Анализ Использования Индекса PostgreSQL
есть ли инструмент или метод для анализа Postgres и определения того, какие отсутствующие индексы должны быть созданы, а какие неиспользуемые индексы должны быть удалены? У меня есть небольшой опыт работы с инструментом "профилировщик" для SQLServer, но я не знаю о подобном инструменте, включенном в Postgres.
8 ответов:
Мне нравится это, чтобы найти недостающие индексы:
SELECT relname AS TableName, to_char(seq_scan, '999,999,999,999') AS TotalSeqScan, to_char(idx_scan, '999,999,999,999') AS TotalIndexScan, to_char(n_live_tup, '999,999,999,999') AS TableRows, pg_size_pretty(pg_relation_size(relname :: regclass)) AS TableSize FROM pg_stat_all_tables WHERE schemaname = 'public' AND 50 * seq_scan > idx_scan -- more then 2% AND n_live_tup > 10000 AND pg_relation_size(relname :: regclass) > 5000000 ORDER BY relname ASC;это проверяет, есть ли больше последовательных сканирований, чем индексных сканирований. Если таблица мала, она игнорируется, так как Postgres, похоже, предпочитает сканирование последовательности для них.
выше запрос показывает недостающие индексы.
следующим шагом будет обнаружение отсутствующих комбинированных индексов. Я думаю, это не просто, но выполнимо. Может быть, анализируя медленные запросы ... Я слышал pg_stat_statements может помощь...
проверить статистику.
pg_stat_user_tablesиpg_stat_user_indexes- те начать с.в разделе "Статистический Сборник".
на подходе определения отсутствующих индексов....Нет. Но есть некоторые планы сделать это проще в будущем выпуске, например, псевдо-индексы и машиночитаемые объяснения.
в настоящее время, вам потребуется
EXPLAIN ANALYZEплохое выполнение запросов, а затем вручную определить лучший маршрут. Некоторые лог-анализаторы любят pgFouine может помочь определить запросы.что касается неиспользуемого индекса, вы можете использовать что-то вроде следующего, чтобы помочь идентифицировать они:
select * from pg_stat_all_indexes where schemaname <> 'pg_catalog';Это поможет идентифицировать кортежи читать, сканировать, извлекать.
еще один новый и интересный инструмент для анализа PostgreSQL-это PgHero. Он больше ориентирован на настройку базы данных и делает многочисленные анализы и предложения.
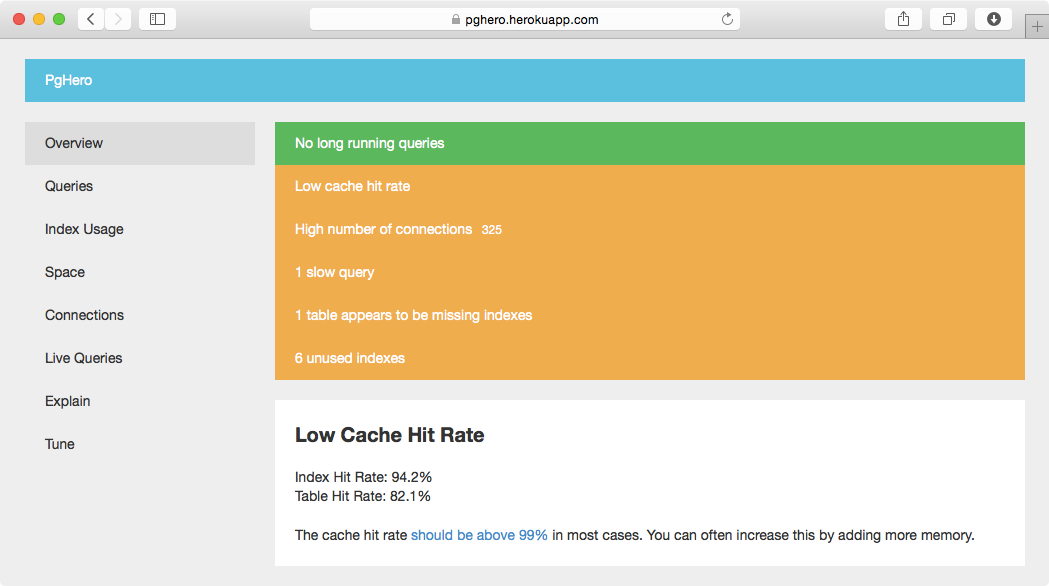
есть несколько ссылок на скрипты, которые помогут вам найти неиспользуемые индексы на PostgreSQL wiki. Основная техника заключается в том, чтобы смотреть на
pg_stat_user_indexesи искать те, гдеidx_scan, количество раз, когда этот индекс использовался для ответа на запросы, равно нулю или, по крайней мере, очень низко. Если приложение изменилось и ранее используемый индекс, вероятно, не сейчас, вам иногда приходится запускатьpg_stat_reset()чтобы получить всю статистику до 0, а затем собирать новые данные, вы можете сохранить текущие значения для всего и вычислить дельту вместо того, чтобы выяснить это.пока нет никаких хороших инструментов, чтобы предложить отсутствующие индексы. Один из подходов состоит в том, чтобы регистрировать выполняемые запросы и анализировать, какие из них занимают много времени, используя инструмент анализа журнала запросов, такой как pgFouine или pqa. Смотрите "Ведение Журнала Сложных Запросов" для получения дополнительной информации.
другой подход-посмотреть
pg_stat_user_tablesи посмотрите на таблицы, которые имеют большое количество последовательное сканирование против них, гдеseq_tup_fetchбольшой. Когда индекс используетсяidx_fetch_tupколичество увеличивается вместо этого. Что можно узнать, когда таблица не индексируется достаточно хорошо, чтобы ответить на запросы.на самом деле выяснить, какие столбцы вы должны затем индексировать? Обычно это снова приводит к анализу журнала запросов.
вы можете использовать ниже запрос, чтобы найти использование индекса и размер индекса:
SELECT pt.tablename AS TableName ,t.indexname AS IndexName ,to_char(pc.reltuples, '999,999,999,999') AS TotalRows ,pg_size_pretty(pg_relation_size(quote_ident(pt.tablename)::text)) AS TableSize ,pg_size_pretty(pg_relation_size(quote_ident(t.indexrelname)::text)) AS IndexSize ,to_char(t.idx_scan, '999,999,999,999') AS TotalNumberOfScan ,to_char(t.idx_tup_read, '999,999,999,999') AS TotalTupleRead ,to_char(t.idx_tup_fetch, '999,999,999,999') AS TotalTupleFetched FROM pg_tables AS pt LEFT OUTER JOIN pg_class AS pc ON pt.tablename=pc.relname LEFT OUTER JOIN ( SELECT pc.relname AS TableName ,pc2.relname AS IndexName ,psai.idx_scan ,psai.idx_tup_read ,psai.idx_tup_fetch ,psai.indexrelname FROM pg_index AS pi JOIN pg_class AS pc ON pc.oid = pi.indrelid JOIN pg_class AS pc2 ON pc2.oid = pi.indexrelid JOIN pg_stat_all_indexes AS psai ON pi.indexrelid = psai.indexrelid )AS T ON pt.tablename = T.TableName WHERE pt.schemaname='public' ORDER BY 1;
PoWA кажется интересным инструментом для PostgreSQL 9.4+. Он собирает статистику, визуализирует ее и предлагает индексы. Он использует
pg_stat_statements
Это должно помочь: Практический Анализ Запросов
Comments