Регрессия хребта с "glmnet" дает другие коэффициенты, чем то, что я вычисляю по "определению учебника"?
Я выполняю регрессию гребня с использованием glmnet R пакет. Я заметил, что коэффициенты, которые я получаю из функции glmnet::glmnet, отличаются от тех, которые я получаю, вычисляя коэффициенты по определению (с использованием того же лямбда-значения). Может кто-нибудь объяснить мне почему?
Данные (как ответ Y, так и матрица проектирования X) масштабируются.
library(MASS)
library(glmnet)
# Data dimensions
p.tmp <- 100
n.tmp <- 100
# Data objects
set.seed(1)
X <- scale(mvrnorm(n.tmp, mu = rep(0, p.tmp), Sigma = diag(p.tmp)))
beta <- rep(0, p.tmp)
beta[sample(1:p.tmp, 10, replace = FALSE)] <- 10
Y.true <- X %*% beta
Y <- scale(Y.true + matrix(rnorm(n.tmp))) # Y.true + Gaussian noise
# Run glmnet
ridge.fit.cv <- cv.glmnet(X, Y, alpha = 0)
ridge.fit.lambda <- ridge.fit.cv$lambda.1se
# Extract coefficient values for lambda.1se (without intercept)
ridge.coef <- (coef(ridge.fit.cv, s = ridge.fit.lambda))[2:(p.tmp+1)]
# Get coefficients "by definition"
ridge.coef.DEF <- solve(t(X) %*% X + ridge.fit.lambda * diag(p.tmp)) %*% t(X) %*% Y
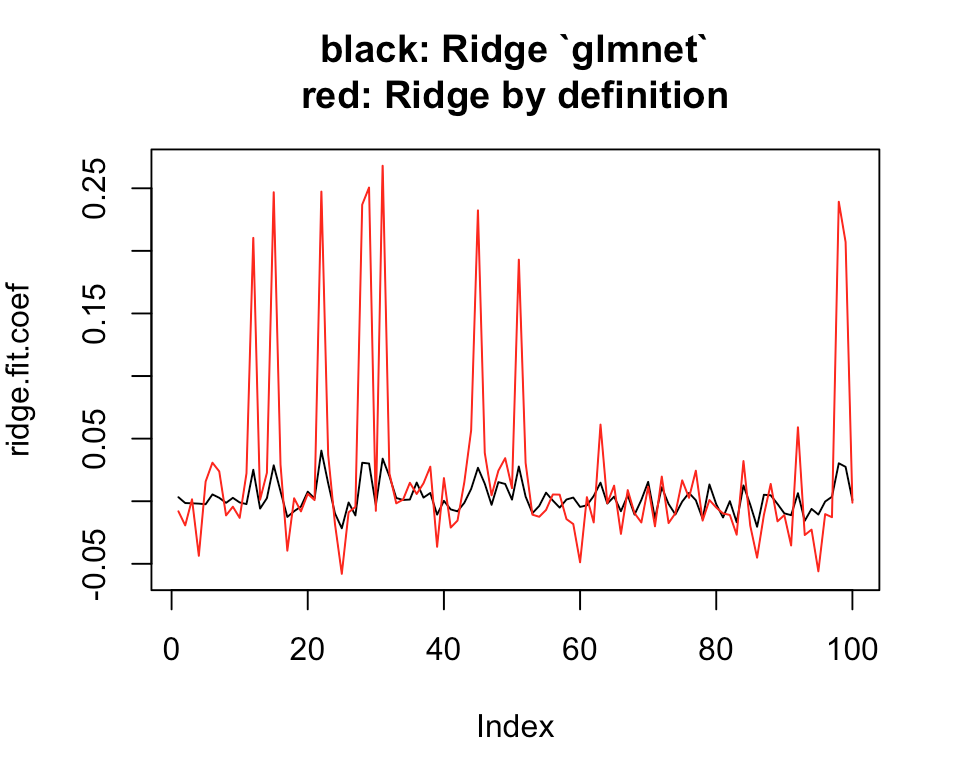
# Plot estimates
plot(ridge.coef, type = "l", ylim = range(c(ridge.coef, ridge.coef.DEF)),
main = "black: Ridge `glmnet`nred: Ridge by definition")
lines(ridge.coef.DEF, col = "red")
2 ответов:
Если вы прочтете
?glmnet, то увидите, что штрафная целевая функция гауссовского отклика равна:1/2 * RSS / nobs + lambda * penaltyВ случае использования штрафа хребта
1/2 * ||beta_j||_2^2, мы имеем1/2 * RSS / nobs + 1/2 * lambda * ||beta_j||_2^2Которая пропорциональна
RSS + lambda * nobs * ||beta_j||_2^2Это отличается от того, что мы обычно видим в учебнике по регрессии хребта:
RSS + lambda * ||beta_j||_2^2Формула, которую вы пишете:
##solve(t(X) %*% X + ridge.fit.lambda * diag(p.tmp)) %*% t(X) %*% Y drop(solve(crossprod(X) + diag(ridge.fit.lambda, p.tmp), crossprod(X, Y)))- это результат учебника; для
