7 ответов:
Это немного быстрее (и выглядит лучше)
np.argmax(aa>5)С
argmaxостановится на первомTrue("в случае нескольких вхождений максимальных значений возвращаются индексы, соответствующие первому вхождению.") и не сохраняет другой список.In [2]: N = 10000 In [3]: aa = np.arange(-N,N) In [4]: timeit np.argmax(aa>N/2) 100000 loops, best of 3: 52.3 us per loop In [5]: timeit np.where(aa>N/2)[0][0] 10000 loops, best of 3: 141 us per loop In [6]: timeit np.nonzero(aa>N/2)[0][0] 10000 loops, best of 3: 142 us per loop
учитывая отсортированное содержимое вашего массива, есть еще более быстрый метод: searchsorted.
import time N = 10000 aa = np.arange(-N,N) %timeit np.searchsorted(aa, N/2)+1 %timeit np.argmax(aa>N/2) %timeit np.where(aa>N/2)[0][0] %timeit np.nonzero(aa>N/2)[0][0] # Output 100000 loops, best of 3: 5.97 µs per loop 10000 loops, best of 3: 46.3 µs per loop 10000 loops, best of 3: 154 µs per loop 10000 loops, best of 3: 154 µs per loop
In [34]: a=np.arange(-10,10) In [35]: a Out[35]: array([-10, -9, -8, -7, -6, -5, -4, -3, -2, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9]) In [36]: np.where(a>5) Out[36]: (array([16, 17, 18, 19]),) In [37]: np.where(a>5)[0][0] Out[37]: 16
Я тоже был заинтересован в этом и я сравнил все предложенные ответы с perfplot. (Отказ от ответственности: я автор perfplot.)
Если вы знаете, что массив, который вы просматриваете,уже отсортированный, потом
numpy.searchsorted(a, alpha)- это для вас. Это операция с постоянным временем, т. е. скорость делает не зависит от размера массива. Вы не можете получить быстрее, чем.
Если вы ничего не знаете о Ваш массив, вы не ошибетесь с
numpy.argmax(a > alpha)уже разобрались:
несортированный:
код для воспроизведения сюжета:
import numpy import perfplot alpha = 0.5 def argmax(data): return numpy.argmax(data > alpha) def where(data): return numpy.where(data > alpha)[0][0] def nonzero(data): return numpy.nonzero(data > alpha)[0][0] def searchsorted(data): return numpy.searchsorted(data, alpha) out = perfplot.show( # setup=numpy.random.rand, setup=lambda n: numpy.sort(numpy.random.rand(n)), kernels=[ argmax, where, nonzero, searchsorted ], n_range=[2**k for k in range(2, 20)], logx=True, logy=True, xlabel='len(array)' )
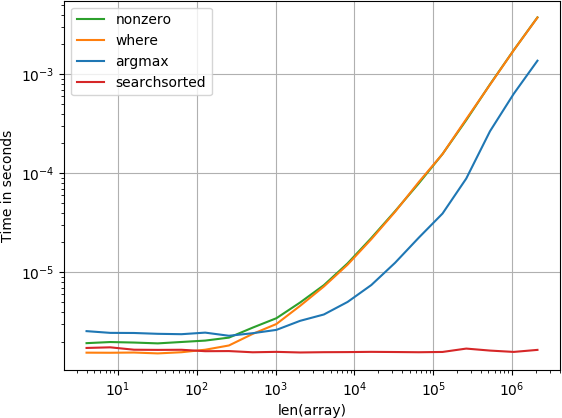
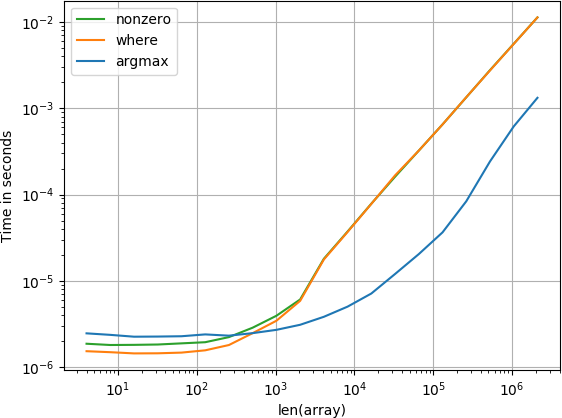
массивы, которые имеют постоянный шаг между элементами
в случае
rangeили любой другой линейно увеличивающийся массив вы можете просто вычислить индекс программно, не нужно на самом деле перебирать массив вообще:def first_index_calculate_range_like(val, arr): if len(arr) == 0: raise ValueError('no value greater than {}'.format(val)) elif len(arr) == 1: if arr[0] > val: return 0 else: raise ValueError('no value greater than {}'.format(val)) first_value = arr[0] step = arr[1] - first_value # For linearly decreasing arrays or constant arrays we only need to check # the first element, because if that does not satisfy the condition # no other element will. if step <= 0: if first_value > val: return 0 else: raise ValueError('no value greater than {}'.format(val)) calculated_position = (val - first_value) / step if calculated_position < 0: return 0 elif calculated_position > len(arr) - 1: raise ValueError('no value greater than {}'.format(val)) return int(calculated_position) + 1можно было бы, вероятно, немного улучшить это. Я убедился, что он работает правильно для нескольких образцов массивов и значений, но это не значит, что там не может быть ошибок, особенно учитывая, что он использует поплавки...
