Не в vs не существует
какой из этих запросов будет быстрее?
НЕ СУЩЕСТВУЕТ:
SELECT ProductID, ProductName
FROM Northwind..Products p
WHERE NOT EXISTS (
SELECT 1
FROM Northwind..[Order Details] od
WHERE p.ProductId = od.ProductId)
или не в:
SELECT ProductID, ProductName
FROM Northwind..Products p
WHERE p.ProductID NOT IN (
SELECT ProductID
FROM Northwind..[Order Details])
план выполнения запроса говорит, что они оба делают то же самое. Если это так,то какая форма рекомендуется?
это основано на базе данных NorthWind.
[Edit]
просто нашел эту полезную статью:
http://weblogs.sqlteam.com/mladenp/archive/2007/05/18/60210.aspx
Я думаю, Я буду придерживаться не существует.
10 ответов:
я всегда по умолчанию
NOT EXISTS.планы выполнения могут быть одинаковыми на данный момент, но если какой-либо столбец будет изменен в будущем, чтобы разрешить
NULLСNOT INверсия должна будет сделать больше работы (даже если нетNULLs фактически присутствуют в данных) и семантикаNOT INеслиNULLs are настоящее вряд ли будут те, которые вы хотите в любом случае.когда ни
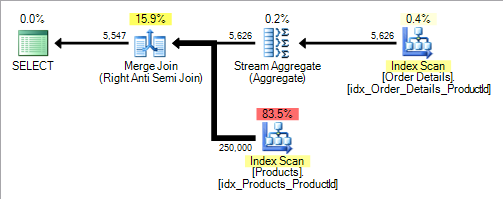
Products.ProductIDили[Order Details].ProductIDразрешитьNULLСNOT INбудем лечиться тождественно следующему запросу.SELECT ProductID, ProductName FROM Products p WHERE NOT EXISTS (SELECT * FROM [Order Details] od WHERE p.ProductId = od.ProductId)точный план может отличаться, но для моего примера данных я получаю следующее.
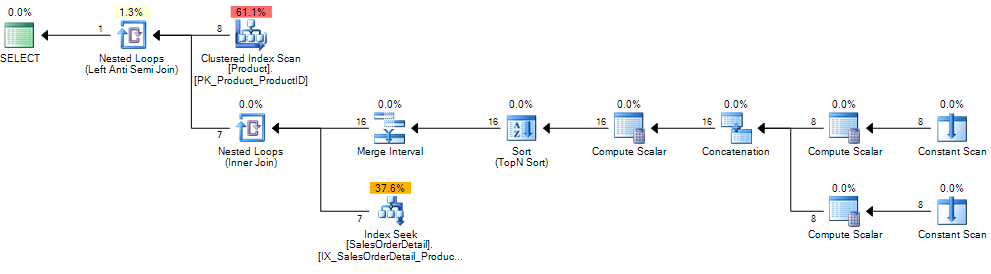
довольно распространенное заблуждение заключается в том, что коррелированные подзапросы всегда "плохи" по сравнению с соединениями. Они, конечно, могут быть, когда они заставляют план вложенных циклов (подзапрос оценивается строка за строкой), но этот план включает в себя логический оператор anti semi join. Анти полуобъединения не ограничиваются вложенными циклами, но также можно использовать хэш или слияние (как в этом примере).
/*Not valid syntax but better reflects the plan*/ SELECT p.ProductID, p.ProductName FROM Products p LEFT ANTI SEMI JOIN [Order Details] od ON p.ProductId = od.ProductIdесли
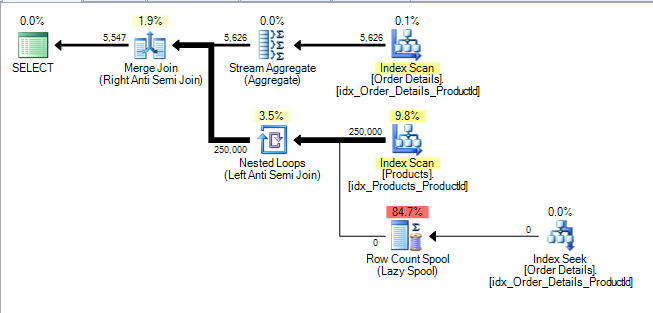
[Order Details].ProductIDиNULL- способный запрос тогда становитсяSELECT ProductID, ProductName FROM Products p WHERE NOT EXISTS (SELECT * FROM [Order Details] od WHERE p.ProductId = od.ProductId) AND NOT EXISTS (SELECT * FROM [Order Details] WHERE ProductId IS NULL)причина этого в том, что правильная семантика если
[Order Details]содержитNULLProductIds не возвращает никаких результатов. См. дополнительную катушку Anti semi join и Row count, чтобы проверить это, добавленное в план.
