Распознавание образов во временных рядах [закрыто]
обрабатывая график временных рядов, я хотел бы обнаружить шаблоны, которые выглядят примерно так:

используя пример временного ряда в качестве примера, я хотел бы иметь возможность обнаруживать шаблоны, отмеченные здесь:
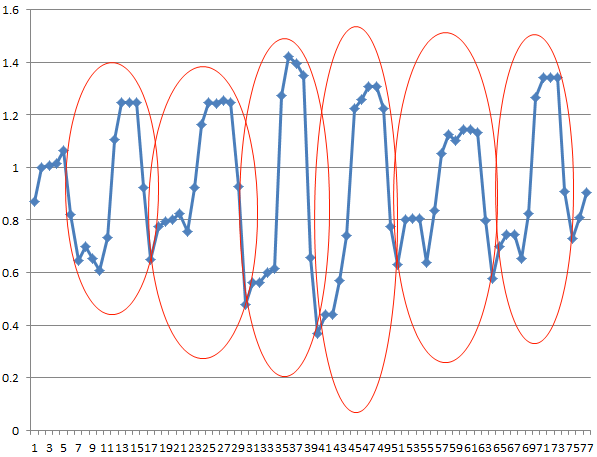
какой алгоритм AI (я предполагаю, что методы обучения marchine) мне нужно использовать для достижения этого? Есть ли там какая-нибудь библиотека (в C/C++), которую я могу использовать?
5 ответов:
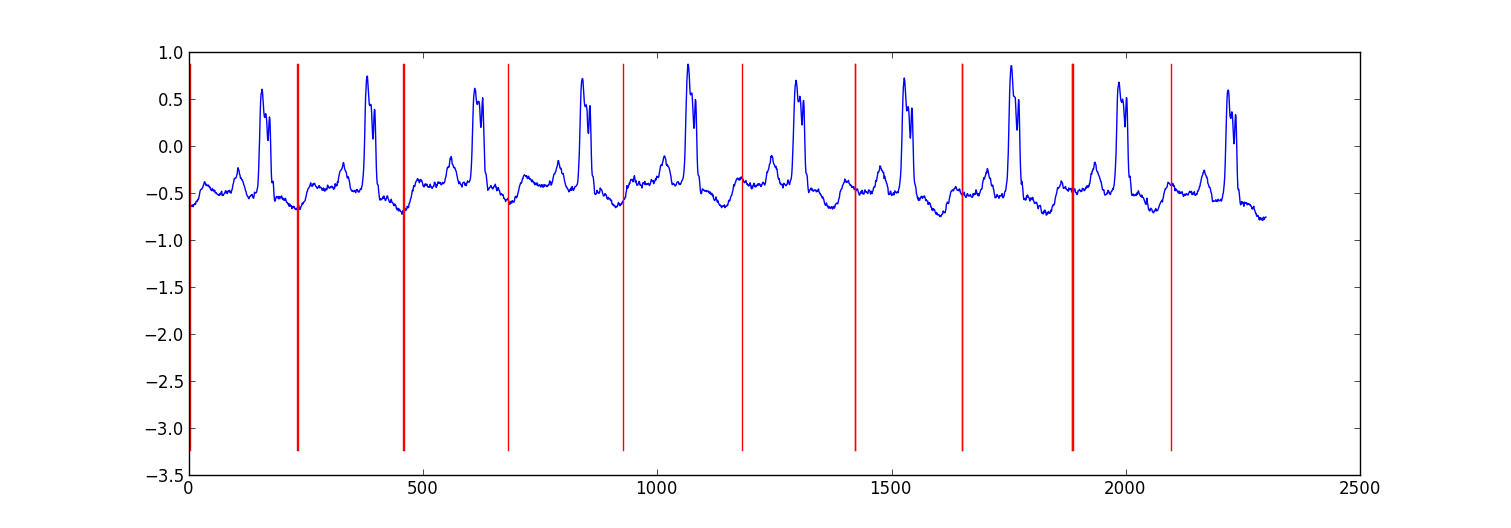
вот пример результата из небольшого проекта, который я сделал для разделения данных ЭКГ.
мой подход был "переключающим авторегрессионным HMM" (google это, если вы об этом не слышали), где каждая точка данных предсказывается из предыдущей точки данных с использованием модели Байесовской регрессии. Я создал 81 скрытое состояние: нежелательное состояние для захвата данных между каждым ударом и 80 отдельных скрытых состояний, соответствующих различным позициям в шаблоне сердцебиения. Узор 80 состояний были построены непосредственно из подвыборки одного такта шаблона и имели два перехода - самопроизвольный переход и переход к следующему состоянию в шаблоне. Конечное состояние в шаблоне переходило либо в само состояние, либо в состояние нежелательной почты.