>>> import numpy as np >>> first_index_calculate_range_like(5, np.arange(-10, 10)) 16 >>> np.arange(-10, 10)[16] # double check 6 >>> first_index_calculate_range_like(4.8, np.arange(-10, 10)) 15учитывая, что он может вычислить позицию без каких-либо итераций, это будет постоянное время (
O(1)) и, вероятно, может превзойти все другие упомянутые подходы. Однако для этого требуется постоянный шаг в массиве, иначе он приведет к неправильным результатам.общее решение с помощью numba
более общий подход будет использовать функцию numba:
@nb.njit def first_index_numba(val, arr): for idx in range(len(arr)): if arr[idx] > val: return idx return -1это будет работать для любого массива, но он должен перебирать массив, так что в среднем случае это будет
O(n):>>> first_index_numba(4.8, np.arange(-10, 10)) 15 >>> first_index_numba(5, np.arange(-10, 10)) 16Benchmark
несмотря на то, что Нико Шлемер уже предоставил некоторые критерии, я подумал, что было бы полезно включить мои новые решения и протестировать их на разные "значения".
настройки тест:
import numpy as np import math import numba as nb def first_index_using_argmax(val, arr): return np.argmax(arr > val) def first_index_using_where(val, arr): return np.where(arr > val)[0][0] def first_index_using_nonzero(val, arr): return np.nonzero(arr > val)[0][0] def first_index_using_searchsorted(val, arr): return np.searchsorted(arr, val) + 1 def first_index_using_min(val, arr): return np.min(np.where(arr > val)) def first_index_calculate_range_like(val, arr): if len(arr) == 0: raise ValueError('empty array') elif len(arr) == 1: if arr[0] > val: return 0 else: raise ValueError('no value greater than {}'.format(val)) first_value = arr[0] step = arr[1] - first_value if step <= 0: if first_value > val: return 0 else: raise ValueError('no value greater than {}'.format(val)) calculated_position = (val - first_value) / step if calculated_position < 0: return 0 elif calculated_position > len(arr) - 1: raise ValueError('no value greater than {}'.format(val)) return int(calculated_position) + 1 @nb.njit def first_index_numba(val, arr): for idx in range(len(arr)): if arr[idx] > val: return idx return -1 funcs = [ first_index_using_argmax, first_index_using_min, first_index_using_nonzero, first_index_calculate_range_like, first_index_numba, first_index_using_searchsorted, first_index_using_where ] from simple_benchmark import benchmark, MultiArgumentи графики были созданы с помощью:
%matplotlib notebook b.plot()пункт находится в начале
b = benchmark( funcs, {2**i: MultiArgument([0, np.arange(2**i)]) for i in range(2, 20)}, argument_name="array size")
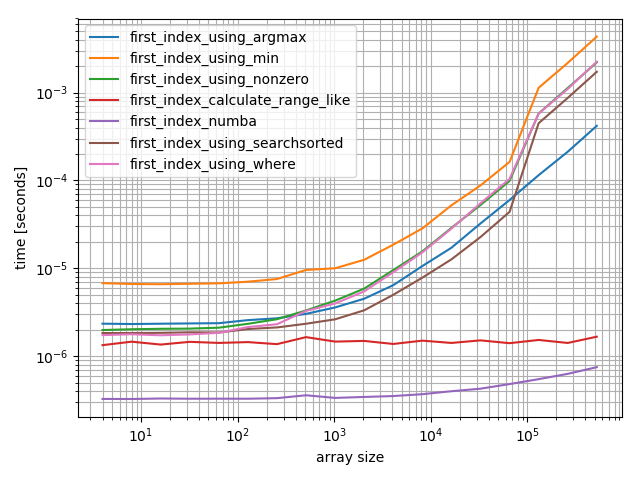
в функция numba лучше всего выполняет функцию calculate-function и функцию searchsorted. Другие решения работают гораздо хуже.