если
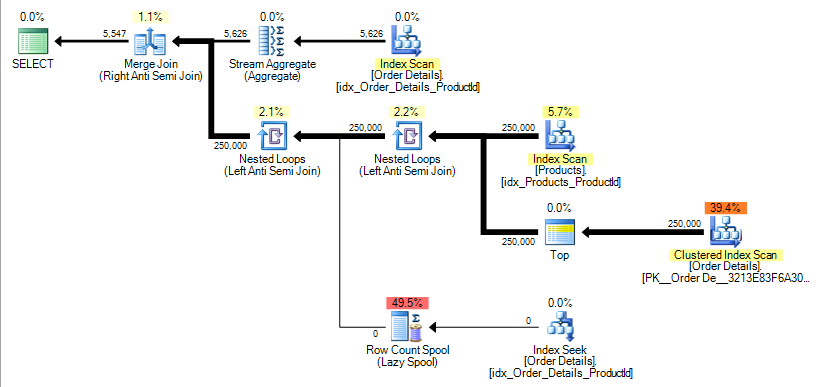
Products.ProductIDтакже изменяется, чтобы статьNULL-возможность запроса тогда становитсяSELECT ProductID, ProductName FROM Products p WHERE NOT EXISTS (SELECT * FROM [Order Details] od WHERE p.ProductId = od.ProductId) AND NOT EXISTS (SELECT * FROM [Order Details] WHERE ProductId IS NULL) AND NOT EXISTS (SELECT * FROM (SELECT TOP 1 * FROM [Order Details]) S WHERE p.ProductID IS NULL)причина этого в том, что a
NULLProducts.ProductIdне должны быть возвращены в результатах за исключением еслиNOT INsub запрос не должен был возвращать никаких результатов вообще (т. е.[Order Details]таблица пуста). В таком случае это должно быть так. В плане для моих примерных данных это реализуется путем добавления другого анти-полу-соединения, как показано ниже.
эффект этого показан в сообщение в блоге уже связаны Бакли. В приведенном примере количество логических операций чтения увеличивается примерно с 400 до 500 000.
дополнительно тот факт, что один
NULLможет уменьшить количество строк до нуля делает оценку мощности очень трудно. Если SQL Server предполагает, что это произойдет, но на самом деле не былоNULLстроки в данных остальная часть плана выполнения может быть катастрофически хуже, если это просто часть большего запроса,с неуместными вложенными циклами вызывая повторное выполнение дорогостоящего поддерева например.это не единственный возможный план выполнения для A
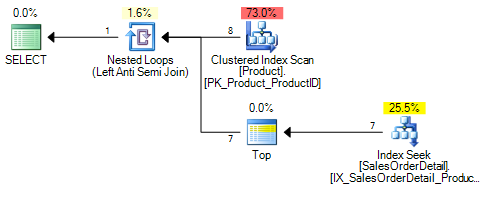
NOT INнаNULL-в состоянии однако колонке. эта статья показывает еще один на запрос от илиNOT EXISTSпротив столбца с нулевым или ненулевым значением он дает следующий план.
при изменении столбца к
NULL-возможностьNOT INплан теперь выглядит как
он добавляет дополнительный внутренний оператор соединения к плану. Этот аппарат пояснил, что. Это все там, чтобы преобразовать предыдущий один коррелированный индекс искать на
Sales.SalesOrderDetail.ProductID = <correlated_product_id>до двух поисков на внешнюю строку. Дополнительный находится наWHERE Sales.SalesOrderDetail.ProductID IS NULL.поскольку это находится под анти-полу-соединением, если это возвращает какие-либо строки, второй поиск не произойдет. Однако если
Sales.SalesOrderDetailне содержат любыеNULLProductIDs это удвоит количество операций поиска, необходимых.
также имейте в виду, что NOT IN не эквивалентно NOT EXISTS, когда дело доходит до null.
этот пост объясняет это очень хорошо
http://sqlinthewild.co.za/index.php/2010/02/18/not-exists-vs-not-in/
когда подзапрос возвращает даже один null, NOT IN не будет соответствовать ни одному строки.
