Производительность ConcurrentHashmap vs HashMap
Как производительность ConcurrentHashMap по сравнению с HashMap, особенно .получить () операции (я особенно заинтересован в случае только нескольких элементов, в диапазоне от, может быть, 0-5000)?
есть ли причина не использовать ConcurrentHashMap вместо HashMap?
(Я знаю, что пустые значения не допускаются)
обновление
просто чтобы уточнить, очевидно, что производительность в случае фактического параллельного доступа будет страдать, но как сравнить производительность в случае отсутствия параллельного доступа?
7 ответов:
я был очень удивлен, обнаружив, что эта тема настолько стара, и все же никто еще не предоставил никаких тестов по этому делу. Используя
ScalaMeterЯ создал тестыadd,getиremoveдляHashMapиConcurrentHashMapв двух случаях:
- С помощью одной нити
- использовать столько потоков, сколько у меня ядер. обратите внимание, что потому что
HashMapне является потокобезопасным, я просто создал отдельнуюHashMapдля каждого потока, но используется один, общийConcurrentHashMap.код на мой РЕПО.
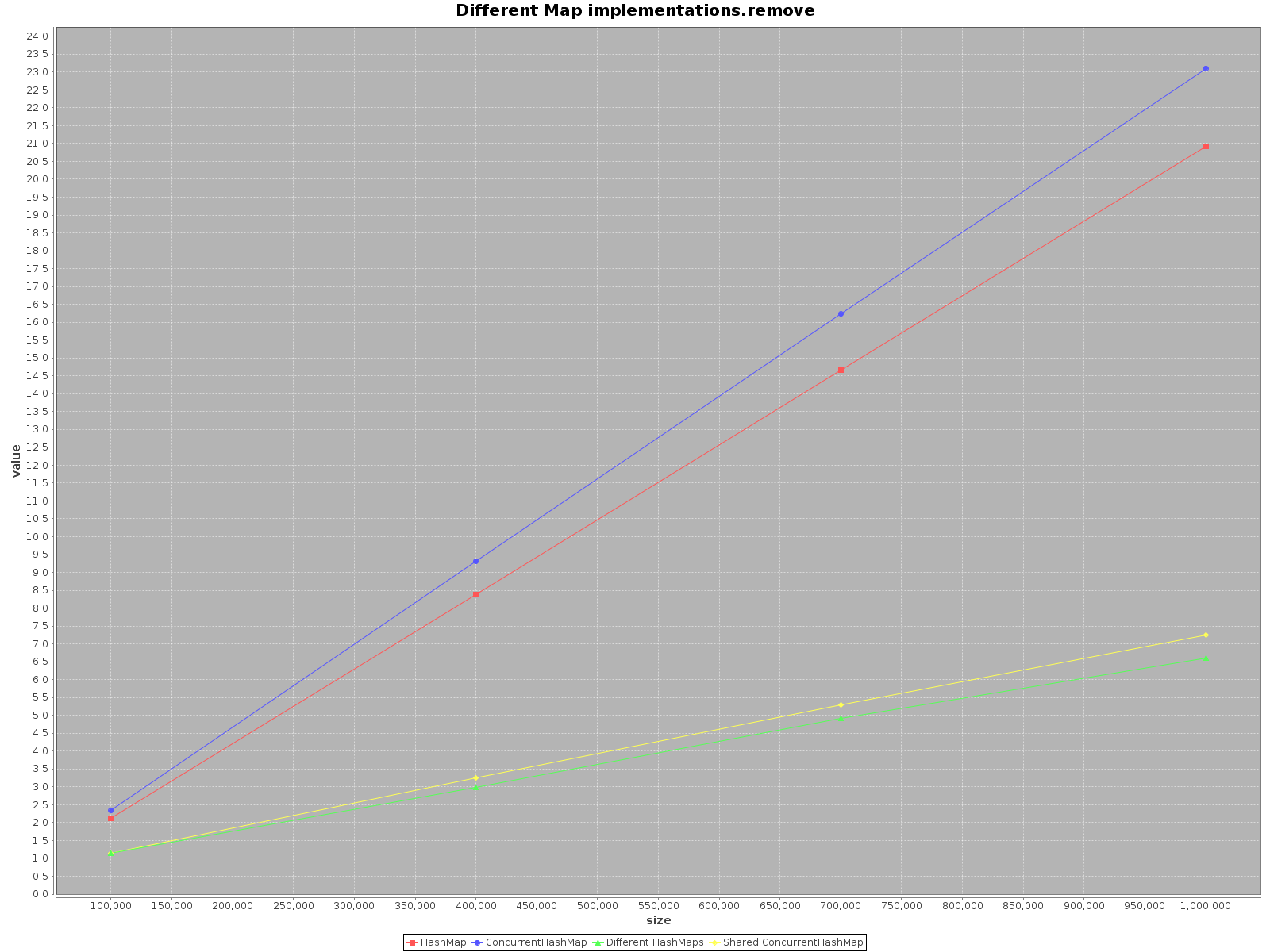
результаты следующие:
- ось X (размер) представляет количество элементов, записанных на карту(ы)
- ось Y (значение) представляет время в миллисекундах
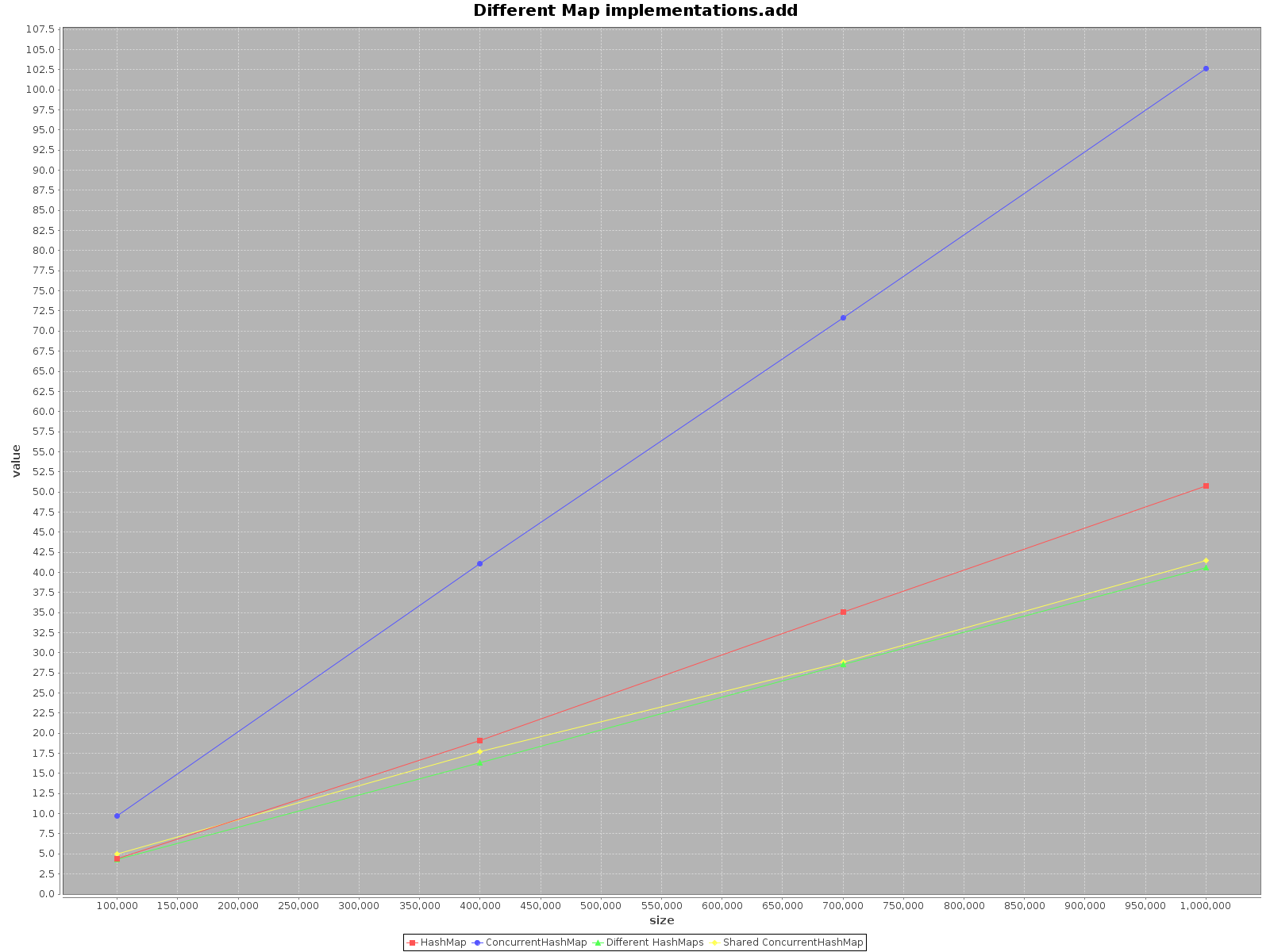
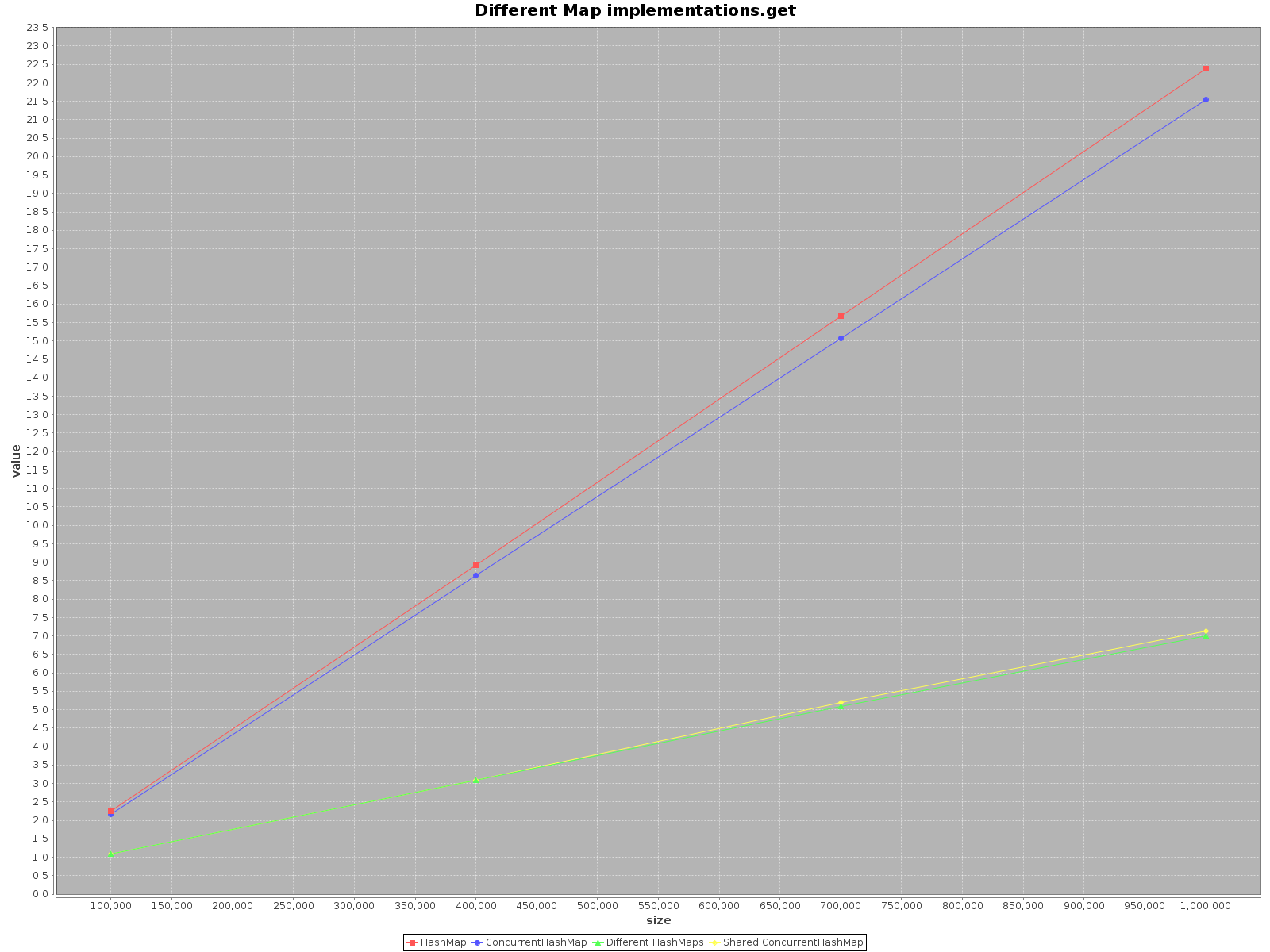
в резюме
если вы хотите работать с вашими данными как можно быстрее, используйте все доступные потоки. Это кажется очевидным, каждый поток имеет 1/nth полной работы, чтобы сделать.
если вы выбираете один поток доступа использовать
HashMap, это просто быстрее. Ибоaddметод это даже в 3 раза эффективнее. ТолькоgetбыстрееConcurrentHashMap, но не сильно.работая на
ConcurrentHashMapС многие потоки он аналогично эффективен для работы на отдельныхHashMapsдля каждого потока. Таким образом, нет необходимости разделять данные в разных структурах.подводя итог, производительность
ConcurrentHashMapхуже, когда вы используете с одним потоком, но добавление большего количества потоков для выполнения работы, безусловно, ускорит процесс.платформа для тестирования
AMD FX6100, 16GB Ram
Xubuntu 16.04, Oracle JDK 8 update 91, Scala 2.11.8
потокобезопасность-это сложный вопрос. Если вы хотите сделать объект потокобезопасным, сделайте это сознательно и задокументируйте этот выбор. Люди, которые используют ваш класс, будут благодарны вам, если он является потокобезопасным, когда он упрощает их использование, но они будут проклинать вас, если объект, который когда-то был потокобезопасным, станет не таким в будущей версии. Потокобезопасность, в то время как действительно приятно, не только на Рождество!