пункт находится в конце
b = benchmark( funcs, {2**i: MultiArgument([2**i-2, np.arange(2**i)]) for i in range(2, 20)}, argument_name="array size")
для небольших массивов функция numba работает удивительно быстро, однако для больших массивов она превосходит функцию calculate-function и функцию searchsorted.
пункт в sqrt (len)
b = benchmark( funcs, {2**i: MultiArgument([np.sqrt(2**i), np.arange(2**i)]) for i in range(2, 20)}, argument_name="array size")
это более интересно. Опять же numba и функция calculate отлично работают, однако это на самом деле вызывает наихудший случай поиска, который действительно не работает хорошо в этом случае.
сравнение функций, когда ни одно значение не удовлетворяет условию
еще один интересный момент заключается в том, как эти функции ведут себя, если нет значения, индекс которого должен быть вернулся:
arr = np.ones(100) value = 2 for func in funcs: print(func.__name__) try: print('-->', func(value, arr)) except Exception as e: print('-->', e)С таким результатом:
first_index_using_argmax --> 0 first_index_using_min --> zero-size array to reduction operation minimum which has no identity first_index_using_nonzero --> index 0 is out of bounds for axis 0 with size 0 first_index_calculate_range_like --> no value greater than 2 first_index_numba --> -1 first_index_using_searchsorted --> 101 first_index_using_where --> index 0 is out of bounds for axis 0 with size 0Searchsorted, argmax и numba просто возвращают неверное значение. Однако
searchsortedиnumbaвернуть индекс, который не является допустимым индексом для массива.функции
where,min,nonzeroиcalculateбросать исключение. Однако только исключение дляcalculateна самом деле говорит что-нибудь полезное.это означает, что на самом деле нужно обернуть эти вызовы в соответствующем функция-оболочка, которая ловит исключения или недопустимые возвращаемые значения и обрабатывает соответствующим образом, по крайней мере, если вы не уверены, что значение может быть в массиве.
Примечание: вычислить и
searchsortedопции работают только в особых условиях. Функция "вычислить" требует постоянного шага, а функция searchsorted требует сортировки массива. Так что они могут быть полезны в нужных обстоятельствах, но не общие решения этой проблемы. На случай, если ты ... дело с отсортированный Python списки вы можете взглянуть на разделить пополам модуль вместо использования numpys searchsorted.
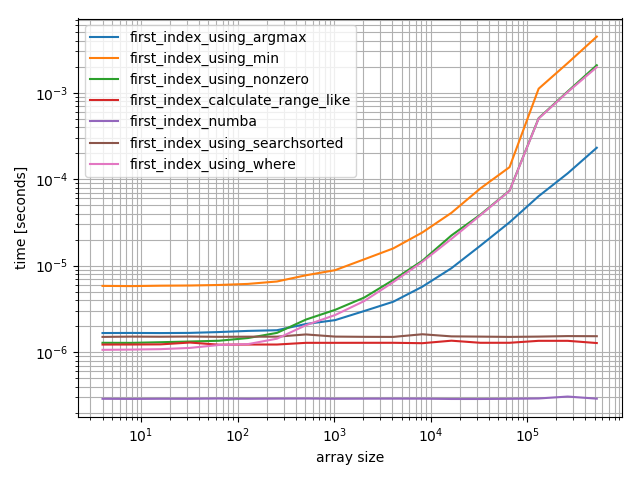
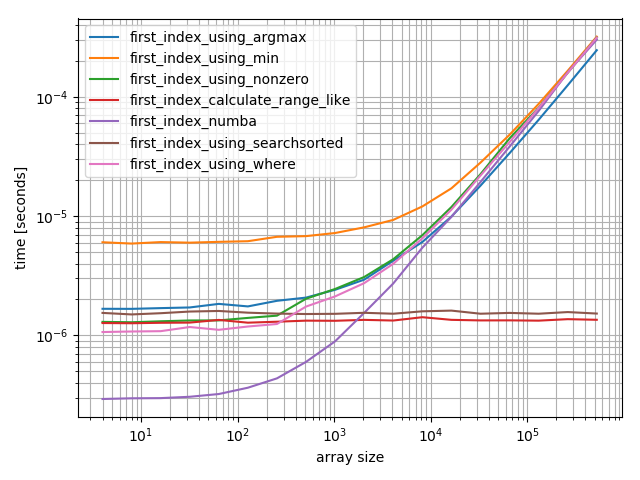
Я бы поехал с
i = np.min(np.where(V >= x))здесь
Vвектор (1D массив),xиi- это результирующий показатель.
Я хотел бы предложить
np.min(np.append(np.where(aa>5)[0],np.inf))это вернет наименьший индекс, где выполняется условие, при этом возвращая бесконечность, если условие никогда не выполняется (и
whereвозвращает пустой массив).
Comments