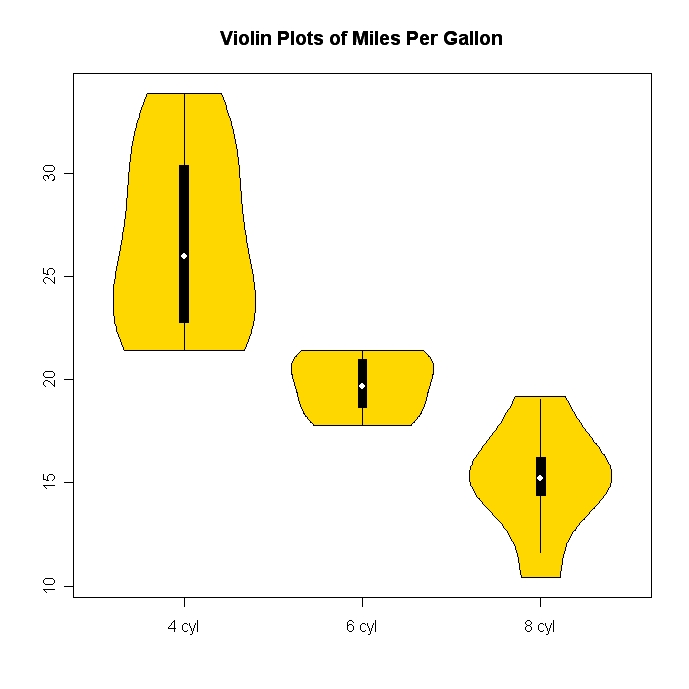
Скрипка участки (которые объединяют боксовые участки с плотностью ядра) являются относительно экзотическими и довольно прохладными. Элемент vioplot пакет в R позволяет сделать их довольно легко.
вот пример (ссылка Википедии также показывает пример):
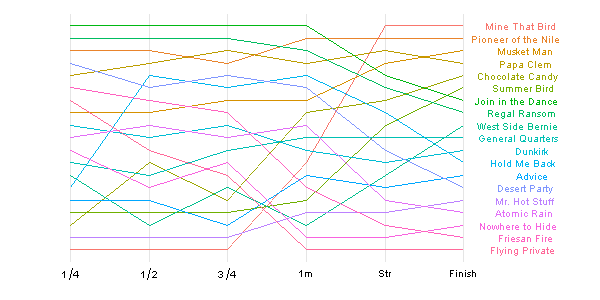
еще одна хорошая визуализация временных рядов, которую я только что просматривал, - это "bump chart" (Как показал в этот пост в блоге "Learning R"). Это очень полезно для визуализации изменений положения с течением времени.
вы можете прочитать о том, как создать его на http://learnr.wordpress.com/, но вот как это выглядит:
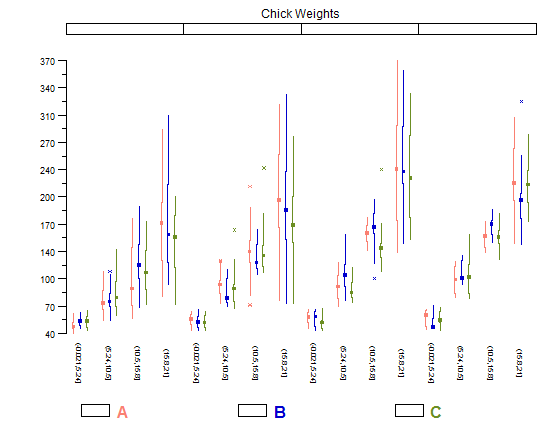
мне также нравятся модификации коробочных графиков Tufte, которые позволяют вам намного легче сравнивать небольшие кратные, потому что они очень "тонкие" по горизонтали и не загромождают сюжет избыточными чернилами. Тем не менее, он лучше всего работает с довольно большим количеством категорий; если у вас есть только несколько на участке, регулярные (Tukey) boxplots выглядят лучше, так как у них немного больше веса.
library(lattice) library(taRifx) compareplot(~weight | Diet * Time * Chick, data.frame=cw , main = "Chick Weights", box.show.mean=FALSE, box.show.whiskers=FALSE, box.show.box=FALSE )
другие способы их изготовления (включая другой вид из Тюфтей коробчатой диаграммы) являются обсуждается в этом вопросе.
графики горизонте (pdf), для визуализации многих временных рядов сразу.
параллельные координаты участков (pdf), для многомерного анализа.
Ассоциации и мозаика графики, для визуализации таблиц непредвиденных обстоятельств (см. vcd пакет)
мы не должны забывать о симпатичном и (исторически) важном сюжете стебля и листа (что туфте тоже любит!). Вы получаете непосредственно числовой обзор плотности и формы данных (конечно, если ваш набор данных не больше, чем около 200 точек). В R, функция
stemпроизводит ваш стебель и лист dislay (в рабочей области). Я предпочитаю использоватьgstemфункция из пакета fmsb чтобы привлечь его непосредственно в графическом устройстве. Ниже приводится дисперсия температуры тела бобра (данные должны быть в ваш набор данных по умолчанию) в стеблевом отображении:require(fmsb) gstem(beaver1$temp)

в дополнение к отличной работе Тафта, я рекомендую книги Уильяма С. Кливленда:Визуализация Данных и элементы графических данных. Они не только превосходны, но все они были сделаны в R, и я считаю, что код является общедоступным.
Boxplots! Пример из справки:
boxplot(count ~ spray, data = InsectSprays, col = "lightgray")на мой взгляд это самый удобный способ, чтобы быстро взглянуть на данные или сравнить дистрибутивы. Для более сложных дистрибутивов существует расширение под названием
vioplot.
мозаичные сюжеты, как мне кажется, соответствуют всем четырем упомянутым критериям. Есть примеры в r, под mosaicplot.
проверьте работу Эдварда Тафта и особенно книги
вы также можете попробовать и поймать его путешествия презентация. Это довольно хорошо и включает в себя пачку из четырех его книг. (клянусь, у меня нет акций его издателя!)
кстати, мне нравится его техника визуализации данных sparkline. Сюрприз! Google уже написал его и выложил на Код Google
Comments