Итак, теперь к вашему вопросу:
ConcurrentHashMap (по крайней мере в солнечное текущая реализация) работает путем деления базовой карты на несколько отдельных ведер. Получение элемента не требует никакой блокировки как таковой, но он использует атомарные/летучие операции, что подразумевает барьер памяти (потенциально очень дорогостоящий и мешающий другим возможным оптимизациям).
даже если все накладные расходы атомарных операций могут быть устранены JIT-компилятором в однопоточном случае, все равно есть накладные расходы на решение, какой из ведра заглядывать - надо признать, это относительно быстрый расчет, но тем не менее, устранить его невозможно.
Что касается решения, какую реализацию использовать, выбор, вероятно, прост.
Если это статическое поле, вы почти наверняка хотите использовать ConcurrentHashMap, если тестирование не показывает, что это настоящий убийца производительности. Ваш класс имеет различные ожидания потокобезопасности от экземпляров этого класса.
Если это локальная переменная, тогда вероятность того, что хэш - карта достаточна-если вы не знаете, что ссылки на объект могут просочиться в другой поток. Кодируя интерфейс карты, вы позволяете себе легко изменить его позже, если обнаружите проблему.
Если это поле экземпляра, и класс не был разработан, чтобы быть потокобезопасным, то документировать его как не потокобезопасный, и использовать HashMap.
Если вы знаете, что это поле экземпляра единственная причина, по которой класс не является потокобезопасным, и желая жить с ограничениями, которые подразумевает многообещающая потокобезопасность, затем используйте ConcurrentHashMap, если тестирование не показывает значительных последствий для производительности. В этом случае вы можете разрешить пользователю класса каким-либо образом выбрать потокобезопасную версию объекта, возможно, используя другой метод фабрики.
в любом случае, документируйте класс как потокобезопасный (или условно потокобезопасный), чтобы люди, которые используют ваш класс, знали, что они могут использовать объекты по всему несколько потоков, и люди, которые редактируют ваш класс, знают, что они должны поддерживать потокобезопасность в будущем.
Я бы рекомендовал вам измерить его, так как (по одной причине) там мая будет некоторая зависимость от распределения хэширования конкретных объектов, которые вы храните.
стандартная hashmap не обеспечивает защиту от параллелизма, в то время как параллельная hashmap делает. Прежде чем он был доступен, вы могли обернуть hashmap, чтобы получить потокобезопасный доступ, но это была грубая блокировка зерна и означало, что весь параллельный доступ был сериализован, что действительно могло повлиять на производительность.
параллельное хранилище HashMap использует блокировки для зачистки и только замки предметов, что влияет на тот или иной замок. Если вы работаете на современной виртуальной машине, такой как hotspot, виртуальная машина попытается использовать блокировку смещение, огрубение и эллисация, если это возможно, поэтому вы будете платить штраф за замки только тогда, когда вам это действительно нужно.
таким образом, если ваша карта будет доступна параллельными потоками, и вам нужно гарантировать согласованное представление ее состояния, используйте параллельную хэш-карту.
в случае хэш-таблицы 1000 элементов использование 10 блокировок для всей таблицы экономит почти половину времени, когда 10000 потоков вставляются и 10000 потоков удаляются из нее.
интересная разница во времени выполнения здесь
всегда используйте параллельную структуру данных. за исключением случаев, когда обратная сторона чередования (упомянутая ниже) становится частой операцией. В таком случае вам придется приобрести все замки? Я читал, что лучшие способы сделать это - рекурсия.
чередование блокировок полезно, когда есть способ разбить блокировку с высокой конкуренцией на несколько блокировок Без ущерба для целостности данных. Если это возможно или нет, следует подумать и это не всегда так. Структура данных также является фактором, способствующим принятию решения. Поэтому, если мы используем большой массив для реализации хэш-таблицы, использование одной блокировки для всей хэш-таблицы для синхронизации приведет к последовательному доступу потоков к данным структура. Если это то же самое место в хэш-таблице, то это необходимо, но что делать, если они обращаются к двум крайностям таблицы.
нижняя сторона чередования блокировки-это трудно получить состояние структуры данных, на которое влияет чередование. В примере размер таблицы или попытка перечислить / перечислить всю таблицу может быть громоздкой, так как нам нужно получить все полосатые блокировки.
какой ответ вы ожидаете здесь?
Это очевидно, будет зависеть по количеству читает происходящее в то же время как пишет и как долго нормальная карта должна быть "заблокирована" на операции записи в вашем приложении (и будете ли вы использовать
putIfAbsentметод onConcurrentMap). Любой Эталон будет в значительной степени бессмысленным.
непонятно, что вы имеете в виду. Если вам нужна потокобезопасность, у вас почти нет выбора - только ConcurrentHashMap. И это определенно имеет штрафы за производительность / память в get () call - доступ к изменчивым переменным и блокировку, если вам не повезло.
Comments