причину этого можно найти, посмотрев на детали того, что Не в действии на самом деле означает.
скажем, для иллюстрации, что есть 4 строки в таблица называется t, есть столбец с именем ID со значениями 1..4
WHERE SomeValue NOT IN (SELECT AVal FROM t)эквивалентно
WHERE SomeValue != (SELECT AVal FROM t WHERE ID=1) AND SomeValue != (SELECT AVal FROM t WHERE ID=2) AND SomeValue != (SELECT AVal FROM t WHERE ID=3) AND SomeValue != (SELECT AVal FROM t WHERE ID=4)далее скажем, что AVal равен нулю, где ID = 4. Следовательно, что != сравнение возвращает значение Unknown. Логическая таблица истинности для и состояний неизвестно, что и правда, неизвестно, неизвестно, а ложь-ложью. Есть нет значения, которое может быть AND'D с неизвестным, чтобы получить результат TRUE
следовательно, если какая-либо строка этого подзапроса возвращает NULL, то весь NOT IN оператор будет возвращать false или null, а записи не будет вернулся
если планировщик выполнения говорит, что они одинаковы, они одинаковы. Используйте то, что сделает ваше намерение более очевидным-в данном случае второе.
на самом деле, я считаю, что это было бы самым быстрым:
SELECT ProductID, ProductName FROM Northwind..Products p outer join Northwind..[Order Details] od on p.ProductId = od.ProductId) WHERE od.ProductId is null
у меня есть таблица, которая имеет около 120 000 записей и нужно выбрать только те, которые не существуют (соответствует varchar столбец) в четырех других таблицах с количеством строк около 1500, 4000, 40000, 200. Все вовлеченные таблицы имеют уникальный индекс на соответствующем .
NOT INзаняло около 10 минут,NOT EXISTSушло 4 секунды.у меня есть рекурсивный запрос, который мог бы иметь какой-то не настроенный раздел, который мог бы внести свой вклад в 10 минут, но другой вариант, занимающий 4 секунды, объясняет, по крайней мере, мне это
NOT EXISTSгораздо лучше или, по крайней мере, чтоINиEXISTSне совсем то же самое и всегда стоит проверить, прежде чем идти вперед с кодом.
в вашем конкретном примере они одинаковы, потому что оптимизатор выяснил, что вы пытаетесь сделать то же самое в обоих примерах. Но вполне возможно, что в нетривиальных примерах оптимизатор может этого не делать, и в этом случае есть причины Иногда предпочитать одно другому.
NOT INдолжно быть предпочтительным, если вы тестируете несколько строк в ваш внешний выбор. Подзапрос внутриNOT INоператор может быть вычислен в начале выполнения, и временная таблица может быть проверена по каждому значению во внешнем select, а не повторно запускать подвыборку каждый раз, как это требуется сNOT EXISTSзаявление.если подзапрос должны соотносится с внешним выбором, затем
NOT EXISTSможет быть предпочтительнее, так как оптимизатор может обнаружить упрощение, которое предотвращает создание любых временных таблиц для выполнения той же функции.
Я был с помощью
SELECT * from TABLE1 WHERE Col1 NOT IN (SELECT Col1 FROM TABLE2)и обнаружил, что он дает неправильные результаты (под неправильным я подразумеваю отсутствие результатов). Поскольку в таблице 2 был NULL.На col1.
при изменении запроса
SELECT * from TABLE1 T1 WHERE NOT EXISTS (SELECT Col1 FROM TABLE2 T2 WHERE T1.Col1 = T2.Col2)дал мне правильные результаты.
С тех пор я начал использовать не существует везде.
Они очень похожи, но не одинаковы.
с точки зрения эффективности, я нашел левое соединение равно null оператор более эффективный (когда необходимо выбрать обилие строк)
если оптимизатор говорит, что они одинаковы, то рассмотрим человеческий фактор. Я предпочитаю видеть не существует :)
Это зависит..
SELECT x.col FROM big_table x WHERE x.key IN( SELECT key FROM really_big_table );не было бы относительно медленным, чтобы не сильно ограничивать размер того, что проверяет запрос, чтобы увидеть, есть ли у них ключ. Существует было бы предпочтительнее в этом случае.
но, в зависимости от оптимизатора СУБД, это не может быть иначе.
в качестве примера, когда существует лучше
SELECT x.col FROM big_table x WHERE EXISTS( SELECT key FROM really_big_table WHERE key = x.key); AND id = very_limiting_criteria
Comments