Удалить дубликат dict в списке в Python
у меня есть список диктов, и я хотел бы удалить дикты с одинаковыми парами ключей и значений.
для этого: [{'a': 123}, {'b': 123}, {'a': 123}]
Я хотел бы вернуть это:[{'a': 123}, {'b': 123}]
еще пример:
для этого: [{'a': 123, 'b': 1234}, {'a': 3222, 'b': 1234}, {'a': 123, 'b': 1234}]
Я хотел бы вернуть это:[{'a': 123, 'b': 1234}, {'a': 3222, 'b': 1234}]
9 ответов:
попробуйте это:
[dict(t) for t in {tuple(d.items()) for d in l}]стратегия заключается в преобразовании списка словарей в список кортежей, где кортежи содержат элементы словаря. Поскольку кортежи могут быть хэшированы, вы можете удалить дубликаты с помощью
set(через установить понимание здесь более старая альтернатива python будетset(tuple(d.items()) for d in l)) и, после этого, воссоздать словари из кортежей сdict.где:
lоригинал списокdодин из словарей в спискеtявляется одним из кортежей, созданных из словаряEdit: если вы хотите сохранить заказ, один лайнер выше не будет работать с
setне будет этого делать. Однако, с помощью нескольких строк кода, Вы также можете сделать это:l = [{'a': 123, 'b': 1234}, {'a': 3222, 'b': 1234}, {'a': 123, 'b': 1234}] seen = set() new_l = [] for d in l: t = tuple(d.items()) if t not in seen: seen.add(t) new_l.append(d) print new_lпример:
[{'a': 123, 'b': 1234}, {'a': 3222, 'b': 1234}]Примечание: как указал @alexis может случиться, что два словаря с одинаковыми ключами и значения, не приводят к тому же кортежу. Это может произойти, если они пройдут через другую историю добавления/удаления ключей. Если это так для вашей проблемы, то рассмотрите сортировку
d.items()как он и предлагает.
еще один однострочный на основе списка понимания:
>>> d = [{'a': 123}, {'b': 123}, {'a': 123}] >>> [i for n, i in enumerate(d) if i not in d[n + 1:]] [{'b': 123}, {'a': 123}]здесь, так как мы можем использовать
dictсравнение, мы сохраняем только те элементы, которые не находятся в остальной части исходного списка (это понятие доступно только через индексn, следовательно, использованиеenumerate).
иногда старые циклы все еще полезны. Этот код немного длиннее, чем у jcollado, но очень легко читается:
a = [{'a': 123}, {'b': 123}, {'a': 123}] b = [] for i in range(0, len(a)): if a[i] not in a[i+1:]: b.append(a[i])
другие ответы не будут работать, если вы работаете с вложенными словарями, такими как десериализованные объекты JSON. В этом случае вы можете использовать:
import json set_of_jsons = {json.dumps(d, sort_keys=True) for d in X} X = [json.loads(t) for t in set_of_jsons]
Если вы хотите сохранить заказ, то вы можете сделать
from collections import OrderedDict print OrderedDict((frozenset(item.items()),item) for item in data).values() # [{'a': 123, 'b': 1234}, {'a': 3222, 'b': 1234}]Если порядок не имеет значения, то вы можете сделать
print {frozenset(item.items()):item for item in data}.values() # [{'a': 3222, 'b': 1234}, {'a': 123, 'b': 1234}]
не универсальный ответ, но если ваш список окажется отсортированный каким-то ключом, вот так:
l=[{'a': {'b': 31}, 't': 1}, {'a': {'b': 31}, 't': 1}, {'a': {'b': 145}, 't': 2}, {'a': {'b': 25231}, 't': 2}, {'a': {'b': 25231}, 't': 2}, {'a': {'b': 25231}, 't': 2}, {'a': {'b': 112}, 't': 3}]тогда решение так же просто, как:
import itertools result = [a[0] for a in itertools.groupby(l)]результат:
[{'a': {'b': 31}, 't': 1}, {'a': {'b': 145}, 't': 2}, {'a': {'b': 25231}, 't': 2}, {'a': {'b': 112}, 't': 3}]работает с вложенными словарями и (очевидно) сохраняет порядок.
вы можете использовать набор, но вам нужно повернуть предсказывает в тип hashable.