я обучил модель с обучение Витерби обновление только параметров регрессии.
результаты были адекватны в большинстве случаев. Аналогичная структура условного случайного поля, вероятно, будет работать лучше, но для обучения CRF потребуется вручную маркировать шаблоны в наборе данных, если у вас еще нет маркированных данных.
Edit:
вот пример кода python - он не идеален, но дает общий подход. Он реализует ЭМ, а не тренировку Витерби, которая может быть немного более стабильной. Набор данных ЭКГ от http://www.cs.ucr.edu / ~eamonn/discords/ECG_data.zip
import numpy as np import numpy.random as rnd import matplotlib.pyplot as plt import scipy.linalg as lin import re data=np.array(map(lambda l: map(float,filter(lambda x: len(x)>0,re.split('\s+',l))),open('chfdb_chf01_275.txt'))).T dK=230 pattern=data[1,:dK] data=data[1,dK:] def create_mats(dat): ''' create A - an initial transition matrix pA - pseudocounts for A w - emission distribution regression weights K - number of hidden states ''' step=5 #adjust this to change the granularity of the pattern eps=.1 dat=dat[::step] K=len(dat)+1 A=np.zeros( (K,K) ) A[0,1]=1. pA=np.zeros( (K,K) ) pA[0,1]=1. for i in xrange(1,K-1): A[i,i]=(step-1.+eps)/(step+2*eps) A[i,i+1]=(1.+eps)/(step+2*eps) pA[i,i]=1. pA[i,i+1]=1. A[-1,-1]=(step-1.+eps)/(step+2*eps) A[-1,1]=(1.+eps)/(step+2*eps) pA[-1,-1]=1. pA[-1,1]=1. w=np.ones( (K,2) , dtype=np.float) w[0,1]=dat[0] w[1:-1,1]=(dat[:-1]-dat[1:])/step w[-1,1]=(dat[0]-dat[-1])/step return A,pA,w,K #initialize stuff A,pA,w,K=create_mats(pattern) eta=10. #precision parameter for the autoregressive portion of the model lam=.1 #precision parameter for the weights prior N=1 #number of sequences M=2 #number of dimensions - the second variable is for the bias term T=len(data) #length of sequences x=np.ones( (T+1,M) ) # sequence data (just one sequence) x[0,1]=1 x[1:,0]=data #emissions e=np.zeros( (T,K) ) #residuals v=np.zeros( (T,K) ) #store the forward and backward recurrences f=np.zeros( (T+1,K) ) fls=np.zeros( (T+1) ) f[0,0]=1 b=np.zeros( (T+1,K) ) bls=np.zeros( (T+1) ) b[-1,1:]=1./(K-1) #hidden states z=np.zeros( (T+1),dtype=np.int ) #expected hidden states ex_k=np.zeros( (T,K) ) # expected pairs of hidden states ex_kk=np.zeros( (K,K) ) nkk=np.zeros( (K,K) ) def fwd(xn): global f,e for t in xrange(T): f[t+1,:]=np.dot(f[t,:],A)*e[t,:] sm=np.sum(f[t+1,:]) fls[t+1]=fls[t]+np.log(sm) f[t+1,:]/=sm assert f[t+1,0]==0 def bck(xn): global b,e for t in xrange(T-1,-1,-1): b[t,:]=np.dot(A,b[t+1,:]*e[t,:]) sm=np.sum(b[t,:]) bls[t]=bls[t+1]+np.log(sm) b[t,:]/=sm def em_step(xn): global A,w,eta global f,b,e,v global ex_k,ex_kk,nkk x=xn[:-1] #current data vectors y=xn[1:,:1] #next data vectors predicted from current #compute residuals v=np.dot(x,w.T) # (N,K) <- (N,1) (N,K) v-=y e=np.exp(-eta/2*v**2,e) fwd(xn) bck(xn) # compute expected hidden states for t in xrange(len(e)): ex_k[t,:]=f[t+1,:]*b[t+1,:] ex_k[t,:]/=np.sum(ex_k[t,:]) # compute expected pairs of hidden states for t in xrange(len(f)-1): ex_kk=A*f[t,:][:,np.newaxis]*e[t,:]*b[t+1,:] ex_kk/=np.sum(ex_kk) nkk+=ex_kk # max w/ respect to transition probabilities A=pA+nkk A/=np.sum(A,1)[:,np.newaxis] # solve the weighted regression problem for emissions weights # x and y are from above for k in xrange(K): ex=ex_k[:,k][:,np.newaxis] dx=np.dot(x.T,ex*x) dy=np.dot(x.T,ex*y) dy.shape=(2) w[k,:]=lin.solve(dx+lam*np.eye(x.shape[1]), dy) #return the probability of the sequence (computed by the forward algorithm) return fls[-1] if __name__=='__main__': #run the em algorithm for i in xrange(20): print em_step(x) #get rough boundaries by taking the maximum expected hidden state for each position r=np.arange(len(ex_k))[np.argmax(ex_k,1)<3] #plot plt.plot(range(T),x[1:,0]) yr=[np.min(x[:,0]),np.max(x[:,0])] for i in r: plt.plot([i,i],yr,'-r') plt.show()
почему бы не использовать простой согласованный фильтр? Или его общий статистический аналог называется перекрестной корреляцией. Учитывая известный шаблон x (t) и шумный составной временной ряд, содержащий ваш шаблон, сдвинутый в a, b,..., z как
y(t) = x(t-a) + x(t-b) +...+ x(t-z) + n(t).функция взаимной корреляции между x и y должна давать пики в a,b, ..., z
Weka представляет собой мощную коллекцию программного обеспечения для машинного обучения и поддерживает некоторые инструменты анализа временных рядов, но я не знаю достаточно о поле, чтобы рекомендовать лучший метод. Однако он основан на Java; и вы можете вызов кода Java из C / C++ без большой суеты.