glmnetмы должны ожидать:##solve(t(X) %*% X + n.tmp * ridge.fit.lambda * diag(p.tmp)) %*% t(X) %*% Y drop(solve(crossprod(X) + diag(n.tmp * ridge.fit.lambda, p.tmp), crossprod(X, Y)))Итак, учебник использует штрафные наименьшие квадраты , но
glmnetиспользуетштрафную среднеквадратичную ошибку .Обратите внимание, что я не использовал ваш исходный код с
t(),"%*%"иsolve(A) %*% b; Использованиеcrossprodиsolve(A, b)более эффективно! См.разделПоследующие действия в конце.
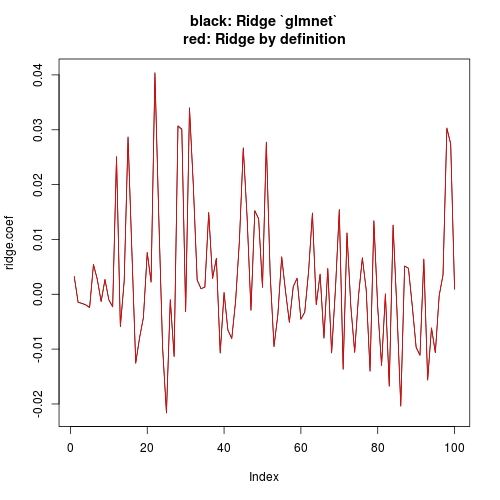
Теперь давайте сделаем новое сравнение:library(MASS) library(glmnet) # Data dimensions p.tmp <- 100 n.tmp <- 100 # Data objects set.seed(1) X <- scale(mvrnorm(n.tmp, mu = rep(0, p.tmp), Sigma = diag(p.tmp))) beta <- rep(0, p.tmp) beta[sample(1:p.tmp, 10, replace = FALSE)] <- 10 Y.true <- X %*% beta Y <- scale(Y.true + matrix(rnorm(n.tmp))) # Run glmnet ridge.fit.cv <- cv.glmnet(X, Y, alpha = 0, intercept = FALSE) ridge.fit.lambda <- ridge.fit.cv$lambda.1se # Extract coefficient values for lambda.1se (without intercept) ridge.coef <- (coef(ridge.fit.cv, s = ridge.fit.lambda))[-1] # Get coefficients "by definition" ridge.coef.DEF <- drop(solve(crossprod(X) + diag(n.tmp * ridge.fit.lambda, p.tmp), crossprod(X, Y))) # Plot estimates plot(ridge.coef, type = "l", ylim = range(c(ridge.coef, ridge.coef.DEF)), main = "black: Ridge `glmnet`\nred: Ridge by definition") lines(ridge.coef.DEF, col = "red")Обратите внимание, что я установил
intercept = FALSE, когда я вызываюcv.glmnet(илиglmnet). Это имеет больше концептуального значения, чем то, на что это повлияет в будущем. практика. Концептуально, наше учебное вычисление не имеет перехвата, поэтому мы хотим отбросить перехват при использованииglmnet. Но практически, поскольку вашиXиYстандартизированы, теоретическая оценка перехвата равна 0. Даже сintercepte = TRUE(glmentdefault), вы можете проверить, что оценка перехвата равна~e-17(численно 0), следовательно, оценка других коэффициентов существенно не влияет. Другой ответ просто показывает это.