seq = [{'a': 123, 'b': 1234}, {'a': 3222, 'b': 1234}, {'a': 123, 'b': 1234}] unique = set() for d in seq: t = tuple(d.iteritems()) unique.add(t)Unique теперь равно
set([(('a', 3222), ('b', 1234)), (('a', 123), ('b', 1234))])чтобы вернуть диктовку:
[dict(x) for x in unique]
если использование стороннего пакета будет в порядке, то вы можете использовать
iteration_utilities.unique_everseen:>>> from iteration_utilities import unique_everseen >>> l = [{'a': 123}, {'b': 123}, {'a': 123}] >>> list(unique_everseen(l)) [{'a': 123}, {'b': 123}]он сохраняет порядок исходного списка, и ut также может обрабатывать недоступные элементы, такие как словари, возвращаясь к более медленному алгоритму (
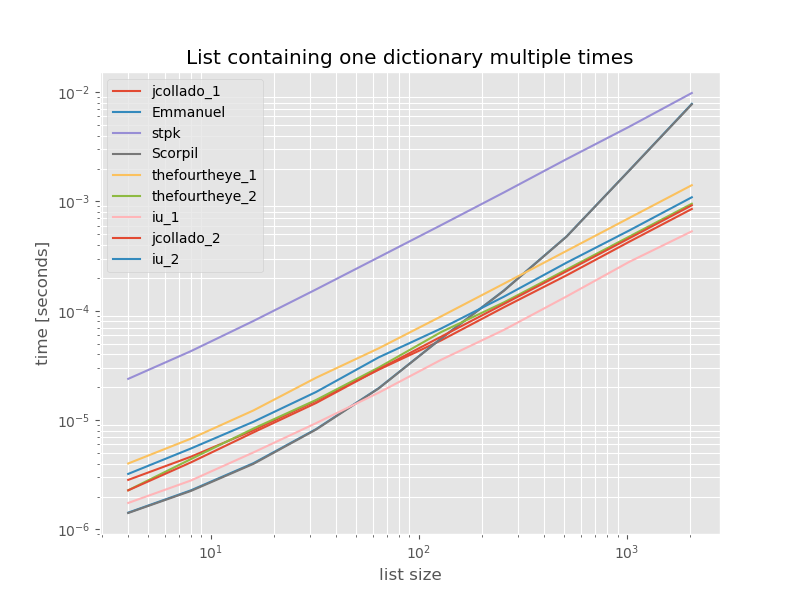
O(n*m)здесьnэлементы в исходном списке иmуникальные элементы в исходном списке вместоO(n)). В случае, если оба ключа и значения хэшируются, вы можете использовать на втором месте, однако это самый быстрый подход, который сохраняет порядок. Другой подходы от jcollado и thefourtheye почти так же быстро. Подход с использованиемunique_everseenбез ключа и решения от Эммануэль и Scorpil очень медленно для более длинных списков и ведут себя гораздо хужеO(n*n)вместоO(n). стпкs подход сjsonнеO(n*n)но это гораздо медленнее, чем аналогичныеO(n)подходы.код для воспроизведения контрольные показатели:
from simple_benchmark import benchmark import json from collections import OrderedDict from iteration_utilities import unique_everseen def jcollado_1(l): return [dict(t) for t in {tuple(d.items()) for d in l}] def jcollado_2(l): seen = set() new_l = [] for d in l: t = tuple(d.items()) if t not in seen: seen.add(t) new_l.append(d) return new_l def Emmanuel(d): return [i for n, i in enumerate(d) if i not in d[n + 1:]] def Scorpil(a): b = [] for i in range(0, len(a)): if a[i] not in a[i+1:]: b.append(a[i]) def stpk(X): set_of_jsons = {json.dumps(d, sort_keys=True) for d in X} return [json.loads(t) for t in set_of_jsons] def thefourtheye_1(data): return OrderedDict((frozenset(item.items()),item) for item in data).values() def thefourtheye_2(data): return {frozenset(item.items()):item for item in data}.values() def iu_1(l): return list(unique_everseen(l)) def iu_2(l): return list(unique_everseen(l, key=lambda inner_dict: frozenset(inner_dict.items()))) funcs = (jcollado_1, Emmanuel, stpk, Scorpil, thefourtheye_1, thefourtheye_2, iu_1, jcollado_2, iu_2) arguments = {2**i: [{'a': j} for j in range(2**i)] for i in range(2, 12)} b = benchmark(funcs, arguments, 'list size') %matplotlib widget import matplotlib as mpl import matplotlib.pyplot as plt plt.style.use('ggplot') mpl.rcParams['figure.figsize'] = '8, 6' b.plot(relative_to=thefourtheye_2)для полноты вот время для списка, содержащего только дубликаты:
# this is the only change for the benchmark arguments = {2**i: [{'a': 1} for j in range(2**i)] for i in range(2, 12)}
тайминги не меняются значительно, за исключением
unique_everseenбезkeyфункция, которая в этом случае является самым быстрым решением. Однако это просто лучший случай (поэтому не репрезентативный) для этой функции с недоступными значениями, потому что время выполнения зависит от количества уникальных значений в списке:O(n*m)который в данном случае просто 1 и таким образом он работает вO(n).
отказ от ответственности: я автор книги
iteration_utilities.
если вы используете Pandas в своем рабочем процессе, одним из вариантов является подача списка словарей непосредственно в
pd.DataFrameконструктор. Тогда используйтеdrop_duplicatesиto_dictметоды для требуемого результата.import pandas as pd d = [{'a': 123, 'b': 1234}, {'a': 3222, 'b': 1234}, {'a': 123, 'b': 1234}] d_unique = pd.DataFrame(d).drop_duplicates().to_dict('records') print(d_unique) [{'a': 123, 'b': 1234}, {'a': 3222, 'b': 1234}]
Comments