пакеты для манипуляций с временными рядами в основном направлены на фондовый рынок. Я предложил Кронос в комментариях; я понятия не имею, как это сделать распознавание с его помощью, помимо очевидного: любая хорошая модель длины вашей серии должна быть в состоянии предсказать, что после небольших ударов на определенном расстоянии до последнего небольшого удара следуют большие удары. То есть ваша серия демонстрирует самоподобие, и модели, используемые в Cronos, предназначены для ее моделирования.
Если вы не возражаете против C#, вы должны запросить версию TimeSearcher2 от людей в hcil-распознавание образов для этой системы рисует, как выглядит шаблон, и затем проверьте, является ли ваша модель достаточно общей, чтобы захватить большинство экземпляров с низкой ложноположительной скоростью. Вероятно, самый удобный подход вы найдете; все остальные требуют довольно фона в статистике или стратегии распознавания образов.
Я не уверен, что пакет будет работать лучше для этого. Я сделал что-то подобное в какой-то момент в колледже, где я попытался автоматически обнаружить некоторые похожие формы на оси x-y для группы разных графиков. Вы могли бы сделать нечто вроде следующего.
метки классов, такие как:
- нет класс
- начало области
- маленький
- конец области
функции например:
- относительная y-осевая относительная и абсолютная разность каждого из окружающие точки в окне шириной 11 точек
- функции как разница от среднего
- относительная разница между точкой до, точкой после
Я использую глубокое изучение, если это вариант для вас. Это делается на Java,Deeplearning4j. Я экспериментирую с LSTM. Я попробовал 1 скрытый слой и 2 скрытых слоя для обработки временных рядов.
return new NeuralNetConfiguration.Builder() .seed(HyperParameter.seed) .iterations(HyperParameter.nItr) .miniBatch(false) .learningRate(HyperParameter.learningRate) .biasInit(0) .weightInit(WeightInit.XAVIER) .momentum(HyperParameter.momentum) .optimizationAlgo( OptimizationAlgorithm.STOCHASTIC_GRADIENT_DESCENT // RMSE: ???? ) .regularization(true) .updater(Updater.RMSPROP) // NESTEROVS // .l2(0.001) .list() .layer(0, new GravesLSTM.Builder().nIn(HyperParameter.numInputs).nOut(HyperParameter.nHNodes_1).activation("tanh").build()) .layer(1, new GravesLSTM.Builder().nIn(HyperParameter.nHNodes_1).nOut(HyperParameter.nHNodes_2).dropOut(HyperParameter.dropOut).activation("tanh").build()) .layer(2, new GravesLSTM.Builder().nIn(HyperParameter.nHNodes_2).nOut(HyperParameter.nHNodes_2).dropOut(HyperParameter.dropOut).activation("tanh").build()) .layer(3, // "identity" make regression output new RnnOutputLayer.Builder(LossFunctions.LossFunction.MSE).nIn(HyperParameter.nHNodes_2).nOut(HyperParameter.numOutputs).activation("identity").build()) // "identity" .backpropType(BackpropType.TruncatedBPTT) .tBPTTBackwardLength(100) .pretrain(false) .backprop(true) .build();нашел несколько вещей:
- LSTM или RNN очень хороши в выборе шаблонов во временных рядах.
- пробовал на одном временном ряду, и группа различных временных рядов. Картина была выбрана вне легко.
- он также пытается выбирайте шаблоны не только для одной каденции. Если есть шаблоны по неделям и месяцам, оба будут изучены сетью.
Comments