Последующие действия
Как для использования
crossprodиsolve(A, b)- интересно! У вас случайно нет ссылки на сравнение моделирования для этого?
t(X) %*% Yсначала возьмем транспонированиеX1 <- t(X), затем сделаемX1 %*% Y, В то время какcrossprod(X, Y)не будем делать транспонирование."%*%"является оберткой дляDGEMMдля случаяop(A) = A, op(B) = B, в то время какcrossprodявляется оболочкой дляop(A) = A', op(B) = B. Аналогичноtcrossprodдляop(A) = A, op(B) = B'.Основное использование
crossprod(X)- дляt(X) %*% X; аналогичноtcrossprod(X)дляX %*% t(X), в этом случаеDSYRKвместоDGEMMпризванный. Вы можете прочитать первый раздел из почему встроенная функция lm так медленно работает в R? для разума и ориентира.Имейте в виду, что если
Xне является квадратной матрицей,crossprod(X)иtcrossprod(X)не одинаково быстры, поскольку они включают различное количество операций с плавающей запятой, для которых вы можете прочитать боковое уведомление любой более быстрой функции R, чем "tcrossprod" для симметричного умножения плотной матрицы?Относительно
solvel(A, b)иsolve(A) %*% b, пожалуйста, прочитайте первый раздел из как вычислить diag(X %% solve(A) %% t(X)) эффективно, не принимая матрицу обратной?
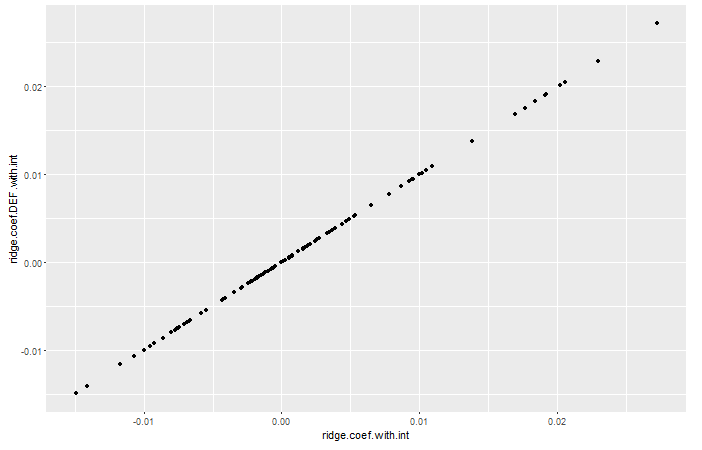
Добавив к интересному сообщению Чжэюаня еще несколько экспериментов, чтобы увидеть, что мы можем получить те же результаты и с перехватом, а именно:
# ridge with intercept glmnet ridge.fit.cv.int <- cv.glmnet(X, Y, alpha = 0, intercept = TRUE, family="gaussian") ridge.fit.lambda.int <- ridge.fit.cv.int$lambda.1se ridge.coef.with.int <- as.vector(as.matrix(coef(ridge.fit.cv.int, s = ridge.fit.lambda.int))) # ridge with intercept definition, use the same lambda obtained with cv from glmnet X.with.int <- cbind(1, X) ridge.coef.DEF.with.int <- drop(solve(crossprod(X.with.int) + ridge.fit.lambda.int * diag(n.tmp, p.tmp+1), crossprod(X.with.int, Y))) ggplot() + geom_point(aes(ridge.coef.with.int, ridge.coef.DEF.with.int))
# comupte residuals RSS.fit.cv.int <- sum((Y.true - predict(ridge.fit.cv.int, newx=X))^2) # predict adds inter RSS.DEF.int <- sum((Y.true - X.with.int %*% ridge.coef.DEF.with.int)^2) RSS.fit.cv.int [1] 110059.9 RSS.DEF.int [1] 110063.4
Comments